













GPT-4生圖未解禁?CMU華人博士新作,大模型GILL能生圖能檢索,人人可玩
GPT-4多模態能力恐怕是要再等等了。
近日,來自CMU的研究人員全新提出了一種多模態模型GILL。

論文地址:https://arxiv.org/pdf/2305.17216.pdf
它可以將文本或圖像作為prompt,完成多模態對話。具體來說,可以實現生成文本、檢索圖像、生成新圖像。
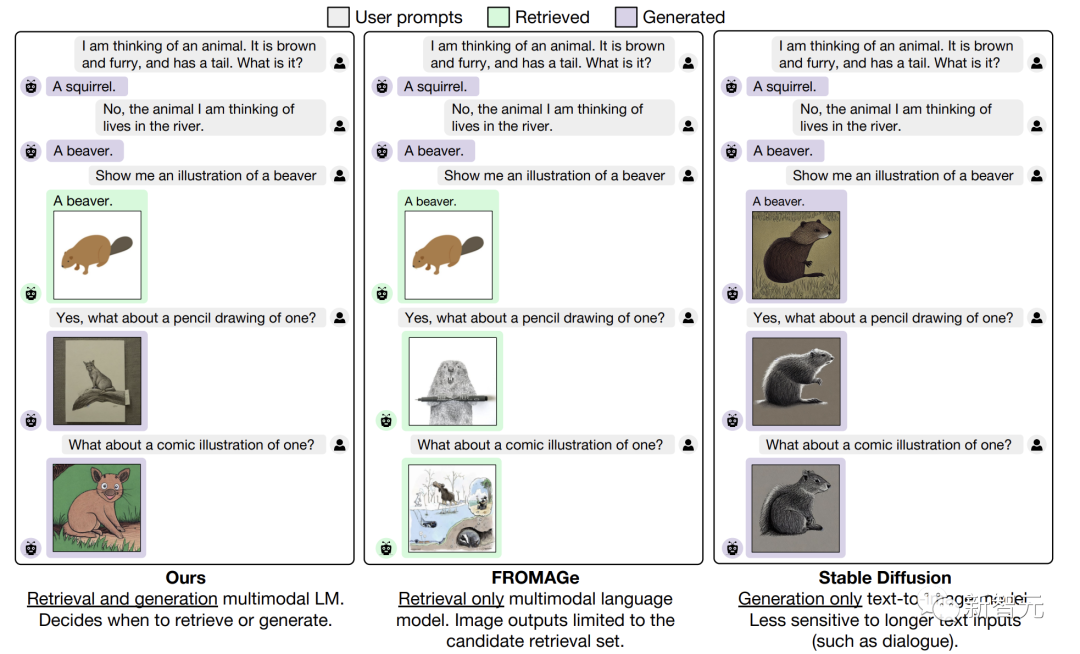
甚至,GILL還能從預先指定的數據集中進行圖像檢索,并在推理時決定是檢索還是生成。
值得一提的是,通過嵌入空間之間的映射,CMU團隊將凍結的大模型,與預訓練的文生圖模型相結合。
這樣一來,GILL就能夠實現廣泛的應用,并且在多個文本到圖像任務中優于基于Stable Diffusion等生成模型。
先來看一波演示。
演示
GILL能夠將LLM預訓練和凍結能力推廣到許多不同任務中。具體包括:
https://huggingface.co/spaces/jykoh/gill
多模態對話生成
你可以提示GILL生成類似對話的文本,可以做到圖像檢索、圖像生成,甚至多模態對話。
比如,你可以問它如何做拉面更有營養?GILL給出了加入蔬菜的建議。
我想要一款紋身。GILL瞬間就給你生成了符合要求的圖案。
如何在市場上宣傳這些蛋糕?GILL建議用一個簡單的標牌,上面附上企業名稱和小蛋糕的圖片。

從視覺故事生成圖像
另外,GILL還可以根據交錯的圖像和文本輸入來生成更相關的圖像。

多模態大模型GILL
GILL的全稱是:Generating Images with Large Language Models,即用大型語言模型生成圖像。
它能夠處理任意交錯的圖像和文本輸入,以生成文本、檢索圖像,和生成新圖像。
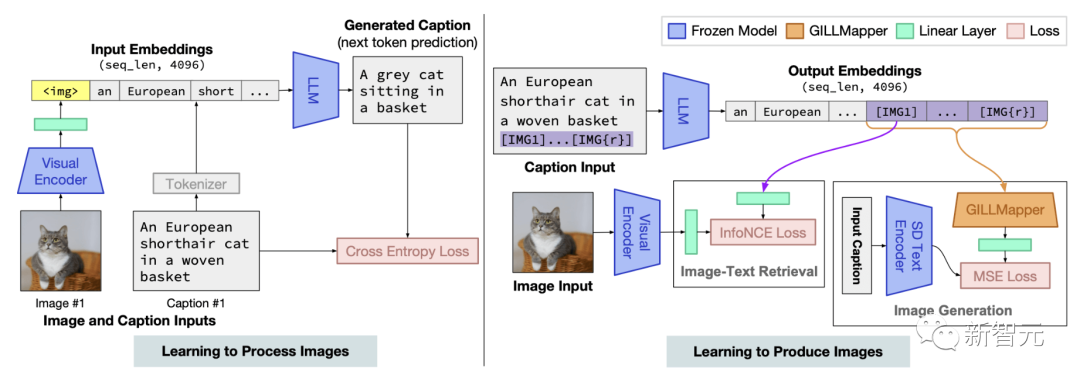
GILL模型架構概覽。通過描述損失進行訓練,以學習處理圖像(左),并通過圖像檢索和圖像生成損失進行訓練,以學習生成圖像(右)
研究表明,盡管2種模型使用完全不同的文本編碼器,但可以有效地將凍結的純文本LLM的輸出嵌入空間,映射到凍結文本-圖像生成模型,即Stable Diffusion的嵌入空間。
與其他需要交錯圖像-文本訓練數據的方法相比,研究人員通過微調圖像-描述對上的少量參數來實現這一點。
這個方法計算高效,并且不需要在訓練時運行圖像生成模型。
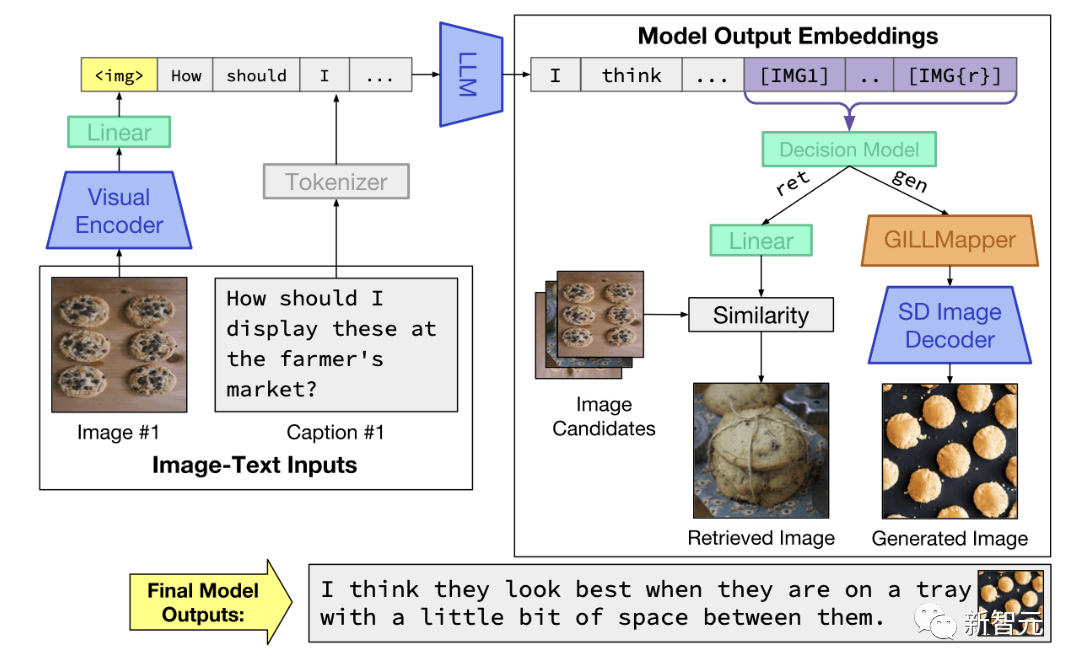
GILL的推理時間過程。該模型接受圖像和文本輸入,并生成與圖像嵌入交錯的文本。在決定是否檢索或生成特定的token集后,并返回適當的圖像輸出
在推理過程中,模型接受任意交錯的圖像和文本輸入,并產生與圖像嵌入交錯的文本。在決定是檢索還是生成一組特定的標記后,它返回適當的圖像輸出(檢索或生成)
在推理過程中,該模型接收任意交錯的圖像和文本輸入,并生成交錯圖像嵌入的文本。在決定是檢索還是生成一組特定的標記后,它會返回相應的圖像輸出(檢索或生成)。
實驗結果
上下文圖像生成
為了測試模型在全新圖像生成的基線方法的能力,研究人員在VIST和VisDial數據集上進行了實驗。
這些數據集與之前的研究中使用的數據集相同,用于對多模態文本和圖像上下文條件下的圖像檢索進行基準測試。
GILL模型組合了多模態信息以產生相關的圖像和文本輸出,性能優于僅限于圖像檢索的基線模型。

評估指標
評估的重點是生成模型處理復雜語言描述的能力。因此,研究人員計算了衡量生成圖像內容相關性的指標。
這里,有2個指標來評估模型:
1. CLIP相似度:使用CLIP ViT-L圖像編碼器來生成生成圖像和相應真實圖像的合并表示,并得出它們的余弦相似度。分數越高表示生成的圖像與真實圖像越相似。
2.學習感知圖像塊相似度(LPIPS):LPIPS評估圖像塊之間的距離。測量真實圖像和生成圖像之間的LPIPS。較低的值表示2個圖像在感知空間中更接近,而較高的值表示2個圖像更不相似。
從視覺故事生成
VIST是一個用于順序視覺和語言任務的數據集,其中包含構成故事的5個圖像和文本序列的示例。
評估結果顯示,將GILL與文本到圖像生成基線進行比較。
當2個模型都輸入一個故事描述時,性能相當,SD獲得了比較好的CLIP相似度得分,并且兩個模型獲得了相似的 LPIPS。
然而,當所有5個故事描述都作為輸入提供時,GILL優于SD,將CLIP相似度從0.598提高到0.612,將LPIPS從0.704 提高到0.6。
有趣的是,當進一步提供完整的多模態上下文時,GILL得到了顯著改進,獲得了0.641的CLIP相似度和0.3的LPIPS。

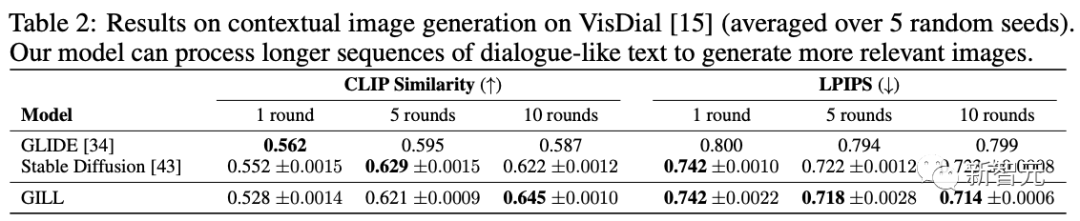
從視覺對話生成
研究人員還在VisDial數據集上測試了模型。
與VIST類似,評估模型準確合成所描述圖像的能力,并提供越來越多的問答對話上下文作為輸入。
評估結果顯示,輸入長度較短時,SD優于GILL。
然而,當輸入上下文增加時,GILL逐漸改進,并且可以合成與真實圖像更相似的圖像。
當提供完整的10輪對話時,GILL的性能顯著優于SD,比CLIP相似度(0.622-0.645)和LPIPS(0.723-0.714)都有所提高。
這些結果,進一步凸顯了GILL在處理類似對話的長文本輸入方面的有效性。
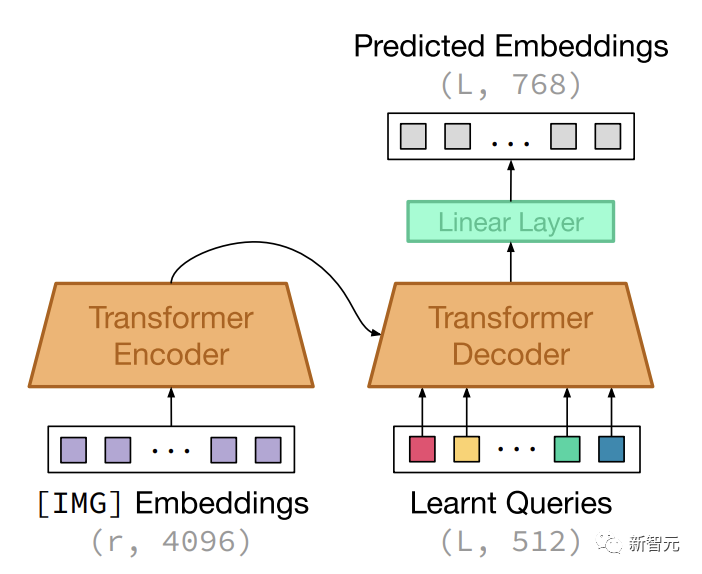
研究人員還引入了GILLMapper模塊,允許模型有效地映射到Stable Diffusion圖像生成骨干網,在PartiPrompts的許多示例中優于或匹配SD。

GILLMapper模型架構以隱藏的 [IMG] 表示和學習的查詢嵌入向量序列為條件。
局限性
雖然GILL引入了許多令人興奮的功能,但它是一個早期的研究原型,有幾個局限性。
- GILL的許多功能依賴于LLM主架構。因此,它也繼承了LLM典型的許多問題:
- GILL并不總是在提示時產生圖像,或者當它對對話有用時。
- GILL的局限性在于它有限的視覺處理。目前,研究只使用4個視覺向量來表示每個輸入圖像(由于計算限制),這可能無法捕獲下游任務所需的所有相關視覺信息。
- GILL繼承了LLM的一些意外行為,例如潛在的幻覺,它生成的內容是錯誤的,或者與輸入數據無關。它有時還會生成重復的文本,并且并不總是生成連貫的對話文本。
作者介紹
Jing Yu Koh
Jing Yu Koh是CMU機器學習系的二年級博士生,導師是Daniel Fried和Ruslan Salakhutdinov。
目前,他主要的研究方向是基礎語言理解。
丹尼爾·弗里德和魯斯蘭·薩拉庫蒂諾夫為我提供建議。我致力于基礎語言理解,通常是在視覺和語言問題的背景下。
在此之前,他是谷歌研究中心的一名研究工程師,在那里研究視覺和語言問題以及生成模型。































