













AI狂飆70年背后原因大揭秘!時代周刊4張圖,揭露算法進化之謎
在過去的十年里,AI系統發展的速度令人驚嘆。
2016年AlphaGo在圍棋比賽中擊敗李世石,就是一個開始。現在,AI已經可以比人類更好地識別圖像和語音,通過商學院考試,以及亞馬遜的編程面試題。
就在上周,美國參議院司法委員會開展了關于監管AI的聽證會。
在會上,著名AI初創公司Anthropic的CEO Dario Amodei表示說:了解AI最重要的一件事,就是知道它的發展速度有多快。

最近,《時代周刊》就發了一篇文章,用四張圖告訴我們,AI的發展速度為什么不會放緩。
人類正在被AI超越
如今,AI在許多任務中超越了人類,人類在新任務中被超越的速度也在增加。
下圖是SOTA模型在基準測試上相對于人類的表現。
測試的能力分別是手寫識別(MNIST)、語音識別(Switchboard)、圖像識別(ImageNet)、閱讀理解(SQuAD 1.1 & SQuAD 2.0)、語言理解(GLUE)、常識完成(HellaSwag)、小學數學(GSK8k)、代碼生成(HumanEval)。
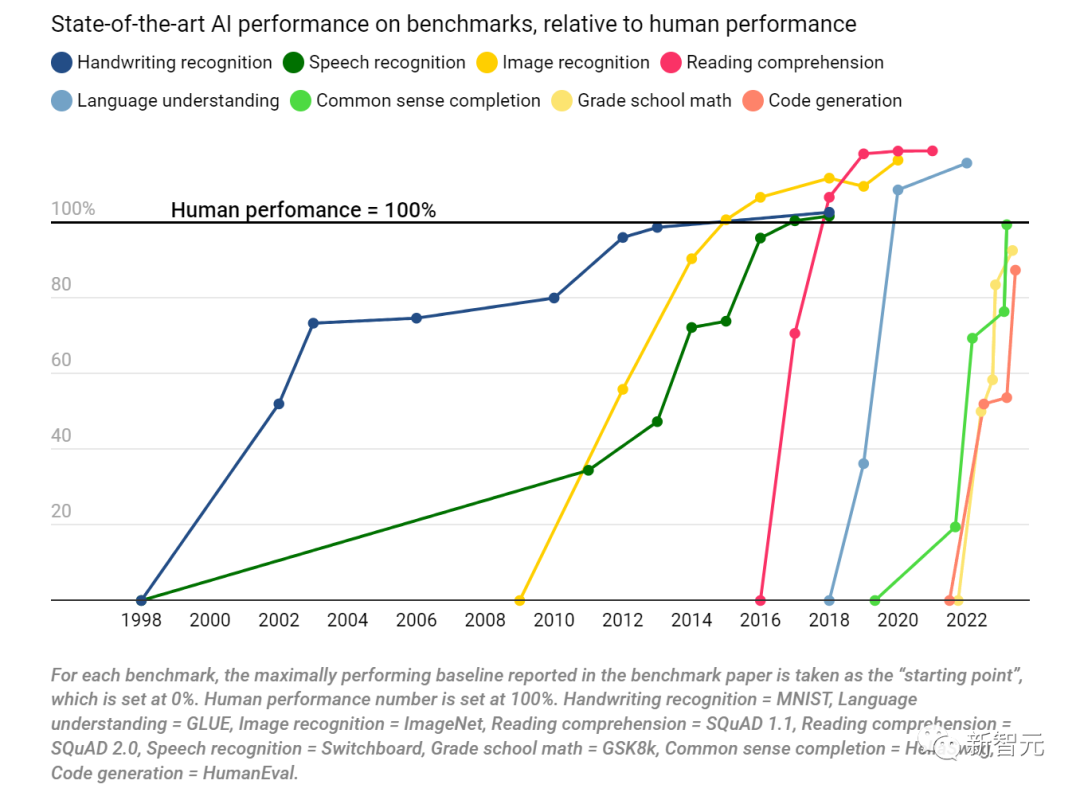
人類的表現被設定為100%
人們通常會認為,科學和技術進步在根本上是不可預測的,驅動它們的是一種在事后才變得更清晰的洞察力。
但我們可以預見,AI系統的進步是由三個輸入(計算、數據和算法)的進步推動的。
過去70年的大部分進步,都是研究人員使用更大的算力訓練AI系統的結果。
系統被提供了更多數據,或者存在更強的算法,有效地減少了獲得相同結果所需的計算或數據量。
只要了解這三個因素在過去是如何推動了人工智能的進步,我們就會理解為什么大多數AI從業者預計AI的進展不會放緩。
計算量的增加
第一個人工神經網絡Perceptron Mark I開發于1957年,它可以分辨一張卡片的標記是在左側還是右側。
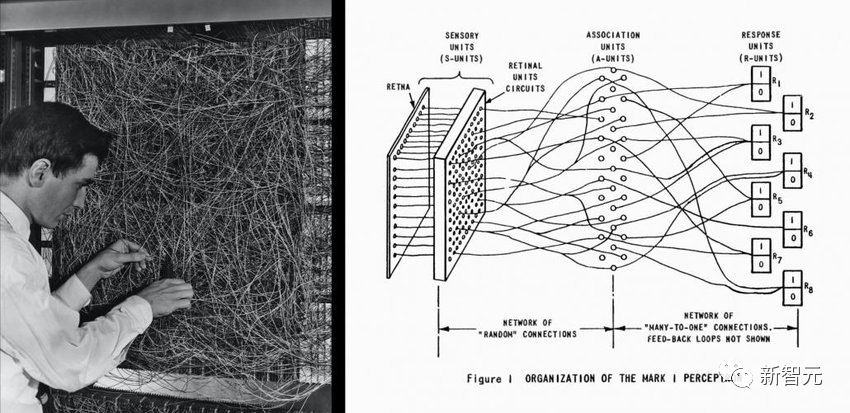
擁有1000個人工神經元的Mark I,訓練一次大概需要7x10^5次操作。
而70多年后OpenAI發布的大語言模型GPT-4,訓練一次大概需要21x10^24次操作。
計算量的增加,不僅讓AI系統可以從更多的數據中學到更多的示例,而且還可以更詳細地對變量之間的關系進行建模,從而得出更準確、更細致的結論。
自1965年以來,摩爾定律(集成電路中的晶體管數量大約每兩年翻一番)意味著算力的價格一直在穩步下降。
不過,研究機構Epoch的主任Jaime Sevilla表示,這時的研究人員更專注于開發構建AI系統的新技術,而不是關注使用多少計算來訓練這些系統。
然而,情況在2010年左右發生了變化——研究人員發現「訓練模型越大,表現效果越好」。
從那時起,他們便開始花費越來越多的資金,來訓練規模更大的模型。
訓練AI系統需要昂貴的專用芯片,開發者要么構建自己的計算基礎設施,要么向云計算服務商付費,訪問他們的基礎設施。

隨著這一支出的不斷增長,再加上摩爾定律帶來的成本下降,AI模型也能夠在越來越強大的算力上進行訓練。
據OpenAI CEO Sam Altman透露,GPT-4的訓練成本超過了1億美元。
作為業界的兩個頂流,OpenAI和Anthropic已經分別從投資者那里籌集了數十億美元,用于支付訓練AI系統的計算費用,并各自與財力雄厚的科技巨頭(微軟、谷歌)建立了合作伙伴關系。
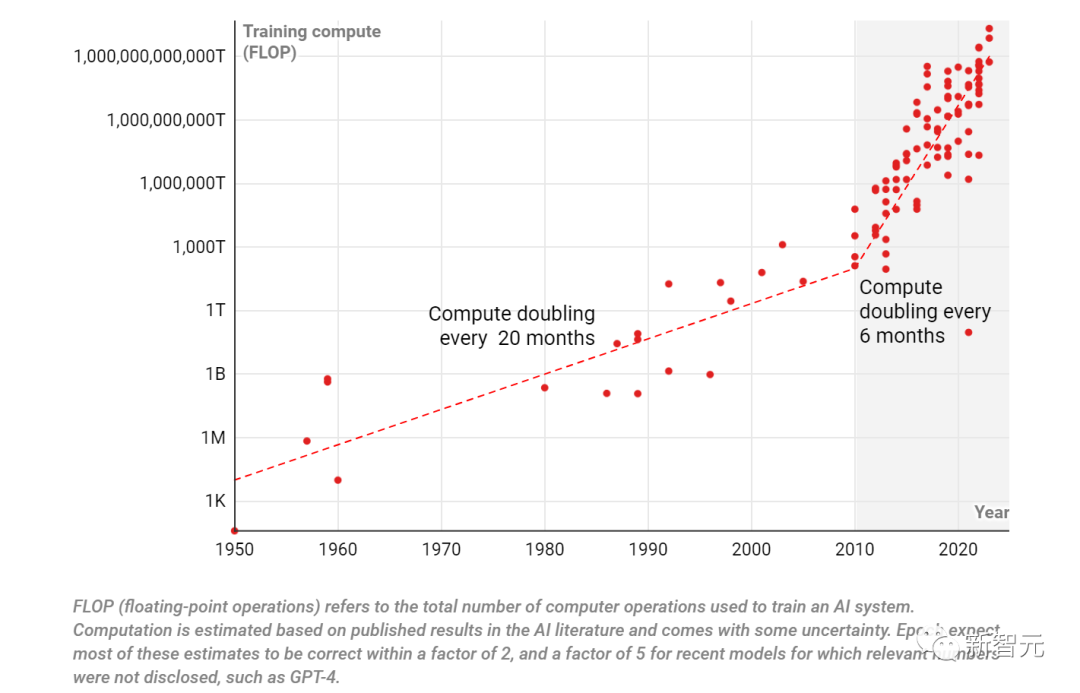
自1950年以來,用于訓練AI系統的計算量一直在增加;到2010年,增長率也增加了
數據量的增長
AI系統的工作原理是,構建訓練數據中變量之間的關系模型。
無論是單詞「home」與單詞「run」相鄰的可能性,還是基因序列與蛋白質折疊之間的模式,即蛋白質以其三維形態取得功能的過程。

一般來說,數據越多AI系統就有越多信息來建立數據中變量之間準確的關系模型,從而提高性能。
例如,一個被提供更多文本的語言模型將擁有更多以「run」跟隨「home」出現的句子示例。因為在描述棒球比賽或強調成功的句子中,這種詞序更為常見。
關于Perceptron Mark I的原始研究論文指出,它僅使用了六個數據點進行訓練。

論文地址:https://blogs.umass.edu/brain-wars/files/2016/03/rosenblatt-1957.pdf
相比之下,由Meta在2023年發布的大語言模型LLaMA,則使用了約10億個數據點進行訓練——比Perceptron Mark I增加了超過1.6億倍。
其中,這些數據包括,67%的Common Crawl數據,4.5%的GitHub,以及4.5%的維基百科。
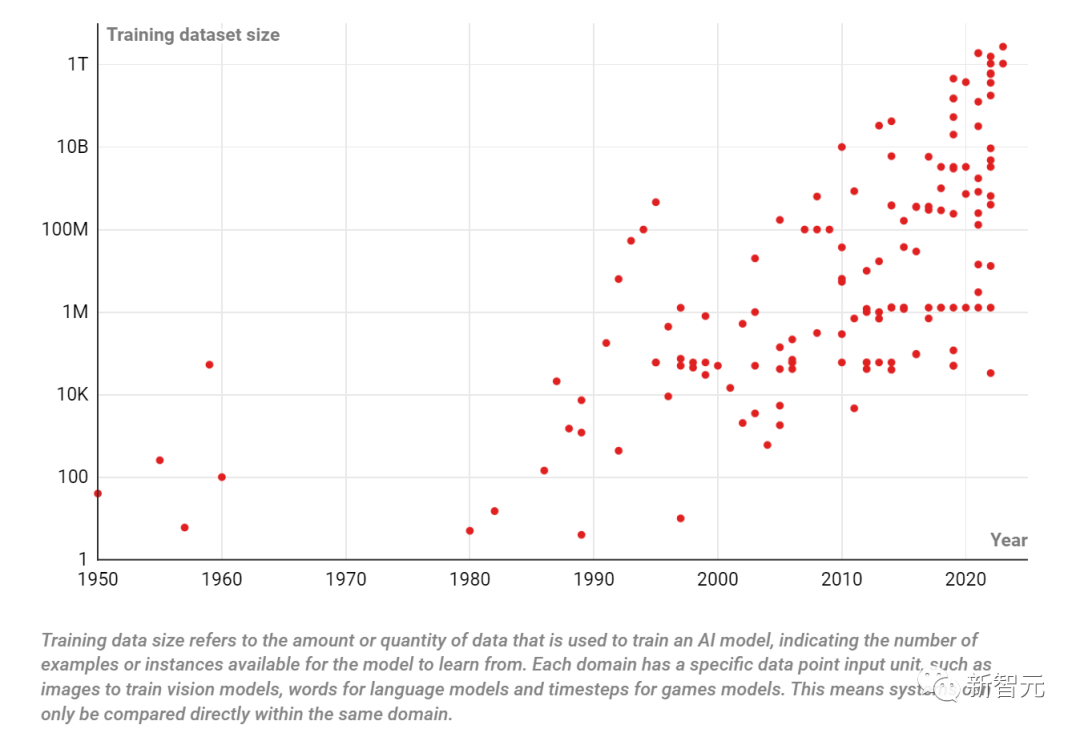
在過去的70年中,用于訓練AI模型的數據量急劇增加
訓練數據大小是指用于訓練AI模型的數據量,表示可供模型學習的示例數。
每個領域都有一個特定的數據點輸入單元,例如用于訓練視覺模型的圖像、用于語言模型的單詞,和用于游戲模型的時間步長。這意味著系統只能在同一領域內進行比較。
算法的進步
算法是定義要執行的操作序列的規則或指令集,它決定了AI系統如何準確地利用算力來建模給定的數據之間的關系。
除了使用越來越多的算力在更多數據上訓練AI之外,研究人員還在尋找在尋找如何用更少的資源獲得更多的效益。
Epoch的研究發現,「每九個月,更好的算法的引入,相當于讓計算預算翻番。」
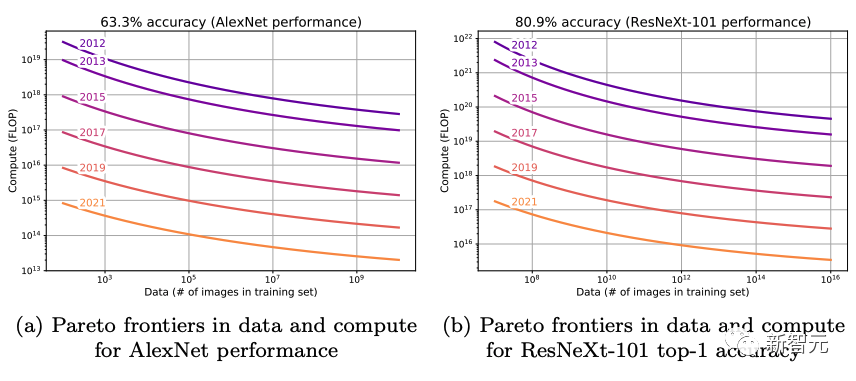
訓練模型的帕累托邊界,以實現知名模型隨時間推移的性能
而算法進步也就是意味著,模型可以憑借著更少的計算和數據,達到相同的性能水平。
下圖是在六個不同年份中,在圖像識別測試中達到80.9%的準確度所需的計算量和數據點數。
對于在1萬億個數據點上訓練的模型,2021年訓練的模型所需的計算量比2012年訓練的模型少~16,500倍。
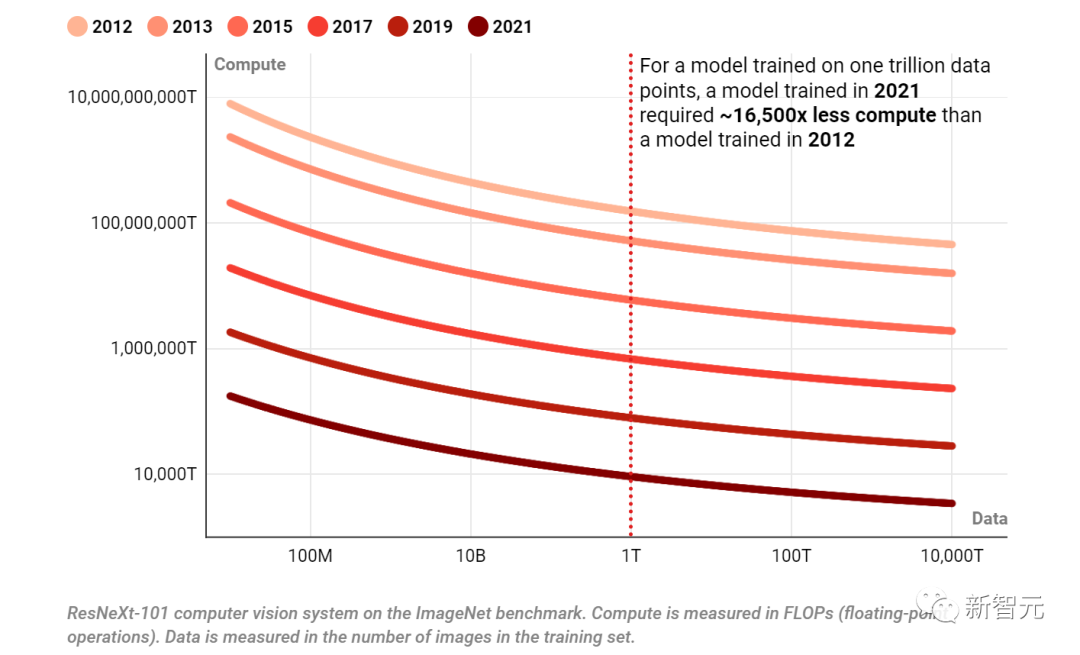
在圖像識別測試中,達到80.9%準確率所需的計算量和數據量
調查涉及的是ImageNet基準測試上的ResNeXt-101計算機視覺系統,計算以FLOP為單位,數據以訓練集中的圖像數量來衡量。
AI的下一個階段
根據Sevilla的預測,研究人員用于訓練系統的計算量很可能在一段時間內繼續以目前的加速度增長,企業在訓練AI系統上花費的資金也會增加,而隨著計算成本的持續下降,效率也會提高。
直到個時刻,繼續增加計算量只能略微提高性能為止。在此之后,計算量將繼續增加,但速度會放慢。而這完全是因為摩爾定律導致計算成本下降。
目前,AI系統(如 LLaMA)所使用的數據來自互聯網。在以往,能輸入AI系統多少數據量,主要取決于有多少算力。
而最近訓練AI系統所需的數據量的爆炸性增長,已經超過了互聯網上新文本數據的生產速度。
因此,Epoch預測,研究人員將在2026年用盡高質量的語言數據。
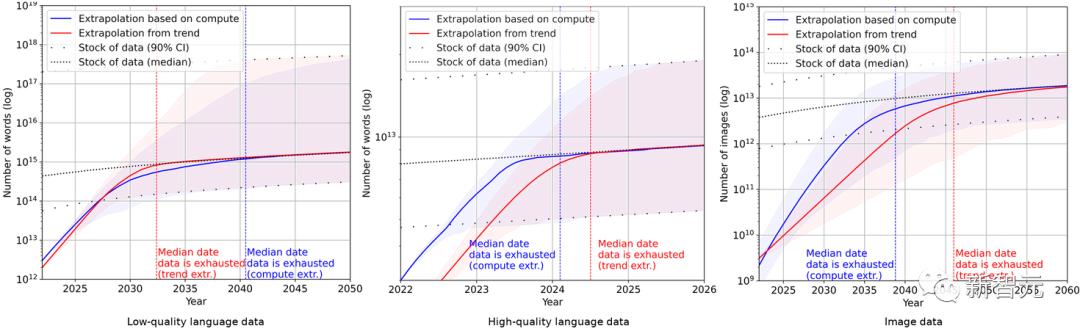
不過,開發AI系統的人對這個問題似乎不太擔心。
在3月份參加Lunar Society的播客節目時,OpenAI的首席科學家Ilya Sutskever表示:「我們的數據情況還不錯。還有很多可用的數據。」
在7月份參加Hard Fork播客節目時,Dario Amodei估計:「在數據不足的情況下,這種擴展可能有10%的幾率會受到影響。」
Sevilla也相信,數據的不足并不會阻止AI的進一步發展,例如找到使用低質量語言數據的方法。因為與計算不同,數據不足以前并沒有成為AI發展的瓶頸。
他預計,在創新方面,研究人員將很可能會發現很多簡單的方法來解決這個問題。
到目前為止,算法的大部分改進,都源于如何更高效地利用算力這一目標。Epoch發現,過去超過四分之三的算法進步,都是被用來彌補計算的不足。

未來,隨著數據成為AI訓練發展的瓶頸,可能會有更多的算法改進,被用來彌補數據上的不足。
綜合以上三個方面,包括Sevilla在內的專家們預計,AI進展將在未來幾年內繼續以驚人的速度進行。
計算量將繼續增加,因為公司投入更多資金,底層技術也變得更加便宜。
互聯網上剩余有用的數據將被用于訓練AI模型,研究人員將繼續找到訓練和運行AI系統的更高效方法,從而更好地利用算力和數據。
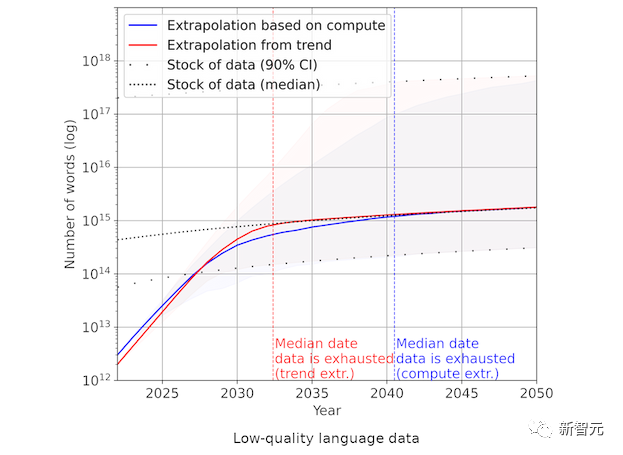
而AI在這些十年的發展趨勢,也將繼續延續下去。
當然,這種趨勢也讓很多AI專家感到擔憂。
在參議院委員會聽證會上,Anthropic CEO Amodei提出,如果AI再繼續進步下去,兩到三年內,普通人都可以獲得即使是專家也無法獲得的科學知識了。
這可能造成的網絡安全、核技術、化學、生物學等領域造成的嚴重破壞和濫用,誰都無法想象。

















