小米集團基于Apache Doris的OLAP實踐

一、系統選型和應用現狀
首先來介紹一下小米集團OLAP系統選型與應用現狀。
1、系統選型

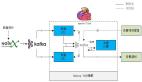
在小米內部,OLAP引擎主要的應用場景是BI看板和報表分析。早期通過引入Kylin來滿足面向主題式的報表分析的需求,當時沒有集團層面通用的BI平臺,都是各個業務部門自建自己的BI看板。后來小米決定要建立全集團通用的BI平臺,Kylin的靈活性就不太夠了,我們就需要做一次選型,選擇一款在各個業務場景之間更通用的OLAP方案,通過調研我們選擇了SparkSQL+Kudu+HDFS這種方案。
計算層使用了SparkSQL,存儲層使用了Kudu和HDFS。存儲層做了冷熱數據的分離,熱數據會寫入到Kudu,冷數據會存儲在HDFS。數據的存儲做了按天分區,每天會將Kudu的一部分數據轉冷,在晚上集群負載比較低的時候,將數據轉儲到HDFS。在查詢層做了Kudu和HDFS的聯合視圖,當用戶需要查詢看板的時候,就通過Spark SQL查詢Kudu和HDFS的聯合視圖,把查詢的結果通過看板進行展示。
早期這一方案在一定程度上能夠滿足小米的需求,但仍然存在一些問題,比如需要維護的組件過多,運維成本相對較高。另外,Spark底層是基于批處理的機制,數據在做Shuffle的時候,中間的結果可能需要落盤,就會導致使用SparkSQL查詢時性能相對較低。隨著小米內部業務的持續增長,對于OLAP 的需求越來越多,之前的方案在一些場景上已難以滿足業務需求,因此我們希望能夠選擇一款更加優秀的系統來替代之前的SparkSQL+Kudu+HDFS的架構。
經過調研,我們選擇了Apache Doris,這個系統是存算一體的,查詢性能也相對較好。小米內部在2019年的時候首次引入了Apache Doris,當時的版本還比較老,是一個非向量化的版本,數據在內存里是按照行存的形式來做計算的,所以就是沒有很好地使用到CPU的向量化計算的能力。早期這個系統在性能方面也能夠滿足業務需求,但隨著近幾年公司業務的快速發展,一些業務對OLAP系統的查詢性能提出了更高的要求,非向量化版本的查詢性能確實在一些場景上顯得捉襟見肘了。
在2022年的時候,我們又進行了一次系統選型,希望能夠引入更優秀的OLAP系統。我們調研了ClickHouse,它是一款非常優秀的OLAP系統。我們在小米內部也使用了實際業務進行了測試,測試結果是它的單表查詢性能非常好,但在多表查詢上還是不能滿足我們的業務需求。另外,數據導入方面, ClickHouse沒有事務來保證數據寫入的原子性。用戶如果有一部分數據寫入失敗并進行了重試,可能最終的數據就會出現部分數據的重復,這種情況在一些業務上是難以接受的,所以我們最終就放棄了 Clickhouse 的方案。
隨著Doris向量化版本的發布,且最近幾年Apache Doris社區也發展非常迅速,底層的引擎也進行了更新換代,支持了向量化的存儲和計算引擎。我們又進行了向量化版本的測試,當時在小米內部使用了Doris 1.1.2 這個版本在實際業務場景進行測試,發現相比之前的0.13這個非向量化版本,查詢的性能整體提升有1倍以上,在部分場景上查詢性能提升有3- 5倍。最終我們就選擇繼續留在了Apache Doris上,并推動了Apache Doris向量化版本的上線。
以上就是我們內部系統選型的歷史。
2、Apache Doris優勢

我們選型使用Apache Doris主要是因為Doris 有以下幾個方面的優勢:
首先,Doris查詢性能比較好,它的底層支持了比較多的索引,能夠提升查詢效率,用戶也可以創建物化視圖或者是RollUp 來加速查詢。當然在支持了向量化引擎以后,查詢的性能就更好了。
其次,我們選擇 Doris 是因為支持的是標準的SQL,對用戶使用非常友好,用戶可以使用 MySQL 客戶端直接連接 Doris 來進行查詢,用戶使用成本低。
Doris 的第三個優勢是它不依賴于外部的組件,運維非常簡單。另外,它對于分布式的支持比較好,可以很方便地進行集群的擴容和縮容。數據是多副本的存儲,如果有副本出現了異常,系統具有副本自動修復的能力。
我們選擇 Doris 的最后也是最重要的一個原因,就是它完全開源,社區比較活躍,便于后期的維護和升級。現在Apache Doris 背后也有商業化公司的支持,我們內部線上服務遇到的問題,如果內部不能自己解決,也能夠很快得到社區的支持,幫助我們解決。
以上這些就是我們選擇Apache Doris的主要原因。
3、應用現狀

我們在2019年的時候引入Doris,經過幾年的發展,目前 Doris 在小米內部已經得到了非常廣泛的應用,比較核心的、較大的業務有幾十個,還有數百個小一些的業務。
內部使用Doris比較大的業務,包括用戶行為分析、AB實驗、用戶畫像、小米造車、小米有品、新零售、天星數科、廣告投放、廣告BI和智能制造等等。Doris 的集群在我們內部現在有數十個,其中最大的集群有 99 個 Be 節點, 3 個 Fe 節點,集群的規模比較大。最大的集群每天有幾十個流式的數據導入任務,單表每天最大的數據增量有 120 億,這個集群每天能夠承擔2萬次以上的有效查詢。
二、小米數據生態中的Doris
在第二部分,將介紹小米內部數據生態中的Doris。
1、小米BI平臺架構

在小米內部,Doris 的一個較大的應用場景是作為BI 平臺的底層的數據源。在 BI 平臺底層,除了使用 Doris 作為數據源之外,還有MySQL、 Hive 和Iceberg。MySQL 和 Doris 主要面向的是實時分析的業務場景,MySQL 針對的是數據量比較小,但是查詢非常敏感,要求查詢延遲非常低的業務。相比于MySQL ,Doris 面向的是大數據量的業務,查詢的延遲要求比 MySQL 可能會稍微低一些,一般支持的是秒級的查詢延遲。Hive 和 Iceberg 主要針對的是數據量更大、離線分析的場景。
在小米的 BI 平臺,用戶可以直接在語義模型層通過拖拽組件或者是編寫 SQL 的方式進行語義建模,模型創建完成之后就可以對數據源進行分析查詢,并且把查詢的結果在看板上進行可視化展示。語義模型層除了支持拖拽組或編寫 SQL 來建模之外,還支持了指標和維度定義、日期轉換、函數處理等一些比較復雜的能力。
另外,在語義模型層,也支持了查詢的自動加速。用戶在創建看板的時候選擇了 Hive 或Iceberg作為數據源,同時選擇使用 Doris 進行查詢加速,那么用戶創建好看板之后,就會由平臺生成數據同步任務,根據用戶看板的數據分析需求,使用 Spark或Presto查詢Hive或Iceberg生成中間表,再把中間表數據導入到 Doris 里。用戶在查詢看板的時候就不用直接通過Presto或Spark來查 Hive 或Iceberg的數據了,可以直接路由到 Doris 查詢中間表的數據,進行加速查詢。
小米 BI 平臺除了支持PC 端看板,也支持了移動端看板。小米內部也引入了Apache Kyuubi組件,主要是盡量對上層的用戶屏蔽底層的具體查詢引擎。之前每一個查詢引擎都是上層用戶直連的,引入Kyuubi之后可以提供統一的 SQL 入口,由Kyuubi進行具體引擎的連接。當然對于歷史的、直接使用 Doris 的用戶場景,還是支持上層業務通過 JDBC 的方式來連接Doris進行分析查詢。
這就是Doris在小米 BI 平臺的使用情況。
2、數據工場

小米內部使用了數據工場對底層的存儲和計算引擎進行了封裝。數據工場是小米自研的一款面向數據開發和數據分析人員的數據平臺,底層集成了Doris、Iceberg、Hive、MySQL、Kudu等的存儲能力,同時也集成了Spark、Flink、Presto等的計算能力,對底層的存儲和計算能力進行了統一的封裝,提供給集團各個業務來進行數據的存儲和計算。數據工場對底層的這些存儲和計算引擎也提供了統一的元數據管理、統一的權限管理、數據作業管理以及數據治理的能力。
3、統一元數據管理
對于底層的每一個存儲和計算引擎,在數據工場都做了統一的元數據管理,由數據工場給上層的業務提供了統一的元數據視圖。比如對于Doris來說,底層的元數據就包括Doris服務信息、集群信息、庫信息、表信息和分區信息,在統一元數據管理系統提供的元數據視圖就是“doris.集群名.庫名.表名.分區名”。通過這種方式對上層服務提供了統一的元數據視圖。通過元數據管理對所有的存儲資源可以進行統一管理,形成了統一的資源視圖,可以對所有的資源變更和訪問進行有效的審計。對于每一次Doris集群的查詢或寫入訪問,都可以在元數據管理系統里進行記錄和審計。
4、統一權限管理

底層不同的引擎可能具有不同的權限體系,Doris使用的是用戶名和密碼的方式進行鑒權、小米內部的Hive使用的是Kerberos的方式來鑒權、小米內部的Talos這種自研的消息隊列使用的是AKSK這種方式來進行鑒權。
為了對上層用戶屏蔽底層不同系統的權限體系,小米在數據工場做了權限的代理,給上層用戶提供統一的權限管理能力。在數據工場引入了用戶空間這一概念,在用戶空間下包含不同的用戶,每一個用戶都具有不同的角色。owner角色是用戶空間的所有者,這個用戶空間下發生的所有賬單都會掛在 owner 所在的團隊下面;Admin角色是用戶空間的管理者,可以增加或者是刪除用戶;Dev這個角色是普通的用戶,可以訪問這個用戶空間下所有的存儲和計算的引擎。用戶不需要針對每一個引擎使用不同的鑒權體系來進行鑒權,而是由用戶空間進行權限的代理,比如用戶需要在數據工場查詢某一個 Doris 表,不需要自己傳入用戶名和密碼,員工 ID 就會和這個用戶空間進行綁定,員工查詢的時候會由他所在的用戶空間去查詢自己所擁有的表的用戶名和密碼,代替用戶進行鑒權。
如果有業務想接入Doris,就需要在數據工場提交建庫的申請,他需要選擇具體的集群名稱,描述自己的業務場景,提供查詢的延遲要求,提供預估的數據量。當用戶提交了請求之后,Doris運維的同學就會收到用戶提交的建庫請求,然后針對建庫請求里的場景信息,進行審批,同時給用戶提供一些使用方面的指導。用戶完成建庫審批之后,就可以直接在對應的集群上去做建表的操作了。建表的操作可以直接在數據工場來提交,可以通過DDL 的方式寫SQL來建表,也可以通過可視化的方式來選擇建表。用戶建好表之后就可以進行數據的寫入和數據查詢了。
5、數據作業管理

小米的數據工場也提供了數據作業管理的能力,比如用戶數據需要從業務側寫到 Doris ,可以在數據工場直接提交數據寫入的作業,用戶數據會首先寫入到小米自研的消息隊列Talos里,再從 Talos寫到各個不同的系統里。
如果用戶的數據是離線數據,會先寫到Hive或者Iceberg里,如果是實時數據,就會經過Flink或Spark做一些簡單的處理,再通過Stream Load的方式寫到Doris里面來。如果用戶的離線數據是在 Hive里,后期想把數據同步到 Doris 里進行分析查詢,就可以直接在數據工場提交Broker Load作業,把Hive的表數據通過Broker Load 的方式寫入到Doris,也可以通過在數據工場寫 FlinkSQL或者是SparkSQL的方式,從 Hive或Iceberg里查數據,然后把查到的數據通過 Stream Load 的方式寫入到Doris里。FlinkSQL和SparkSQL底層其實是對Doris的Stream Load數據寫入方式進行了封裝,通過Stream Load的方式把數據并發地寫入到Doris里面。
6、數據治理

小米針對 Doris 也提供了數據治理的能力,包括數據安全管理,數據質量管理,數據成本管理。
數據安全管理方面,我們會定期去掃 Doris 全量集群的庫和表,對每一個字段進行安全等級的定義,對于隱私級別高的數據,需要做加密的存儲或者在網絡層面進行隔離。
數據質量管理,就是針對服務的可用性進行持續地監測和治理,對于一些可用性方面的隱患進行持續跟進,并與不同的用戶進行 SLA 的確定和握手。
數據成本管理,主要是做數據的分層存儲以及數據生命周期的管理,把常用的數據分區保存在Doris上,把一些歷史的、不常訪問的分區從 Doris 里刪除,這些數據在Hive或者Iceberg上面是有備份的。有了這種數據生命周期的管理,能夠極大地降低Doris存儲的成本,通過數據治理來實現數據安全、服務可靠和成本降低的目標。
三、小米用戶行為分析實踐
在第三部分,向大家介紹一下Doris在小米用戶行為分析場景的實踐。
1、小米用戶行為分析平臺

小米的用戶行為分析平臺是一個基于海量數據的一站式、全場景、多模型、多維度、自助式和可視化的分析平臺。平臺底層可以對接不同的業務數據,所以它是一個通用的分析平臺。在集團內部需要做用戶行為分析的業務都可以接入到這個平臺來進行分析。這個平臺目前支持了事件分析、留存分析、漏斗分析、分布分析和路徑分析等分析方式。平臺用戶在小米用戶行為分析平臺根據分析需求配置查詢任務,生成SQL,并下發給Doris引擎執行分析查詢,并將查詢結果在平臺進行可視化展示。
2、事件模型

業務要做行為分析,數據源主要是來自于各個業務在網頁或者APP上面的埋點數據。用戶在網頁或者APP上面的各種操作都會抽象成一個事件的實體,這個事件實體稱為事件的模型。小米的用戶行為分析平臺主要是基于事件模型進行建模。
事件模型主要包含五個要素,分別是Who、When、Where、How和What。Who 表示這次事件是誰觸發的,在 Doris 的表中會對應一個字段,即用戶ID;When 表示事件觸發的時間,在Doris表里對應的字段是一個時間戳,一般會精確到毫秒級別;Where表示事件觸發的地點,這個字段在Doris表里對應的字段可能是通過 IP 解析出來的省份或城市;How表示這個事件是通過什么方式來觸發的,一般是 APP 的版本號或者瀏覽器,或者是用戶手機的信息等等;What表示這個事件到底是什么類型的事件,比如它是一個 APP 的下載事件,或者是音樂的播放事件,或者是一個點擊事件等等。這就是我們進行用戶行為分析的一個事件模型。
3、事件分析

在小米業務中,進行用戶行為分析最多的方式是事件分析。事件分析也包含了三個要素,分別是事件、指標和維度。平臺用戶可以針對不同的事件、指標、維度去做靈活的組合。事件就是用戶在網頁或者是 APP 上面的行為,表示業務的過程。指標是具體的數值,比如頁面的訪問量、訪問的時長等等。要做事件分析,就需要數據的實時采集,事件的實時分析,事件、維度和指標的靈活選擇。通過事件分析能夠研究到某個行為發生對業務的影響以及影響的程度。

這里舉一個簡單的例子,在小米的用戶行為分析平臺,要做事件分析,需要選擇具體的分析數據源,這個數據源對應了一張Doris表,然后需要選擇事件、維度和指標。如上圖中所示,要做事件分析,先選擇事件分析的時間,比如5月30號的0點到5月30號的 23 點,針對某一個 APP 按小時來統計下載這個事件觸發的用戶數。
我們在這個頁面上執行事件、維度和指標的選擇之后,點擊查詢,系統中就會生成一條SQL,接著由平臺下發SQL到 Doris 系統進行查詢,再把查詢結果返回給平臺,平臺再根據結果做可視化的展示。我們可以在圖中看到明顯的變化趨勢。
4、留存分析

小米的用戶行為分析平臺也支持做留存分析。留存分析是一種用來分析用戶參與情況和活躍程度的分析模型,能夠考察進入初始行為的用戶中有多少人進行了后續的行為。留存分析也是用來衡量產品對于用戶價值高低的重要方法。

為了支持留存分析,我們基于Apache Doris 的聚合函數的框架,開發了兩個聚合函數,分別用來計算單用戶的留存數據和全量用戶的留存數據。
單用戶的留存函數retention_info(),可以傳入以下幾個參數:第一個參數start_time,只有在這個時間之后發生的事件,我們才認為是有效的事件。在這個時間點之前的事件都可以忽略;第二個參數是unit,是留存分析的時間單位,現在支持的主要是按天來做留存,所以這個參數可以傳入“day”的字符串;第三個參數就是event_time,每一個事件發生的時間可以通過這個參數傳進去;第四個參數是 event_type,用來判斷傳入的這個事件是初次事件,還是留存事件。
前面圖片示例中的SQL,在內層查詢里是按照distinct_id來做的分組,每一個distinct_id對應的是一個用戶,所以內層查詢能夠計算出每一個用戶的留存數據。我們在這個例子里,可以看到傳給retention_info的實參,把view作為初次事件,buy作為留存事件,在傳入事件類型的時候,初次事件傳1,留存事件傳2,對于不屬于初次事件也不屬于留存事件的其它事件,傳入的就是0。通過內層查詢我們就可以計算出每一個用戶實際的留存數據,再結合外層的查詢 retention_count()做一次聚合,最終計算出全量用戶的留存數據。

上圖是小米用戶行為分析平臺進行留存分析的一個示例,也是需要選擇數據源,數據源對應一個具體的業務,在Doris引擎里邊對應了一張具體的表,我們需要在這個頁面上選擇初始行為是什么,后續行為是什么,以及留存的時間是7日的留存還是 14 日的留存,還要選擇留存分析的時間范圍。在這個實例中,我們選擇了最近 14 天,點擊查詢之后就會生成一條SQL,這條 SQL 就是我們前邊看到的,由我們自定義的兩個聚合函數來進行留存分析的查詢,然后查詢下發到Doris引擎來執行,查到的結果返回給用戶行為分析平臺,進行可視化的展示。
不同顏色的線表示的是初始行為發生的日期,每一條線表示的是初始行為發生之后,在第 0 天、第1天、第2天、第3天分別的留存率。第 0 天就是發生了初始行為的當天就發生了留存事件的用戶的留存率,第1天就表示初始行為發生日期的后一天發生了留存事件的用戶留存率。
5、漏斗分析

小米的用戶行為分析平臺支持漏斗分析。漏斗分析是一種用來分析用戶行為狀態變化從起點到終點各個階段用戶轉化率的分析模型。我們可以跟蹤漏斗的整個轉化過程,在這個轉化過程里,都是以用戶為單位,將用戶的步驟串聯起來,并不是把每一個步驟發生的次數做一次簡單的計數,需要確保進入到后續步驟中的用戶一定是完成了所有的前序步驟。通過漏斗分析,可以了解用戶在漏斗的哪一步流失的最多,以及不同類型用戶轉化的情況。
上圖右側是一個簡單的漏斗分析模型。漏斗定義了三個步驟,有 100 個用戶觸發了步驟1,其中又有 60 個用戶觸發了步驟2,這60個用戶中又有 20 個用戶觸發了步驟3。我們可以看到,從步驟 1 到步驟 2 用戶的轉化率是60%,流失率是40%,從步驟 2 到步驟 3 用戶的轉化率是33%,流失率是67%。完整的漏斗,總體轉化率只有20%,總體的流失率達到了80%。

為了支持漏斗分析,我們基于Apache Doris 的聚合函數框架開發了兩個聚合函數,分別用來計算單個用戶在漏斗的各個階段的事件數據和全量用戶在漏斗各個階段的轉化率。計算單個用戶在漏斗各個階段的事件數據的聚合函數是 funnel_info(),在這個函數中我們可以傳入以下幾個參數,第一個參數 start_time是我們要進行漏斗分析的起始時間,在這個時間之后的事件才是有效的事件;第二個參數time_window,是有效窗口期,從發生了漏斗第一個步驟的事件開始,在這個窗口期內完成了漏斗所有步驟的用戶,才算是完成了一次完整的轉化;第三個參數step是我們要傳入的事件是漏斗的哪一個步驟的事件;第四個參數是event_time是事件發生的具體時間。
圖中的 SQL就是用來做漏斗分析的,使用到了兩個聚合函數。內層的查詢是按照distinct_id進行了分組,每一個distinct_id對應一個用戶。然后我們定義了一個漏斗,包含四個步驟,view作為第一個步驟, open 作為第二個步驟, buy 作為第三個步驟, use 作為第四個步驟。在內層查詢里就可以計算出每一個用戶在漏斗各個階段的事件數據,然后將這些用戶的事件數據再交給外層查詢,由 funnel_count() 這個聚合函數進行聚合分析,最終計算出全量用戶在漏斗各個階段的轉化情況。

要使用小米的用戶行為分析平臺進行漏斗分析,首先需要創建漏斗。創建漏斗就需要選擇窗口期,用戶觸發完第一個步驟之后,只有在這個窗口期內完成整個漏斗的所有步驟才算作是完成了一個完整的轉化。創建漏斗還需要定義漏斗的所有步驟,漏斗中至少會包含兩個步驟,每一個步驟對應一個事件。創建好漏斗之后,就可以進行漏斗分析了。

在小米的用戶行為分析平臺,首先需要選擇數據源,數據源對應了一個具體的業務,在Doris中對應了一張具體的表;然后可以選擇創建好的一個漏斗模型;接著再選擇時間,比如進行最近7天的漏斗分析;最后點擊查詢,會生成一條SQL,SQL使用到了我們自定義的兩個聚合函數。平臺會把SQL下發給Doris引擎進行查詢,平臺獲取到查詢結果之后做一些簡單的處理,然后進行可視化展示。
在這個示例中,漏斗包含了四個步驟,分別是曝光、滑動、下載和激活。可以看到,在第一個步驟和第二個步驟之間,用戶的轉化率是 26.51%;在第二個步驟和第三個步驟之間,用戶的轉化率是67%;在第三個和第四個步驟之間,用戶的轉化率是65%。用戶的總體轉化率是 11.68%。也可以看到在第一個步驟和第二個步驟之間,用戶的流失率是最高的。觸發了曝光事件之后,有很大一部分用戶沒有觸發滑動這個事件,我們就需要根據計算出來的這些數據去具體地分析用戶在這兩個階段之間流失的具體原因,然后對我們的系統或者產品做進一步的優化。漏斗分析為我們的系統優化提供了依據。
6、路徑分析

小米用戶行為分析平臺支持了路徑分析,用來分析用戶在使用產品時的路徑分布的情況,可以洞察到用戶全生命周期的行為特征,可以通過可視化用戶流全面來了解用戶整體的行為路徑。通過路徑分析,我們可以挖掘出用戶頻繁訪問的路徑有哪些,可以尋找用戶在單個環節流失的具體原因,為產品優化提供依據。

為了支持路徑分析,我們也是基于Apache Doris 的聚合函數框架開發了兩個聚合函數,分別用來計算單個用戶的路徑統計數據和全量用戶的路徑統計數據。在第一個聚合函數 session_del()中可以傳入以下參數:event_name是事件名稱;event_time 是事件發生的時間;session_interval 是事件的時間間隔,一個用戶連續的兩次事件發生的時間如果超過了我們指定的這個時間間隔,就需要把這兩個時間從中間切分開,不能把它們作為同一個路徑,而是分為兩個路徑;target_event_name 參數是目標事件,一般會選擇一個具體的事件作為路徑的起始事件或者是終止事件,就是通過這個參數來設定的;參數is_reverse表示前面選擇的target_event_name是路徑的起始事件還是路徑的終止事件;參數max_level 定義的一個路徑最長包含的事件數量。
要去做路徑分析,一般會選擇一個時間范圍,很少對全量數據去做路徑分析。在SQL的內層查詢里使用distinct_id進行分組,每一個 distinct _id對應的一個用戶,通過內層查詢就可以計算出單個用戶的路徑統計數據。然后將所有用戶的路徑統計數據再交給外層的查詢,通過 session_count ()這個聚合函數來做計算,得到全量用戶的統計數據。
7、分布分析

小米的用戶行為分析平臺也支持了分布分析,這種方式是指用戶在特定指標下的頻次、總額等特征的結構化的分段展現。通過分布分析可以洞察到數據的分布特征,判斷極端數值的占比,了解業務的健康程度。

上圖就是進行分布分析的一個示例。首先選擇具體的數據源,數據源對應一個具體的業務,也是在Doris引擎中對應了一張具體的表;然后選擇分布分析的指標和維度,比如時間選擇了2023年5月31號到6月1 號這兩天的時間范圍,我們要進行的是瀏覽的總次數分布的計算;另外還需要選擇數據分布的區間,這里我們使用了默認的區間,用戶也可以自定義區間。點擊查詢就會生成一條SQL,把 SQL 下發到Doris引擎進行查詢,然后查詢的結果會由小米用戶行為分析平臺進行一些簡單的處理,并進行可視化的展現。
可以看到,在這兩天的瀏覽事件,總次數分布在 10-30 次這個區間里的用戶數是最多的,通過這種方式進行分布分析。
四、未來規劃
最后簡單介紹一下小米未來在Doris方面的規劃。

首先,Doris的資源隔離能力不是很好,穩定性還存在一些問題,公共集群上的業務會比較多,可能一個大查詢就會占滿整個集群資源,影響到其它業務的使用,所以我們希望重點提升 Doris 的穩定性,并且在公共集群上支持大查詢的定位和攔截的能力。
另外,小米在部分業務上線了 Doris 的向量化版本,目前內部使用的 Doris 向量化版本是1.1.2,用戶反饋總體查詢性能提升比較明顯,所以后期我們會推動全量的 Doris 集群上線向量化版本。
其次,小米內部對于 OLAP 分析的需求仍在增長,我們還會在小米手機、小米造車等一些核心的業務上來推廣Doris。
最后,目前小米內部高性能 OLAP 查詢主要還是使用Doris,后面可能還會探索引入一些其它系統來解決不同業務場景的問題,我們需要盡可能對用戶屏蔽底層引擎的信息,盡量減少對業務的影響,所以我們還會探索統一SQL入口的解決方案。