愛奇藝魔鏡-解決大數據平臺分析化難題

一、魔鏡平臺背景介紹
首先和大家分享魔鏡平臺的背景。
1、遇到的問題&破局思路

2015年左右,整個互聯網行業處于高速發展的階段,業務多樣化,變化快,同時期在愛奇藝也有著非常多的創新業務在發展。由于業務的快速發展,固定的報表開發難以滿足業務方的數據需求,BI的表現主要是數據需求多,需求變化快,為了保證工作的有序推進,BI需要對業務的數據需求進行評審,然后根據優先級進行排期開發。對業務來說,數據工程師逐漸成為業務獲取數據的瓶頸,難以滿足業務的需求。
為解決這些問題,我們解決問題的思路是賦能業務自助獲取數據的能力,因此開發了數據分析平臺魔鏡,提升業務獲取數據的效率。
二、魔鏡平臺各階段發展歷程
1、魔鏡平臺各階段發展歷程

魔鏡平臺從2015年到現在共分為三個階段,第一個階段是2015年魔鏡1.0上線,主要支持pingback投遞管理和可視化分析。第二個階段是2019年上線了魔鏡2.0,主要支持數據倉庫表接入和數據分析模板化。第三個階段是2022年上線了魔鏡3.0,主要支持分析智能化與分析模板優化。
2、魔鏡1.0

2015年魔鏡1.0架構,在產品功能上支持了投遞注冊,在計算層面支持基礎計算、計算列表及計算執行結果的查看。在服務層主要支持投遞注冊、表管理以及對應的ETL。服務層主要支持基礎計算的SQL生成、計算執行及結果查看。引擎端主要支持Hive引擎。
(1)下面簡單介紹魔鏡1.0的前端交互頁面。

魔鏡1.0的基礎計算,前端配置主要分為三個部分,第一部分是選擇業務和表名,第二部分是計算信息的配置,主要是包括維度、指標以及計算條件。第三部分是配置計算的基本信息。通過簡單的三步配置,就可以讓用戶擁有自主分析數據的能力。
(2)接下來介紹魔鏡的執行計算和查看計算結果。

在計算執行層面,我們支持三種方式,第一種是計算一天,第二種是支持連續執行多天,第三種是支持自定義多天。
第一種很好理解只統計指定日期一天的數據。第二種連續計算多天,通常用戶在創建完計算之后需要回溯歷史數據,連續執行多天支持選擇一個開始時間和一個結束時間,平臺能幫助用戶去執行這段時間內每天的計算。第三種自定義執行多天可以指定一段時間內非連續的某幾天日期。例如可以選擇1號、3號、5號,當用戶只需要回溯一段時間內的某些日期的數據時,可以節省用戶回溯歷史數據的時間。下面的圖是計算執行完成之后,結果數據查看頁面。

(3)下面簡單總結魔鏡1.0的主要內容。

魔鏡1.0的主要優點是使用簡單,業務能自助獲取數據了。上線后有26%的BI報表用戶開始使用魔鏡進行數據分析,一定程度上解決了數據工程師人力問題,提高了數據需求處理效率。在1.0版本中還存在一些不足,主要表現為只支持單表計算,不支持復雜的數據分析場景,使用場景受限。在引擎端,由于采用的是單點執行,當計算并行度達到一定數量時,會存在5%的概率計算任務執行失敗。
3、魔鏡2.0

上面是魔鏡2.0架構,魔鏡2.0在產品功能上,通過對各業務的歷史數據需求的綜合梳理分析,發現數據需求主要集中在單表、關聯分析和留存分析等分析場景。所以我們在產品功能上抽象出基礎計算、關聯計算、留存計算等計算模板。在服務層數據管理中支持了數倉表注冊,下線了1.0版本中的投遞注冊。主要原因是1.0版本沒有對投遞做很好的管理,導致會存在一些數據質量問題。在定制計算部分支持了模板SQL生成。然后也支持各計算模板的計算執行和結果查看。在引擎端主要是集成了愛奇藝自研的分布式Gear工作流系統,Gear工作流系統支持將任務分布到 HIVE集群的各個節點去執行,解決了1.0版本單點執行計算有概率的任務失敗問題。

魔鏡2.0關聯計算,關聯計算的使用場景主要是支持多表分析,它解決了1.0版本僅支持單表分析的問題。整個業務配置步驟分為三部分,第一部分是配置子查詢計算信息。因為關聯計算至少是兩個子計算關聯,所以系統默認創建兩個子計算配置項,如果用戶的需求比較復雜,需要更多的關聯計算分析時,可以點擊添加計算按鈕添加計算。在關聯分析這一部分,系統支持常用的,例如join,left join ,right join等。第二步配置是配置維度信息、計算信息。第三步是配置基本信息。通過簡單的三步配置,用戶就可以實現復雜的關聯計算分析場景。

魔鏡留存分析適用的場景主要是用于衡量用戶的粘性,反映產品的受歡迎程度,通常APP上線之后,留存是一個很重要的分析指標,留存率越高表示用戶越喜歡你的產品。整個配置分為4部分,第一步是先定義初始行為,第二步是定義留存行為,第三步是選擇留存指標,系統提供一些常用的留存指標,例如次日留存,3日、7日,目前最大支持30日留存,這些基本涵蓋到常用的留存指標分析。第四部分是配置基本信息,通過簡單的四步配置,用戶就能實現業務的留存分析計算了。

前面介紹的是固定的分析模板。由于固定的分析模板,一定程度上只能支持通用的分析場景,不能滿足全部的數據分析需求。系統針對高端用戶即懂SQL的用戶,提供了直接編寫SQL的方式,用戶可以很方便的在任務開發區編寫SQL,編寫完成之后進行計算執行。任務執行完成后,在任務開發區的下方表格中可以查看計算執行結果。

魔鏡2.0的優點是通過標準的數據分析模板與自定義SQL形式,基本實現了分析場景的全覆蓋。魔鏡2.0上線之后,日均用戶數增長25%。通過接入數倉表,提高了數據質量,數據分層提升了用戶獲取數據的效率。在引擎端提升了引擎的穩定性,保障任務的成功率,大大提高了用戶體驗。同樣在魔鏡2.0版本還存在一些不足。主要集中在執行效率層面,由于魔鏡2.0版本底層使用的還是HIVE計算引擎,在日益增長的數據現狀下,難以滿足業務獲取數據的時效性需求。在可視化層面僅支持表格查看數據,用戶如果需要進行圖表可視化分析,需要將數據導出之后使用第三方分析工具進行圖表的可視化,使用流程會非常長。
三、當前架構、功能及解決的問題
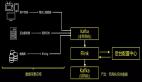
1、魔鏡3.0架構

上圖是魔鏡3.0的整體架構,在存儲層支持HIVE,ICEBERG,本地存儲。數據層支持統一數倉與數據集市數據。統一數倉包含DWD層,MID層,還包括DIM層以及AL層數據。數據集市也包含DWD層、MID層,DIM層與AL層數據。除了以上數倉的范疇之外,還支持本地文件上傳,因為用戶可能需要將本地數據上傳到魔鏡平臺進行數據分析。
引擎端自研了pilot通用計算引擎。服務層主要是對2.0版本的自定義SQL分析與基礎分析模板進行了優化升級。通用服務層面抽象出訂閱服務,對計算結果進行郵件訂閱。應用層的主要使用場景是包括用戶增長、會員營銷、內容運營、產品分析等。
2、魔鏡3.0數據層
我們看一下魔鏡3.0的數據層的處理流程。

在數據源部分,魔鏡3.0主要包括APP的行為日志、業務后臺數據及其他數據源。數據源通過實時數據入湖,進入到統一數倉的原始數據層ODS層,然后經過實時處理傳輸到DWD層,然后再向上匯總進入到MID層。統一數倉的數據可以再向上產出到業務集市,最終就支持了上層的定制計算模板分析與自定義SQL分析。這樣的數據存儲優勢在于,第一數據是實時入湖的,時效性高;第二是因為數倉采用了統一的指標和統一的維度,數據含義清晰降低了用戶的理解成本;第三是數據質量高,因為數據經過了數倉的統一數據治理,大大提高了數據質量。數據分層之后,用戶可以優先選擇使用MID層數據,因為MID層是經過了聚合的數據,可以大大提高數據查詢的效率。
3、魔鏡3.0pilot引擎

pilot引擎主要支持4個功能,第一是語法解析,第二是支持查詢攔截,第三是計算智能路由,最后是多引擎支持。
架構層面,在底層主要是基礎平臺,支持HADOOP、TRINO、IMPALA。其中TRINO和IMPALA都是獨立部署的。在引擎端主要支持 SPARK SQL、HIVE、TRINO和IMPALA。引擎端之上是服務端,最上層是客戶端。整個引擎的處理流程是客戶端首先將用戶執行的SQL進行語法解析,語法解析校驗用戶輸入的SQL是否存在語法問題。語法解析通過之后會進行數據源解析,數據源解析主要是檢查用戶使用的數據源類型。例如HIVE,ICEBERG等。當數據源解析通過之后,會進行大數據查詢攔截。大數據查詢攔截的作用是檢測用戶的查詢是否有指定分區條件,主要是為了防止用戶漏掉分區條件之后會導致全表查詢,進而會影響集群的性能。
語法解析服務通過之后,會進入到路由服務。路由服務主要的作用是智能的識別用戶SQL的執行集群,結合元數據服務智能識別出用戶擁有表訪問權限的賬號與YARN資源隊列。
經過路由服務之后,客戶端會將查詢提交到服務端,服務端會根據解析服務中解析出的數據源類型,去使用對應的查詢引擎。例如當用戶使用的數據源類型是HIVE表時,服務端會優先使用SPAKR SQL執行。當用戶使用的數據源類型是ICEBERG表時,服務端會使用TRINO引擎。以上對用戶是完全無感知的,最后服務端會將查詢任務提交到基礎計算平臺執行,執行完成之后會將查詢的結果反饋給客戶端。
在服務端還支持日志中心,方便用戶在計算執行過程中可以查看任務的執行日志。當發生異常時,用戶可以判斷任務失敗原因。比如語法問題或其他的原因。另外服務端也支持監控中心監控當前服務端的壓力情況,當負載過大時可以支持動態擴容。
pilot引擎上線之后用戶無需關心任務應該在哪里執行,使用什么樣的資源。提高了任務的執行效率與用戶的體驗。
在2.0版本時使用的HIVE引擎,當時任務的平均時長在20分鐘左右,Pilot引擎上線之后,任務的平均直接時長在6分鐘左右,提高了70%,大大提高了用戶分析數據的效率。
4、魔鏡3.0自定義Sql

自定義SQL在功能層面主要是支持分析的場景化和圖表的可視化。
分析的場景化主要帶來兩個方面的優勢。
第一,從產品層面來看,2.0版本計算執行完之后,是以列表的形式來展現,非常不利于用戶查找歷史計算。做了場景化之后,先是創建一個菜單,再去添加計算。這樣的優勢是用戶在查找歷史計算時,通過找到對應的菜單,就能找到歷史的計算。
第二,從數據分析思維層面來看,主要是有數據分析思維的提升。比如有了分析場景之后,用戶需要先明確需求是什么,明確了需求相當于分析場景有了,然后再進一步去做需求拆解,我先做什么再做什么。
比如愛奇藝一部很火的劇《塵封13載》,假設說我是這部劇的運營,我需要分析這部劇的數據,我的需求是對《塵封13載》做一個數據分析,第一步,我先統計這部劇的整體數據,可以觀察出數據的趨勢。通過趨勢數據觀察到一些信息之后,比如某天流量上漲,需要分析上漲的流量來源,就可以再細化統計該天這部劇導流資源位的數據,去衡量資源位的導流情況。通過這樣一種方式便訓練了用戶結構化數據分析的思維。
關于圖表的可視化,在2.0版本中自定義SQL只支持表格查看數據,表格不便于用戶很好的理解數據,用戶需要將數據導出后進行圖表可視化。在3.0版本結果查看部分直接集成了圖表可視化的功能,目前主要支持4種可視化圖表分析,例如趨勢圖,餅圖、柱狀圖等。下圖是可視化圖表樣例。

5、魔鏡3.0基礎計算

魔鏡3.0優化了基礎計算,優點是統一了指標和維度,用戶無感知的實現了多表分析,提升了用戶體驗,并且用戶不用關心計算的數據源。
下面是具體的配置流程,用戶第一步選擇業務,選擇業務之后,第二步是添加計算指標。對比1.0版本,用戶需要具體配置指標計算規則,比如需要關心我應該是用去重計數,還是應該用求和。新版本優化后,系統直接集成了數倉指標,用戶直接添加就可以,不需要關心指標的具體計算規則,節省了用戶理解的成本。
系統是怎么實現用戶無感知多表分析的,首先系統將指標依據數倉的概念按照事件類型區分,當用戶選擇多個事件類型的指標時,比如上述圖片有一個系統啟動的指標和頁面展現的指標,這兩個指標是跨多個事件的,在底層來說可能就會對應到多張表,多張表的邏輯對用戶是無感知的,這樣就大大的擴展了用戶場景分析的使用場景。
除了支持數倉的指標之外,還支持用戶自定義指標。自定義指標的含義是指用戶可以基于選擇的數倉指標,通過四則運算方式創建自定義指標。
第三步指標配置完成之后用戶可以選擇維度。在維度這一部分,系統還支持一個比較高級的功能,用戶選擇維度之后,可能需要對維度做一些處理。比如選擇了一個日期維度,用戶希望通過這個日期去生成一個周維度或者一個月維度,那么就可以在選擇使用日期函數,很方便的支持維度的擴展,這是一個很方便的功能。
第四部分是查詢條件,查詢條件對于用戶來說是一個可選的配置,如果用戶希望統計業務的全量數據,是不需要配置的。
6、魔鏡3.0基礎計算指標體系

魔鏡3.0基礎分析的指標體系,通過具體的指標體系,支持基礎分析的優化,指標體系的一個優點是統一了指標的含義,相同類型的指標名稱是固定的,節省了用戶理解的成本。第二個優點是統一了指標的口徑。
下面具體介紹指標體系,指標體系在最底層是指標元數據,包括原子指標和復合指標,這個指標元數據是由數倉的管理員去創建的。
數倉管理員創建好指標元數據之后,上層統計指標是由業務的數據產品來創建,即業務數據產品收到業務的數據需求之后會來創建統計指標,統計指標也是包含了兩大類,一種是統計指標,第二種是復合統計指標。統計指標是基于原子指標,結合時間統計周期,然后再加上修飾詞,規范的產生出統計指標。復合統計指標也是復合統計指標,結合時間周期,然后再加上修飾詞規范的產出了復合統計指標。
有了統計指標之后會再進入到統一數倉,統一數倉先利用指標元數據進行數據建模,數據建模之后會再產出物理建模,會具體產出表。
當統一數倉把模型創建好之后,上層的業務集市會基于統一數倉模型進行業務集市的數據建模和物理建模,最終這些數據將在基礎分析中進行使用。
前面提到用戶無需關心使用的表,具體的實現方式是用戶在配置頁面,選擇指標和維度之后,服務端可以基于用戶選擇的維度、指標信息結合維度信息智能的匹配出數據模型。這里有一個策略,理論上我們最上層的數據模型是最優的,比如匹配到一個聚合層的模型,這聚合層的模型是一個聚合的表,因為數據量會減少,最終的體現是查詢效率會很高。通過匹配到最優的數據模型之后,就能匹配出物理表,整個實現了基礎分析的優化。
7、魔鏡3.0分析看板

魔鏡3.0版本支持分析看板,解決了1.0和2.0版本分析模板結果的查看效果。1.0和2.0版本呈現的都是一個表格,不太便于用戶去分析數據。通過分析看板的多計算數據結果可視化能力,提升了數據分析綜合能力。
上面截圖可看到,一個圖對應一個計算,用戶可以根據需求添加多個組件。
四、魔鏡平臺收益

第四部分是魔鏡平臺上線后的收益,魔鏡平臺的收益可以從以上4個角度衡量。
第一個,從業務角度,模型平臺上線之后,到現在基本上實現了全業務的覆蓋,即整個公司業務線都在使用魔鏡平臺進行數據分析。
第二個,從用戶層面來看,基本上公司的產品、運營、分析師、開發等等都在使用魔鏡平臺。
第三個,從時效性角度來看,業務獲取數據的時間,從以前的天級降到現在的分鐘級,大大節省了業務獲取數據進行分析的效率。
第四個,從資源層面來看,一是降本增效,二是數據安全。在降本增效層面,早期的時候,業務通過跳板機直接登錄到服務器進行數據查詢,我們和公司的大數據團隊配合去推動服務器的下線,大概下線幾百臺服務器,大大節省公司成本。從數據安全角度來看,早期的時候用戶是通過服務器去查詢更新數據,這樣會帶來一個風險,即用戶在服務器上更新線上表數據時是不可控的,數據產出之后,用戶還能通過服務器S進行數據更新,這是非常不安全,也會帶來數據的一致性問題。現在我們將服務器下線之后,全部通過魔鏡平臺去實現時,魔鏡平臺通過分析SQL能夠監控到用戶是查詢還是更新操作。如果是更新操作,系統會進行攔截。
五、未來展望

最后一部分是未來的展望,未來展望第一個是擴展查詢引擎,第二個是讓數據分析更智能化,現在的分析模板主要還是配置化操作,我們希望可以更智能化的節省用戶的配置操作。