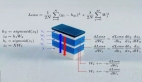
能像樂高一樣組合,LoraHub挖掘LoRA 模塊化特性
低秩自適應(Low-Rank Adaptation, LoRA)是一種常用的微調技術,讓基礎 LLM 可以高效地適應具體任務。
OpenAI GPT、Flan-T5 和 LLaMA 等大型預訓練語言模型(LLM)極大的推動了自然語言處理(NLP)領域的發(fā)展。這些模型在許多 NLP 任務上都有絕佳表現(xiàn)。但是,由于這些模型都有大量參數(shù),因此在微調時會涉及計算效率和內存使用量等問題。
低秩自適應(LoRA)就是一種可以緩解這些問題的高效微調技術。它能降低內存需求和計算成本,從而提升 LLM 訓練速度。
LoRA 的做法是凍結基礎模型(即 LLM)的參數(shù),然后訓練一個輕量級的輔助模塊,并且這個模塊通常在目標任務上能取得優(yōu)良表現(xiàn)。
盡管之前已有研究探索過使用 LoRA 來提升效率,但少有人探究 LoRA 模塊固有的模塊化特性和可組合性。大體而言,之前的方法訓練的 LoRA 模塊都是專精于各個任務和領域。然而,LoRA 模塊固有的模塊化特性本身就具備一個有趣的研究問題:能否將 LoRA 模塊用于將 LLM 高效地泛化用于未曾見過的任務?
這篇論文挖掘了 LoRA 的模塊化特性在廣泛圍任務泛化方面的潛力,使之不再局限于單任務訓練,通過精心構建 LoRA 模塊使之在未知任務上也能取得一定性能。最重要的是,這種方法據(jù)稱能實現(xiàn) LoRA 模塊的自動組合,從而無需再依賴人工設計或人類專家。只需從未曾見過的任務取少量示例,這種新方法就能自動編排兼容的 LoRA 模塊,而無需人類干預。研究者并沒有預設在具體任務上訓練的哪些 LoRA 模塊可以組合,而是符合規(guī)范(例如使用相同的 LLM)的模塊都可以靈活地合并進來。由于該方法使用了多種可用的 LoRA 模塊,因此研究者將其命名為 LoraHub,將新的學習方法稱為 LoraHub 學習。

論文地址:https://arxiv.org/abs/2307.13269
代碼地址:https://github.com/sail-sg/lorahub
他們也通過實驗驗證了新方法的效率,其中使用的基礎 LLM 是 Flan-T5,評估基準是被廣為認可的 BBH 基準。結果表明,通過一些少樣本 LoraHub 學習過程,LoRA 模塊組合就能高效地用于未曾見過的任務。值得注意的是,新方法獲得的分數(shù)非常接近于少樣本上下文學習的表現(xiàn)。
此外,相比于上下文學習,新方法還能顯著降低推理成本,消除了 LLM 對示例輸入的需求。這個學習過程還體現(xiàn)出了另一個重要優(yōu)勢,即計算效率;其使用了一種無梯度方法來獲取 LoRA 模塊的系數(shù),并且對于未見過的任務只需少量推理步驟。舉個例子,當在 BBH 基準上評估時,新方法使用單塊 A100 在一分鐘內就能取得更優(yōu)的表現(xiàn)。

圖 1:零樣本學習、少樣本上下文學習和新提出的少樣本 LoraHub 學習。注意組合過程是基于每個任務執(zhí)行的,而不是基于每個示例。新方法的推理吞吐量與零樣本學習相近,而在 BIG-Bench Hard(BBH)基準上的性能表現(xiàn)接近上下文學習。
需要重點指出的是,LoraHub 學習在只有 CPU 的計算機上也能完成,畢竟它只需要熟練處理 LLM 推理。這種方法憑借其多功能性和穩(wěn)健的性能表現(xiàn),有望催生出一個平臺,讓用戶可以毫不費力地共享和獲取訓練好的 LoRA 模塊并將其用于新任務。研究者設想,通過這樣一個平臺,可培育一個包含無數(shù)功能的可復用 LoRA 模塊庫。這也能為協(xié)作式 AI 開發(fā)提供舞臺,讓社區(qū)能夠通過動態(tài) LoRA 組合來共同豐富 LLM 的能力。這種共享和復用模塊的潛力可望實現(xiàn)在不同任務上的資源最優(yōu)利用。
方法
如圖 2 所示,研究者首先在多種上游任務上訓練 LoRA 模塊。具體來說,對于 N 個不同的上游任務,首先分別訓練 N 個 LoRA 模塊。然后,對于新任務(如圖 2 中的布爾表達式),就使用該任務的示例來引導 LoraHub 學習過程。

圖 2:新方法包含兩個階段:組合階段(COMPOSE)和適應階段(ADAPT)
組合階段是通過一組權重系數(shù)將已有的 LoRA 模塊整合成一個統(tǒng)一模塊。適應階段是使用未曾見過的任務的少量示例對合并得到的 LoRA 模塊進行評估。然后,使用一個無梯度算法來優(yōu)化上述權重。執(zhí)行過幾輪迭代后,會產(chǎn)生一個經(jīng)過高度適應的 LoRA 模塊,其可被集成到 LLM 中,用以執(zhí)行目標任務。對該方法的詳細數(shù)學描述請參閱原論文。
評估
研究者對新提出的方法進行了評估,其使用的 LLM 是 Flan-T5。
表 1 給出了實驗數(shù)據(jù),可以看到,新方法的功效接近零樣本學習,同時在少樣本場景中的性能表現(xiàn)又接近上下文學習。這一觀察結論基于五次不同實驗的平均結果。

表 1:零樣本學習(Zero)、少樣本上下文學習(ICL)和新提出的少樣本 LoraHub 學習的性能表現(xiàn)對比。
需要重點指出,實驗中,使用新方法的模型使用的 token 數(shù)量與零樣本方法一樣,明顯少于上下文學習所用的 token 數(shù)。盡管性能表現(xiàn)偶爾會有波動變化,但新方法的表現(xiàn)在大多數(shù)實例中都優(yōu)于零樣本學習。新方法真正出彩的地方是其最優(yōu)表現(xiàn)超越了上下文學習,但使用的 token 卻更少。在 LLM 時代,推理成本與輸入長度成正比,因此 LoraHub 能經(jīng)濟地利用輸入 token 達到接近最佳性能的能力會越來越重要。
如圖 3 所示,當未曾見過的任務的示例數(shù)量低于 20 時,新方法的表現(xiàn)大體上都優(yōu)于 LoRA 微調。

圖 3:傳統(tǒng)微調(FFT)、LoRA 微調(LoRA)和新提出的 LoraHub 學習(Ours)在不同數(shù)量的任務示例下的表現(xiàn)對比。