Pandas圖鑒:Series 和 Index
Pandas[1]是用Python分析數(shù)據(jù)的工業(yè)標準。只需敲幾下鍵盤,就可以加載、過濾、重組和可視化數(shù)千兆字節(jié)的異質信息。它建立在NumPy庫的基礎上,借用了它的許多概念和語法約定,所以如果你對NumPy很熟悉,你會發(fā)現(xiàn)Pandas是一個相當熟悉的工具。即使你從未聽說過NumPy,Pandas也可以讓你在幾乎沒有編程背景的情況下輕松拿捏數(shù)據(jù)分析問題。
Pandas 給 NumPy 數(shù)組帶來的兩個關鍵特性是:
- 異質類型 —— 每一列都允許有自己的類型
- 索引 —— 提高指定列的查詢速度
事實證明,這些功能足以使Pandas成為Excel和數(shù)據(jù)庫的強大競爭者。
Polars[2]是Pandas最近的轉世(用Rust編寫,因此速度更快,它不再使用NumPy的引擎,但語法卻非常相似,所以學習 Pandas 后對學習 Polars 幫助非常大。
Pandas 圖鑒系列文章由四個部分組成:
- Part 1. Motivation:Pandas圖鑒(一):Pandas vs Numpy
- Part 2. Series and Index
- Part 3. DataFrames
- Part 4. MultiIndex
我們將拆分成四個部分,依次呈現(xiàn)~建議關注和星標@公眾號:數(shù)據(jù)STUDIO,精彩內容等你來~
Part 2. Series 和 Index
 Series剖析
Series剖析
Series是NumPy中一維數(shù)組的對應物,是DataFrame代表其列的基本構件。盡管與DataFrame相比,它的實際重要性正在減弱(你完全可以在不知道Series是什么的情況下解決很多實際問題),但如果不先學習Series和Index,可能很難理解DataFrame的工作原理。
在內部,Series將數(shù)值存儲在一個普通的NumPy向量中。因此,它繼承了它的優(yōu)點(緊湊的內存布局,快速的隨機訪問)和缺點(類型同質性,緩慢的刪除和插入)。在此基礎上,可以通過標簽訪問Series的值,使用一個叫做index的類似數(shù)字的結構。標簽可以是任何類型的(通常是字符串和時間戳)。它們不需要是唯一的,但唯一性是提高查詢速度所需要的,并且在許多操作中都是假定的。
 圖片
圖片
現(xiàn)在每個元素都可以用兩種方式來處理:通過label(=使用索引)和通過position(=不使用索引):
 圖片
圖片
按位置尋址by position 有時被稱為 by positional index,這只是增加了混亂。
很明顯,一對方括號是不夠的。特別是:
- s[2:3]不是解決2號元素的最方便方式
- 如果標簽恰好是整數(shù),s[1:3]就變得模糊不清。它可能是指標簽1到3(含)或位置指數(shù)1到3(不含)。
為了解決這些問題,Pandas又有兩種方括號的 "口味":
 圖片
圖片
- .loc[]總是使用標簽并包括區(qū)間的兩端;
- .iloc[]總是使用位置索引,并排除了右端。
在這里使用方括號而不是小括號的目的是為了獲得方便的Python切分:可以使用一個單冒號或雙冒號,其含義是熟悉的start:stop:step。缺失的 start(end) 就是從系列的開始(到結束)。步驟參數(shù)允許用s.iloc[::2]來引用偶數(shù)行,用s['Paris':'Oslo':-1]來獲取反向順序的元素。
它們還支持布爾索引(用布爾數(shù)組進行索引),如該圖所示:
 Series.isin(), Series.between()
Series.isin(), Series.between()
而可以在這張圖片中看到他們是如何支持 "花式索引" 的(用整數(shù)陣列進行索引):
 圖片
圖片
由于某些原因,Series沒有一個漂亮的富文本外觀,所以與DataFrame相比,看似比較低級:
 圖片
圖片
這里對Series進行稍加修飾,使其看起來更好,如下圖所示:
 圖片
圖片
豎線意味著這是一個Series,而不是一個DataFrame。
也可以用pdi.sidebyside(obj1, obj2, ...)來并排顯示幾個系列或DataFrames:
 圖片
圖片
pdi(代表pandas illustrated)是github上的一個開源庫pdi[3],具有本文的這個和其他功能。安裝非常方便:
pip install pandas-illustrated索引
負責通過標簽獲取系列元素(以及DataFrame的行和列)的對象被稱為索引。索引速度很快:無論有5個元素還是50億個元素,都可以在一定的時間內得到結果。
索引是一個真正的多態(tài)對象。默認情況下,當創(chuàng)建一個沒有索引參數(shù)的Series(或DataFrame)時,它初始化為一個類似于Python的range()的惰性對象。就像range()一樣,它幾乎不使用任何內存,并提供與位置索引相吻合的標簽。
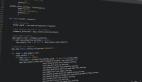
現(xiàn)在創(chuàng)建一個有一百萬個元素的系列:
>>> s = pd.Series(np.zeros(10**6))
>>> s.index
RangeIndex(start=0, stop=1000000, step=1)
>>> s.index.memory_usage() # 字節(jié)數(shù)
128 # 與Series([0.])的情況相同現(xiàn)在,如果刪除一個元素,索引就會隱含地變形為一個類似口令的結構,如下所示:
>>> s1 = s.drop(1)
>>> s1.index
Int64Index([ 0, 2, 3, 4, 5, 6, 7、
...
999993, 999994, 999995, 999996, 999997, 999998, 999999],
dtype='int64', length=999999)
>>> s1.index.memory_usage()
7999992這個結構消耗了8Mb的內存!,為了避免這種情況,并回到輕量級的類似范圍的結構,我們寫下:
>>> s2 = s1.reset_index(drop=True)。
>>> s2.index
RangeIndex(start=0, stop=999999, step=1)
>>> s2.index.memory_usage()
128如果你是Pandas的新手,你可能會想為什么Pandas不自己做呢?對于非數(shù)字標簽來說,這有點顯而易見:為什么(以及如何)Pandas在刪除一行后,會重新標記所有后續(xù)的行?對于數(shù)字標簽,答案就有點復雜了。
首先,Pandas 純粹通過位置來引用行,所以如果想在刪除第3行之后再去找第5行,可以不用重新索引(這就是iloc的作用)。
第二,保留原始標簽是一種與過去某個時刻保持聯(lián)系的方式,就像 "保存游戲" 按鈕。如果你有一個有一百列和一百萬行的大表,需要找到一些數(shù)據(jù)。你逐一進行了幾次查詢,每次都縮小了搜索范圍,但只看了列的一個子集,因為同時看到所有的一百個字段是不現(xiàn)實的。現(xiàn)在你已經(jīng)找到了目標行,想看到原始表中關于它們的所有信息。一個數(shù)字索引可以幫助你立即得到它。
從原理上講,如下圖所示:
 圖片
圖片
一般來說,需要保持索引值的唯一性。例如,在索引中存在重復的值時,查詢速度的提升并不會提升。Pandas沒有像關系型數(shù)據(jù)庫那樣的 "唯一約束"(該功能[4]仍在試驗中),但它有一些函數(shù)來檢查索引中的值是否唯一,并以各種方式刪除重復值。
有時,但一索引不足以唯一地識別某行。例如,同名的城市有時碰巧出現(xiàn)在不同的國家,甚至在同一個國家的不同地區(qū)。因此,(城市,州)是一個比單獨的城市更適合識別一個地方的候選者。在數(shù)據(jù)庫中,它被稱為 "復合主鍵"。在Pandas中,它被稱為MultiIndex(第4部分),索引內的每一列都被稱為level。
索引的另一個重要特性是它是不可改變的。與DataFrame中的普通列相比,你不能就地修改它。索引中的任何變化都涉及到從舊的索引中獲取數(shù)據(jù),改變它,并將新的數(shù)據(jù)作為一個新的索引重新連接起來。例如,要將列名就地轉換為字符串(節(jié)省內存),可以寫df.columns = df.columns.astype(str),或者不就地轉換(對鏈式方法有用)df.set_axis(df.columns.astype(str), axis=1)。但正是由于不可更改性,不允許只寫df.City.name = 'city',所以必須借助于df.rename(columns={'City': 'city'})。
索引有一個名字(在MultiIndex的情況下,每一層都有一個名字)。而這個名字在Pandas中沒有被充分使用。一旦在索引中包含了列,就不能再使用方便的df.column_name符號了,而必須恢復到不太容易閱讀的df.index或者更通用的df.loc[]。有了MultiIndex。df.merge--可以用名字指定要合并的列,不管這個列是否屬于索引。
按值查找元素
考慮以下Series對象:
 圖片
圖片
索引提供了一種快速而方便的方法,可以通過標簽找到一個值。但是,通過值來尋找標簽呢?
s.index[s.tolist().find(x)] # 對于len(s)< 1000來說更快
s.index[np.where(s.value==x)[0][0]] # 對于 len(s) > 1000,速度更快pdi中有一對包裝器,叫做find()和findall(),它們速度快(因為它們根據(jù)Series的大小自動選擇實際的命令),而且更容易使用。
如下代碼所示:
>>> import pdi
>>> pdi.find(s, 2)
'penguin'
>>> pdi.findall(s, 4)
Index(['cat', 'dog'], dtype='object')缺失值
Pandas使用者對缺失值特別關注。通常情況下,可以通過向read_csv提供一個標志來接收一個帶有NaN的DataFrame。否則,可以在構造函數(shù)或賦值運算符中使用None(盡管對于不同的數(shù)據(jù)類型,它的實現(xiàn)方式略有不同),例如:
 圖片
圖片
對于NaN,可以做的第一件事是了解是否有任何NaN。從上圖可以看出,isna()產(chǎn)生一個布爾數(shù)組,而.sum()給出缺失值的總數(shù)。
現(xiàn)在你知道它們的存在,可以選擇通過刪除、用常量值填充或插值來擺脫它們,如下所示:
 fillna(), dropna(), interpolate()
fillna(), dropna(), interpolate()
另一方面,可以繼續(xù)使用它們。大多數(shù)Pandas函數(shù)都會忽略缺失的值:
 圖片
圖片
更高級的函數(shù)(median, rank, quantile等)也是如此。
算術操作是根據(jù)索引來調整的:
 圖片
圖片
在索引中存在非唯一值的情況下,其結果是不一致的。不要對具有非唯一索引的系列使用算術運算。
比較
對有缺失值的數(shù)組進行比較可能很棘手。這里有一個例子:
>>> np.all(pd.Series([1., None, 3.]) ==
pd.Series([1., None, 3.]))
False
>>> np.all(pd.Series([1, None, 3], dtype='Int64') ==
pd.Series([1, None, 3], dtype='Int64'))
True
>>> np.all(pd.Series(['a', None, 'c']) ==
pd.Series(['a', None, 'c']))
False為了正確地進行比較,NaN需要被替換成保證在數(shù)組中缺少的東西。例如,用''、-1或∞:
>>> np.all(s1.fillna(np.inf) == s2.fillna(np.inf)) #對所有的dtypes都有效
True或者更好的是,使用標準的NumPy或Pandas比較函數(shù):
>>> s = pd.Series([1., None, 3.])
>>> np.array_equal(s.value, s.value, equal_nan=True)
True
>>> len(s.compare(s)) == 0
True這里,比較函數(shù)返回一個差異列表(實際上是一個DataFrame),而array_equal直接返回一個布爾值。
當比較混合類型的DataFrame時,NumPy就會出問題(問題#19205[5]),而Pandas做得非常好。下面是這一情況:
>>> df = pd.DataFrame({'a': [1., None, 3.], 'b': ['x', None, 'z']})
>>> np.array_equal(df.values, df.values, equal_nan=True)
TypeError
<...>
>>> len(df.compare(df)) == 0
True添加、插入、刪除
盡管系列對象應該是大小不可變的,但有可能在原地追加、插入和刪除元素,但所有這些操作都是:
- 緩慢,因為它們需要為整個對象重新分配內存并更新索引;
- 痛苦的不方便。
下面是插入數(shù)值的一種方式和刪除數(shù)值的兩種方式:
 圖片
圖片
第二種刪除值的方法(通過刪除)比較慢,而且在索引中存在非唯一值的情況下可能會導致復雜的錯誤。
Pandas有df.insert方法,但它只能將列(而不是行)插入到數(shù)據(jù)框架中(而且對序列根本不起作用)。
另一種追加和插入的方法是用iloc對DataFrame進行切片,應用必要的轉換,然后用concat把它放回去。pdi中實現(xiàn)了一個叫做insert的函數(shù),可以自動完成這個過程:
 圖片
圖片
注意,(就像在df.insert中一樣)插入的位置是由0<=i<=len(s)的位置給出的,而不是由索引中的元素的標簽。
你可以為一個新元素提供一個標簽。對于一個非數(shù)字性的索引,它是必須的。例如:
 圖片
圖片
要通過標簽指定插入點,你可以把pdi.find和pdi.insert結合起來,如下圖所示:
 圖片
圖片
注意,與df.insert不同,pdi.insert返回一個副本,而不是在原地修改Series/DataFrame。
統(tǒng)計數(shù)據(jù)
Pandas提供了全方位的統(tǒng)計功能。它們可以深入了解百萬元素系列或數(shù)據(jù)框架中的內容,而無需手動滾動數(shù)據(jù)。
所有的Pandas統(tǒng)計函數(shù)都會忽略NaN,如下圖所示:
 圖片
圖片
注意,Pandas std給出的結果與NumPy std不同。
由于系列中的每個元素都可以通過標簽或位置索引來訪問,所以有一個argmin(argmax)的姐妹函數(shù),叫做idxmin(idxmax),如圖所示:
 圖片
圖片
下面是Pandas的自描述性統(tǒng)計函數(shù)的列表,供參考:
- std,樣本標準差;
- var,無偏方差;
- sem,無偏標準誤差的平均值;
- quantile,樣本四分位數(shù)(s.quantile(0.5) ≈ s.median());
- mode,即出現(xiàn)頻率最高的值;
- nlargest和nsmallest,默認情況下,按外觀順序排列;
- diff,第一次離散差分;
- cumsum和cumprod,累積和,以及乘積;
- cummin和cummax,累積最小和最大。
還有一些更專業(yè)的統(tǒng)計功能:
- pct_change,當前和前一個元素之間的變化百分比;
- skew,無偏差的偏度(第三時刻);
- kurt 或 kurtosis,無偏的谷度(第四時刻);
- cov,corr 和 autocorr,協(xié)方差,相關,和自相關;
- rolling、加權和指數(shù)加權的窗口。
重復數(shù)據(jù)
特別注意檢測和處理重復的數(shù)據(jù),可以在圖片中看到:
 is_unique,nunique, value_counts
is_unique,nunique, value_counts
drop_duplicates 和 duplicated 可以保留最后出現(xiàn)的,而不是第一個。
請注意,s.unique()比np.unique要快(O(N)vs O(NlogN)),它保留了順序,而不是像np.unique那樣返回排序后的結果。
缺失值被當作普通值處理,這有時可能會導致令人驚訝的結果。
 圖片
圖片
如果想排除NaN,你需要明確地做到這一點。在這個特殊的例子中,s.dropna().is_unique == True。
還有一個單調函數(shù)家族:
- s.is_monotonic_increasing()、
- s.is_monotonic_decreasing()、
- s._strict_monotonic_increasing()、
- s._string_monotonic_decreasing()
- s.is_monotonic() - 這是s.is_monotonic_increasing()的同義詞,對于單調下降的序列返回False!
字符串和正則表達式
幾乎所有的Python字符串方法在Pandas中都有一個矢量的版本:
 count, upper, replace
count, upper, replace
當這樣的操作返回多個值時,有幾個選項來決定如何使用它們:
 split, join, explode
split, join, explode
如果知道正則表達式,Pandas也有矢量版本的常用操作:
 findall, extract, replace
findall, extract, replace
Group by
在數(shù)據(jù)處理中,一個常見的操作是計算一些統(tǒng)計數(shù)據(jù),而不是對整個數(shù)據(jù)集,而是對其中的某些組。第一步是通過提供將一個Series(或一個DataFrame)分成若干組的標準來建立一個惰性對象。這個惰性的對象沒有任何有意義的表示,但它可以是:
- 迭代(產(chǎn)生分組鍵和相應的子系列--非常適合于調試):
 groupby
groupby
- 以與普通系列相同的方式進行查詢,以獲得每組的某個屬性(比迭代快):
 圖片
圖片
所有操作都不包括NaNs
在這個例子中,根據(jù)數(shù)值除以10的整數(shù)部分,將系列分成三組。對于每一組,要求提供元素的總和,元素的數(shù)量,以及每一組的平均值。
除了這些集合功能,還可以根據(jù)特定元素在組內的位置或相對價值來訪問它們。下面是這種情況:
 min, median, max, first, nth, last
min, median, max, first, nth, last
你也可以用g.agg(['min', 'max'])一次計算幾個函數(shù),或者用g.describe()一次顯示一大堆的統(tǒng)計函數(shù)。
如果這些還不夠,也可以通過自己的Python函數(shù)傳遞數(shù)據(jù)。它可以是
- 用g.apply(f)接受一個組x(一個系列對象)并生成一個單一的值(如sum())的函數(shù)f。
- 一個函數(shù)f接受一個組x(一個系列對象),并用g.transform(f)生成一個與x相同大小的系列對象(例如,cumsum())。
 圖片
圖片
在上面的例子中,輸入的數(shù)據(jù)被排序了。這對于groupby來說是不需要的。實際上,如果組內元素不是連續(xù)存儲的,它也同樣能工作,所以它更接近collections.defaultdict而不是itertools.groupby。而且它總是返回一個沒有重復的索引。
 圖片
圖片
與defaultdict和關系型數(shù)據(jù)庫的GROUP BY子句不同,Pandas groupby是按組名排序的。它可以用sort=False來禁用,如下代碼所示:
>>> s = pd.Series([1, 3, 20, 2, 10])
>>> for k, v in s.groupby(s//10, sort=False):
print(k, v.tolist())
0 [1, 3, 2]
2 [20]
1 [10]參考資料
[1]Pandas: https://pandas.pydata.org/
[2]Polars: https://www.pola.rs/
[3]pdi: https://github.com/axil/pandas-illustrated
[4]該功能: https://pandas.pydata.org/docs/reference/api/pandas.Flags.allows_duplicate_labels.html
[5]問題#19205: https://github.com/numpy/numpy/issues/19205