擔(dān)心prompt泄露隱私?這個框架讓LLaMA-7B完成安全推理
現(xiàn)如今已有大量提供深度學(xué)習(xí)服務(wù)的供應(yīng)商,在使用這些服務(wù)時,用戶需要將自己的信息包含在 prompt 中發(fā)送給這些服務(wù)商,這會導(dǎo)致隱私泄漏等問題。另一方面,服務(wù)商基本不愿意公開自己辛苦訓(xùn)練得到的模型參數(shù)。
針對這一問題,螞蟻集團的一個研究團隊提出了 PUMA 框架,可以在不影響模型性能的前提下實現(xiàn)安全的推理。不僅如此,他們也開源了相關(guān)代碼。

- 論文:https://arxiv.org/abs/2307.12533
- 代碼:https://github.com/secretflow/spu/blob/main/examples/python/ml/flax_llama7b/flax_llama7b.py
預(yù)訓(xùn)練 Transformer 模型在許多實際任務(wù)上都表現(xiàn)優(yōu)良,也因此受到了很大關(guān)注,并且現(xiàn)在已經(jīng)出現(xiàn)了不少基于這類技術(shù)的工具,它們常以「深度學(xué)習(xí)即服務(wù)(DLaaS)」范式提供服務(wù)。但是,這些服務(wù)常會有隱私問題,比如假如用戶要使用 ChatGPT, 要么就需要用戶向服務(wù)提供商提供自己的私人 prompt,要么就需要服務(wù)提供商將自己專有的訓(xùn)練得到的權(quán)重配置交給用戶。
為了解決 Transformer 模型服務(wù)的隱私問題,一種解決方案是安全多方計算(Secure Multi-Party Computation),這可以在推理過程中保證數(shù)據(jù)和模型權(quán)重的安全。但是,多方計算(MPC)中簡單基礎(chǔ)的 Transformer 推理的時間成本和通信成本都很高,難以用于實際應(yīng)用。為了取得更好的效率,已經(jīng)有一些研究成果提出了多種加速 Transformer 模型安全推理的方法,但這些方法仍然存在以下一個或多個缺點:
- 替換很困難。近期一些工作提出,為了降低成本,可使用二次函數(shù)和 ReLU 函數(shù)等快速近似方法來替代高成本的 GeLU 和 softmax 等函數(shù)。但是,如果只是簡單替換這些函數(shù),可能會導(dǎo)致 Transformer 模型性能大幅下降(這可能就會需要額外再對模型進(jìn)行訓(xùn)練,即微調(diào))以及出現(xiàn)部署問題。
- 推理成本高。有研究提出使用更準(zhǔn)確的多項式函數(shù)來近似高成本的非線性函數(shù),但其近似方法并未考慮 GeLU 和 Softmax 的特殊性質(zhì)。因此,使用近似之后,這種方法的成本依然很高。
- 不容易部署。最近也有些研究提出通過修改 Transformer 的模型架構(gòu)來加速安全推理,例如分解嵌入過程并重新組織線性層。更糟糕的是,由于 Crypten 框架不支持安全 LayerNorm,因此如果僅使用 BatchNorm 模擬成本,就會導(dǎo)致安全推理得到不正確的結(jié)果。這些修改方式與現(xiàn)有的明文 Transformer 系統(tǒng)存在沖突。
綜上所述,在 MPC Transformer 推理領(lǐng)域,模型性能和效率難以兼得,而人們可能會有如下問題:
能否安全又高效地評估預(yù)訓(xùn)練大型 transformer 模型,同時無需進(jìn)一步再訓(xùn)練也能達(dá)到與明文模型相近的準(zhǔn)確度。
螞蟻集團提出的 PUMA 框架正是為了解決這一難題而生,該框架能夠安全又準(zhǔn)確地執(zhí)行端到端的安全的 Transformer 推理。這篇論文的主要貢獻(xiàn)包括:
- 用于近似非線性函數(shù)的新方法。文中提出了更加準(zhǔn)確和快速的近似方法,可用于近似 Transformer 模型中高成本的非線性函數(shù)(如 GeLU 和 Softmax)。不同于之前的方法,新提出的近似方法基于這些非線性函數(shù)的特殊性質(zhì),可以兼顧準(zhǔn)確度和效率。
- 更快更準(zhǔn)確的安全推理。研究者使用 6 個 transformer 模型和 4 個數(shù)據(jù)集進(jìn)行了廣泛的實驗,結(jié)果表明,相比于 MPCFORMER,當(dāng)使用 PUMA 框架時,準(zhǔn)確度在接近明文模型的同時,速度和通信效率都提高了 2 倍左右(并且注意 MPCFORMER 的準(zhǔn)確度不及 PUMA)。PUMA 甚至可以在 5 分鐘內(nèi)完成對 LLaMA-7B 的評估,生成一個詞。作者表示這是首次采用 MPC 評估如此大的語言模型。
- 開源的端到端框架。螞蟻集團的這些研究者成功以 MPC 形式設(shè)計并實現(xiàn)了安全的 Embedding 和 LayerNorm 程序。得到的結(jié)果是:PUMA 的工作流程遵照明文 Transformer 模型,并未改變?nèi)魏文P图軜?gòu),能夠輕松地加載和評估預(yù)訓(xùn)練的明文 Transformer 模型(比如從 Huggingface 下載的模型)。作者表示這是首個支持預(yù)訓(xùn)練 Transformer 模型的準(zhǔn)確推理的開源 MPC 解決方案,同時還無需再訓(xùn)練等進(jìn)一步修改。
PUMA 的安全設(shè)計
PUMA 概況
PUMA 的設(shè)計目標(biāo)是讓基于 Transformer 的模型能安全地執(zhí)行計算。為了做到這一點,該系統(tǒng)定義了三個實體:模型所有者、客戶端和計算方。模型所有者提供經(jīng)過訓(xùn)練的 Transformer 模型,客戶端負(fù)責(zé)向系統(tǒng)提供數(shù)據(jù)和收取推理結(jié)果,而計算方(即 P_0、P_1 和 P_2)執(zhí)行安全計算協(xié)議。注意模型所有者和客戶端也可以作為計算方,但為了說明方便,這里會將它們區(qū)分開。
在安全推理過程中需要保持一個關(guān)鍵的不變量:計算方開始時總是有客戶端輸入中三分之二的復(fù)制的機密份額以及模型的層權(quán)重中三分之二的權(quán)重,最終計算方也有這些層的輸出中三分之二的復(fù)制的機密份額。由于這些份額不會向各方泄漏信息,這就能確保這些協(xié)議模塊能以任意深度按順序組合起來,從而為任意基于 Transformer 的模型提供安全計算。PUMA 關(guān)注的主要問題是降低各計算方之間的運行時間成本和通信成本,同時維持所需的安全級別。通過利用復(fù)制的機密份額和新提出的 3PC 協(xié)議,PUMA 能在三方設(shè)置下讓基于 Transformer 的模型實現(xiàn)安全推理。
安全嵌入?yún)f(xié)議
當(dāng)前的安全嵌入(secure embedding)流程需要客戶端使用 token id 創(chuàng)建一個 one-hot 向量,這偏離了明文工作流程并會破壞 Transformer 結(jié)構(gòu)。因此,該方法并不容易部署到真實的 Transformer 模型服務(wù)應(yīng)用中。
為了解決這個問題,這里研究者提出了一種新的安全嵌入設(shè)計。令 token id ∈ [n] 且所有嵌入向量均表示為  ,則嵌入可以表示為
,則嵌入可以表示為 。由于 (id, E) 共享秘密,則新提出的安全嵌入?yún)f(xié)議的
。由于 (id, E) 共享秘密,則新提出的安全嵌入?yún)f(xié)議的 的工作方式如下:
的工作方式如下:
- 計算方在接受到來自客戶端的 id 向量后,安全地計算 one-hot 向量
 。具體來說,
。具體來說, 其中 i ∈ [n].
其中 i ∈ [n]. - 各計算方可以通過
 計算嵌入向量,其中
計算嵌入向量,其中 不需要安全截斷(secure truncation)。
不需要安全截斷(secure truncation)。
如此一來,這里的 Π_Embed 就不需要顯式地修改 Transformer 模型的工作流程。
安全 GeLU 協(xié)議
目前大多數(shù)方法都將 GeLU 函數(shù)看作是由更小的函數(shù)組成的,并會嘗試優(yōu)化其中每一部分,這就讓它們錯失了從整體上優(yōu)化私密 GeLU 的機會。給定 GeLU 函數(shù):
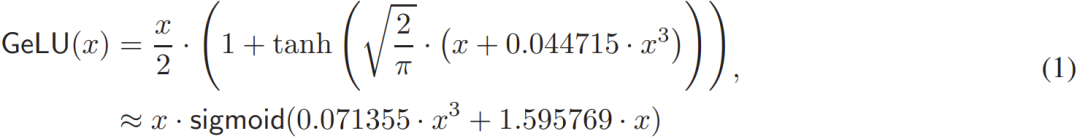
過去的一些方法關(guān)注的重心要么是 tanh 函數(shù)設(shè)計高效的協(xié)議,要么是將現(xiàn)有的求冪和倒數(shù)的 MPC 協(xié)議用于 Sigmoid。
但是,這些方法都沒有用到這一事實:GeLU 函數(shù)兩邊基本都是線性的,即當(dāng) x<?4 時 GeLU (x) ≈ 0,當(dāng) x>3 時 GeLU (x) ≈ x。研究者提出在 GeLU 的 [?4,3] 的短區(qū)間內(nèi),低次多項式的分段近似是一種更高效且更容易實現(xiàn)的安全協(xié)議選擇。具體來說,這個分段式低次多項式如下 (2) 式所示:

其中多項式 F_0 和 F_1 的計算是通過軟件庫 numpy.ployfit 實現(xiàn),如 (3) 式所示。研究者發(fā)現(xiàn),這種多項式擬合雖然簡單,但表現(xiàn)卻出人意料地好;實驗結(jié)果的最大誤差 < 0.01403,中值誤差 < 4.41e?05,平均誤差 < 0.00168。

從數(shù)學(xué)形式上講,給定機密輸入 ,新提出的安全 GeLU 協(xié)議
,新提出的安全 GeLU 協(xié)議 的構(gòu)建方式見如下算法 1。
的構(gòu)建方式見如下算法 1。

安全 Softmax 協(xié)議
在函數(shù) 中,關(guān)鍵的挑戰(zhàn)是計算 Softmax 函數(shù)(其中 M 可被視為一個偏置矩陣)。為了數(shù)值穩(wěn)定性,可以這樣計算 Softmax:
中,關(guān)鍵的挑戰(zhàn)是計算 Softmax 函數(shù)(其中 M 可被視為一個偏置矩陣)。為了數(shù)值穩(wěn)定性,可以這樣計算 Softmax:
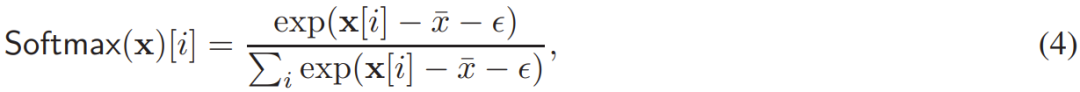
其中  是輸入向量 x 的最大元素。對于普通的明文 softmax,ε = 0。對于二維矩陣,則是將 (4) 式用于其每個行向量。
是輸入向量 x 的最大元素。對于普通的明文 softmax,ε = 0。對于二維矩陣,則是將 (4) 式用于其每個行向量。
算法 2 給出了新提出的安全協(xié)議 Π_Softmax 的詳細(xì)數(shù)學(xué)描述,其中提出了兩種優(yōu)化方法:

- 第一種優(yōu)化是將 (4) 式中的 ε 設(shè)置成一個非常小的正值,比如 ε=10^-6,這樣一來 (4) 式中求冪運算的輸入就都是負(fù)值。研究者利用了這些負(fù)操作數(shù)來提升速度。他們具體通過簡單的裁剪使用泰勒級數(shù)來計算其中的冪。
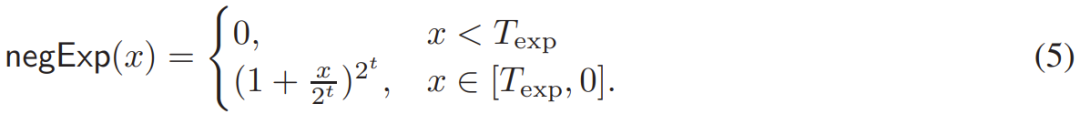
- 研究者提出的第二種優(yōu)化是降低除法量,這最終能降低計算和通信成本。為此,對于大小為 n 的向量 x,研究者將 Div (x, Broadcast (y)) 運算替換成了 x?Broadcast (1/y),其中
 。這種替換可以有效地將 n 次除法約簡至 1 次倒數(shù)運算和 n 次乘法運算。這種優(yōu)化對于 Softmax 運算尤其有益。在定點值設(shè)置下,Softmax 運算中 1/y 依然足夠大,難以維持足夠的準(zhǔn)確度。由此,這樣的優(yōu)化可以在保證準(zhǔn)確度的同時顯著降低計算和通信成本。
。這種替換可以有效地將 n 次除法約簡至 1 次倒數(shù)運算和 n 次乘法運算。這種優(yōu)化對于 Softmax 運算尤其有益。在定點值設(shè)置下,Softmax 運算中 1/y 依然足夠大,難以維持足夠的準(zhǔn)確度。由此,這樣的優(yōu)化可以在保證準(zhǔn)確度的同時顯著降低計算和通信成本。
安全 LayerNorm 協(xié)議
回想一下,給定大小為 n 的向量 x, ,其中 (γ, β) 是已訓(xùn)練的參數(shù),
,其中 (γ, β) 是已訓(xùn)練的參數(shù), 且
且  。在 MPC 中,關(guān)鍵挑戰(zhàn)是評估除以平方根公式
。在 MPC 中,關(guān)鍵挑戰(zhàn)是評估除以平方根公式  。為了安全地評估這一公式,CrypTen 的做法是按這個順序執(zhí)行這個 MPC 協(xié)議:平方根、倒數(shù)和乘法。但螞蟻集團的研究者觀察到
。為了安全地評估這一公式,CrypTen 的做法是按這個順序執(zhí)行這個 MPC 協(xié)議:平方根、倒數(shù)和乘法。但螞蟻集團的研究者觀察到  。而在 MPC 方面,計算平方根倒數(shù) σ^{-1/2} 的成本接近平方根運算的成本。此外,受前一小節(jié)中第二種優(yōu)化的啟發(fā),他們還提出首先計算 σ^{-1/2},然后廣播 Broadcast (σ^{-1/2}) 以支持快速和安全的 LayerNorm (x)。算法 3 給出了 Π_LayerNorm 協(xié)議的數(shù)學(xué)形式。
。而在 MPC 方面,計算平方根倒數(shù) σ^{-1/2} 的成本接近平方根運算的成本。此外,受前一小節(jié)中第二種優(yōu)化的啟發(fā),他們還提出首先計算 σ^{-1/2},然后廣播 Broadcast (σ^{-1/2}) 以支持快速和安全的 LayerNorm (x)。算法 3 給出了 Π_LayerNorm 協(xié)議的數(shù)學(xué)形式。

實驗評估

圖 1:在 GLUE 和 Wikitext-103 V1 基準(zhǔn)上的性能表現(xiàn),模型方面,a 是 Bert-Base,b 是 Roberta-Base,c 是 Bert-Large,d 包括 GPT2-Base、GPT2-Medium、GPT2-Large。

表 1:對于一個長度為 128 的輸入句,Bert-Base、Roberta-Base 和 Bert-Large 的成本。時間成本以秒計算,通信成本以 GB 計算。

表 2:GPT2-Base、GPT2-Medium 和 GPT2-Large 的成本。輸入句的長度為 32,這些是生成 1 個 token 的成本。

表 3:對于 {2, 4, 8, 16} 句子的批次,Bert-Base 和 GPT2-Base 的成本。Bert-Base 和 GPT2-Base 的輸入長度分別設(shè)定為 128 和 32,GPT2 的數(shù)據(jù)是生成 1 個 token 的成本。

表 4:不同輸入長度(#Input)下 Bert-Base 和 GPT2-Base 的成本。Bert-Base 和 GPT2-Base 的輸入長度分別設(shè)定為 {64, 128, 256, 512} 和 {16, 32, 64, 128}.GPT2 的數(shù)據(jù)是生成 1 個 token 的成本。

圖 2:GPT2-Base 生成不同輸出 token 的成本,輸入長度為 32。a 是運行時間成本,b 是通信成本。

表 5:用 LLaMA-7B 執(zhí)行安全推理的成本,#Input 表示輸入句的長度,#Output 表示所生成的 token 的數(shù)量。
只需五分鐘就能擴展用于 LLaMA-7B。研究者在 3 個阿里云 ecs.r7.32xlarge 服務(wù)器上使用 PUMA 評估了大型語言模型 LLaMA-7B,其中每個服務(wù)器都有 128 線程和 1 TB RAM,帶寬為 20 GB,往返時間為 0.06 ms。如表 5 所示,只需合理的成本,PUMA 就能支持大型語言模型 LLaMA-7B 實現(xiàn)安全推理。舉個例子,給定 8 個 token 構(gòu)成的輸入句,PUMA 可以在大約 346.126 秒內(nèi)以 1.865 GB 的通信成本輸出一個 token。研究者表示,這是首次使用 MPC 方案對 LLaMA-7B 實施評估。
PUMA雖然取得了一系列突破,但是它依然是一個學(xué)術(shù)成果,其推理耗時依然離落地存在一些距離。研究者相信未來與機器學(xué)習(xí)領(lǐng)域最新的量化技術(shù)、硬件領(lǐng)域量新的硬件加速技術(shù)相結(jié)合之后,真正保護(hù)隱私的大模型服務(wù)將離我們不再遙遠(yuǎn)。