優秀系統設計背后的思考:API 速率限制服務系統

API 速率限制器是一個用于控制應用程序或服務對API請求的頻率的服務。速率限制通常用于控制資源的使用、防止濫用和維護服務的穩定性。
類似的產品有:Express Rate Limit、Spring Boot Rate Limiter、Ratelimiter
難度級別:中等
1、什么是API速率限制服務?
想象一下,我們有一個服務正在接收大量請求,但它每秒只能處理有限數量的請求。為了處理這個問題,我們需要某種節流或速率限制機制,只允許一定數量的請求,這樣我們的服務就能對所有請求進行響應。從高層次來看,速率限制器限制了一個實體(用戶、設備、IP等)在特定時間窗口內可以執行的事件數量。例如:
- 一個用戶每秒只能發送一條消息。
- 用戶每天只能有三次信用卡交易失敗。
- 單個IP每天只能創建二十個賬號。
總的來說,速率限制器限制了發送者在特定時間窗口內可以發出的請求數量,當達到上限時,它會阻止請求。
2、為什么需要API速率限制?
速率限制的作用就好比是給你的服務穿上一件“防彈背心”,能夠抵御一些惡意攻擊,比如拒絕服務攻擊,暴力破解密碼或者信用卡信息等。這些攻擊往往像海量的HTTP/S請求砸過來,表面上看似乎是真實用戶在操作,實則可能是機器人在背后操控,因此這種攻擊更加難以發現,也更有可能導致你的服務、應用或API被拖垮。
另外,速率限制還能幫助我們節省開支,降低維護網絡設施的費用,避免垃圾郵件和網絡騷擾。以下是一些能從速率限制中獲益,使服務或API更穩定可靠的情況:
- 控制不守規則的客戶端或腳本:有些用戶或者腳本可能會一股腦兒地發送大量請求,這無論是故意還是無意,都可能讓你的服務受不了。另外,有些用戶可能會頻繁地發送一些不那么重要的請求,我們得確保這種行為不會影響到重要的流量。比如,有的用戶可能頻繁地請求數據分析,我們不能讓這種行為妨礙到其他用戶的重要操作。
- 提升安全性:例如我們可以限制用戶在雙重認證中嘗試密碼的次數,避免密碼被嘗試破解。
- 防止濫用和不合理的設計實踐:如果我們對API的使用沒有限制,開發者可能會懶散下來,比如反復請求同樣的信息,這樣不僅浪費資源,也不符合好的開發習慣。
- 控制成本和資源使用:我們的服務通常是為正常使用情況設計的,比如一個用戶每分鐘發一篇帖子。如果沒有限制,一些計算機可能會一秒鐘就通過API推送成千上萬條信息。所以我們需要用速率限制來控制API的使用情況。
- 提高收入:某些服務可能會根據用戶的付費級別來限制他們的操作,這樣就能根據限制來產生收入。例如,我們可以對所有的API設定一個默認的使用上限,如果用戶想要更多使用權,就需要付費升級。
- 避免流量突增:確保服務即使面臨大量請求,也能繼續正常為其他用戶提供服務。
3、系統需求和目標
我們的流量控制器需要達到以下要求:
功能要求:
- 限制一個實體在一段時間內可以向API發送的請求次數,例如每秒鐘15次請求。
- API是通過集群來提供的,所以限流應該在整個集群中進行,跨服務器的請求都應納入考慮。無論是在單臺服務器還是在多臺服務器上,只要超過了預設的閾值,用戶都應該看到一個錯誤信息。
非功能要求:
- 系統是高可用。流量控制器需要隨時待命,因為它是我們的服務對抗外部攻擊的重要工具。
- 我們的流量控制器不應引入過多的延遲,以避免影響用戶體驗。
4、怎樣進行流量控制?
流量控制其實就是設定用戶可以多快、多頻繁地訪問API的規則。在一段時間內,限制客戶對API的使用叫做"節流"。節流可以在應用層面或者API層面進行。一旦超出節流限制,服務器就會返回HTTP的"429 - 請求過多"狀態碼。
5、節流的類型有哪些?
以下是三種常見的節流類型,都被不同的服務使用過:
- 硬節流:API請求的次數絕對不能超過節流的限制。
- 軟節流:這種類型下,我們可以設定API請求的次數超過一定比例。例如,如果我們的流量限制是每分鐘100條消息,并且允許超過10%,那么我們的流量控制器每分鐘最多會允許110條消息。
- 彈性或動態節流:在彈性節流下,如果系統有剩余資源,那么請求次數就可以超過設定的閾值。例如,如果用戶每分鐘只能發100條消息,那么在系統有剩余資源的情況下,我們可以讓用戶每分鐘發送超過100條消息。
6、用于流量控制的都有哪些算法?
常用的流量控制算法有兩種:
固定窗口算法:在這種算法中,時間窗口是從時間單位的開始到時間單位的結束。比如說,對于一個分鐘,無論API請求在什么時候發出,我們都會看作是在0-60秒這個時間段內。比如在下面的圖示中,0-1秒之間有兩條消息,1-2秒之間有三條消息。如果我們的流量限制是每秒鐘兩條消息,那么這個算法只會控制'm5'。
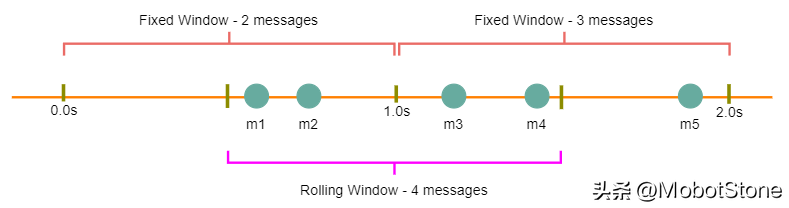
滑動窗口算法:在這個算法中,時間窗口從發出請求的那一刻開始,再加上窗口的長度。例如,如果在一秒的第300毫秒和第400毫秒各發送了一條消息,我們會把這兩條消息看作是從這一秒的第300毫秒開始到下一秒的第300毫秒之間的兩條消息。在上面的例子中,如果流量限制是每秒鐘兩條消息,我們就會控制'm3'和'm4'。
7、流量控制器的整體設計
流量控制器的職責是判斷哪些請求將由API服務器接收,哪些請求將被拒絕。當新的請求來臨時,Web服務器首先向流量控制器詢問這個請求應該被接收還是應該被拒絕。如果請求沒有被拒絕,那么它就會被發送到API服務器進行處理。
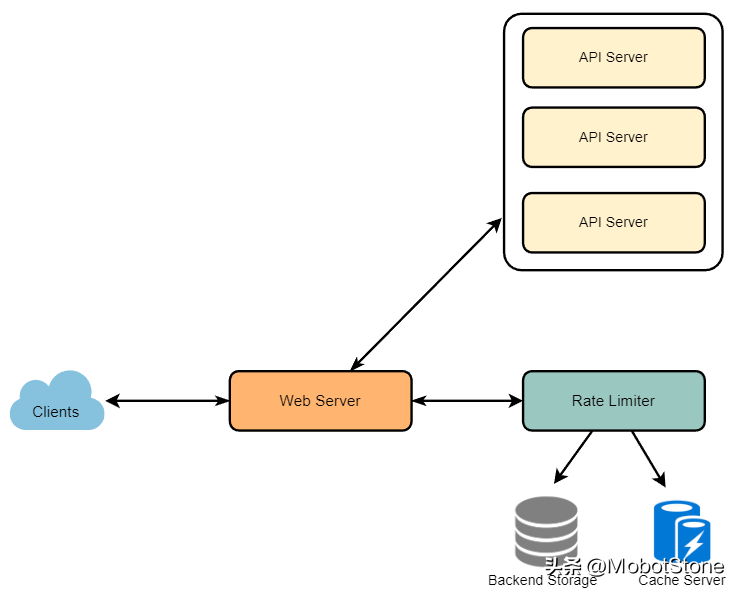
8、基本的系統設計和算法
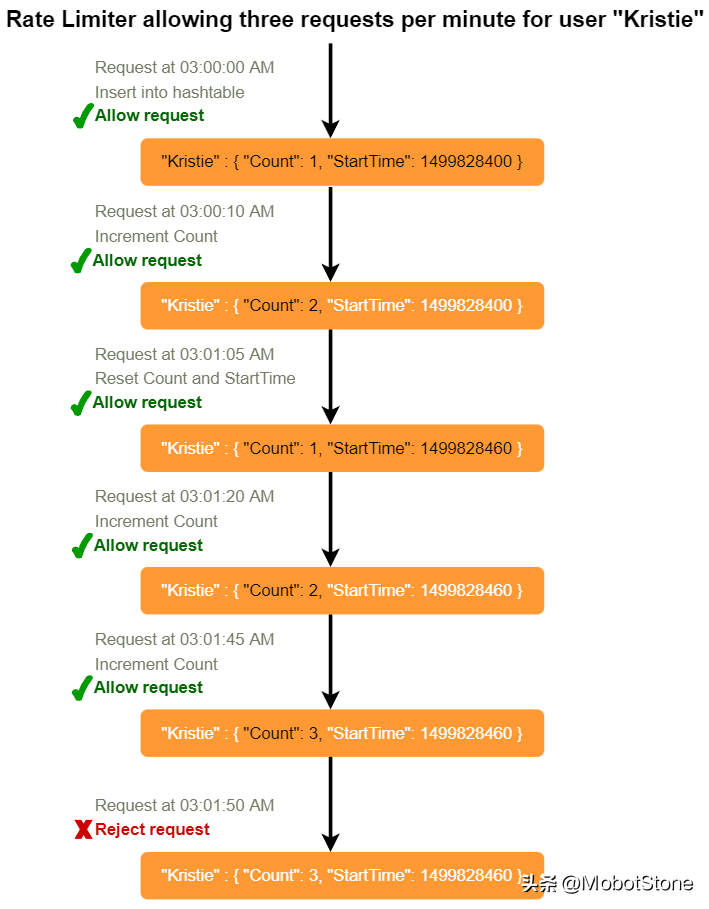
我們以每個用戶的請求次數限制為例。在這種場景下,我們為每個用戶設置計數器,記錄用戶已經發出了多少個請求,以及我們開始計數請求的時間戳。我們可以將這些信息存放在一個哈希表中,其中'key'是'UserID','value'是一個包含一個用于'Count'的整數和一個用于Epoch時間的整數的結構:

假設我們的流量控制器允許每個用戶每分鐘發出三個請求,那么每當有新請求進來,我們的流量控制器將執行以下步驟:
- 如果'UserID'在哈希表中不存在,將其插入,將'Count'設為1,將'StartTime'設為當前時間(規范化為分鐘),然后允許該請求。
- 否則,找到'UserID'的記錄,如果 CurrentTime – StartTime >= 1分鐘,將'StartTime'設為當前時間,'Count'設為1,并允許請求。
- 如果 CurrentTime - StartTime <= 1分鐘,且 如果 'Count< 3',增加計數并允許請求。 如果 'Count>= 3',拒絕請求。
我們的算法存在什么問題?
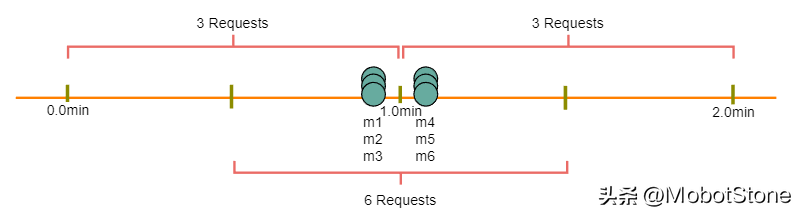
- 固定窗口算法:因為我們在每分鐘結束時重置'StartTime',這意味著可能每分鐘允許兩倍數量的請求。假設一個用戶在一分鐘的最后一秒發送了三個請求,然后她在下一分鐘的第一秒立即發送了三個更多的請求,這就導致在兩秒內有6個請求。這個問題的解決方案是滑動窗口算法,我們稍后將討論。
- 原子性:在分布式環境中,“讀-然后-寫”的行為可能會產生競態條件。假設用戶當前'Count'是"2",并且她發出了兩個或者更多的請求。如果這兩個請求由兩個獨立的進程處理,并且在任何一個進程更新它之前同時讀取了Count,那么每個進程都會認為用戶還能有一個請求,并且她還沒有達到速率限制。

如果我們使用Redis來存儲我們的鍵值,解決原子性問題的一個解決方案是在讀取-更新操作期間使用Redis鎖。然而,這將以降低同一用戶的并發請求速度和增加另一層復雜性為代價。我們可以使用Memcached,但是它會有相似的問題。
如果我們使用簡單的哈希表,我們可以對每條記錄進行鎖定以解決我們的原子性問題。
我們需要多少內存來存儲所有的用戶數據呢?讓我們假設一個簡單的解決方案,即我們將所有的數據保存在一個哈希表中。
假設'UserID'需要8 bytes。我們也假設一個2 bytes的'Count',可以計數到65k,對我們的使用場景來說已經足夠了。盡管epoch時間需要4 bytes,我們可以選擇只存儲分鐘和秒部分,這可以用2 bytes來存儲。因此,我們需要總共12 bytes來存儲用戶的數據:
8+2+2=12bytes
假設我們的哈希表每條記錄需要額外20 bytes的開銷。如果我們需要在任何時候跟蹤一百萬用戶,我們需要的總內存是32MB:
(12+20)bytes?1millinotallow=>32MB
如果我們假設需要一個4-byte的數來鎖定每個用戶的記錄以解決我們的原子性問題,我們將需要總共36MB的內存。
這可以輕松地放在一臺服務器上;然而我們不希望將所有的流量都路由到一臺機器上。此外,如果我們假設一個速率限制為每秒10個請求,那么這將對我們的流量控制器產生1000萬QPS!這對一臺服務器來說太多了。實際上,我們可以假設我們將在一個分布式環境中使用類似Redis或Memcached這樣的解決方案。我們將所有的數據存儲在遠程的Redis服務器中,所有的流量控制器服務器將在處理或節流任何請求之前讀取(和更新)這些服務器。
9、Sliding Window(滑動窗口)算法
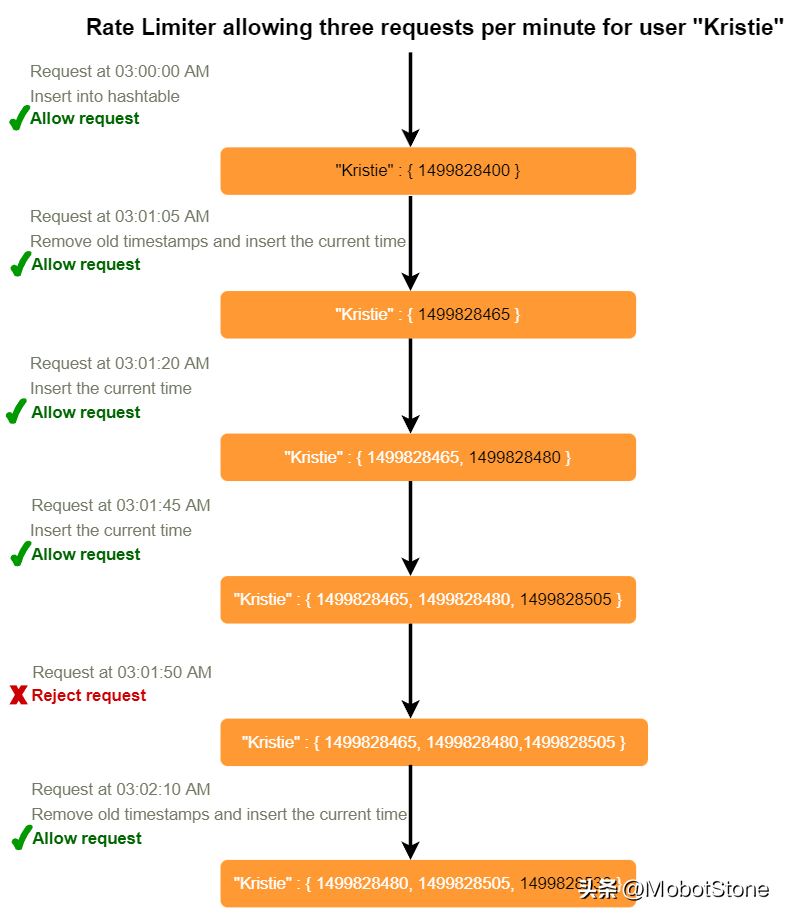
如果我們能夠追蹤每個用戶的每個請求,我們就可以維護一個滑動窗口。我們可以在哈希表的'value'字段中的Redis Sorted Set(有序集合)中存儲每個請求的時間戳。

假設我們的速率限制器每分鐘每用戶允許3個請求,那么,每當有新請求進來,速率限制器將執行以下步驟:
- 從Sorted Set中移除所有早于"CurrentTime(當前時間) - 1分鐘"的時間戳。
- 計算Sorted Set中元素的總數。如果這個計數大于我們的閾值"3",則拒絕請求。
- 在Sorted Set中插入當前時間并接受請求。
我們使用滑動窗口,要存儲所有用戶的數據需要多少內存呢?假設'UserID'需要8 byte。每個epoch時間將需要4byte。假設我們需要每小時500個請求的速率限制。假設哈希表有20 byte的開銷,Sorted Set有20 byte的開銷。最多,我們需要總共12KB來存儲一個用戶的數據:
8 + (4 + 20 (Sorted Set開銷)) * 500 + 20 (哈希表開銷) = 12KB
這里我們為每個元素預留了20 byte的開銷。在一個Sorted Set中,我們可以假設我們至少需要兩個指針來維護元素之間的順序 —— 一個指向前一個元素,一個指向后一個元素。在64位機器上,每個指針將占用8byte。所以我們將需要16byte用于指針。我們額外增加了一個word(4 byte)用于存儲其他開銷。
如果我們需要在任何時候跟蹤一百萬用戶,我們需要的總內存將是12GB:
12KB?1million =12GB
與Fixed Window(固定窗口)相比,Sliding Window算法占用了大量的內存;這會是一個可擴展性問題。如果我們能夠結合使用上述兩種算法來優化我們的內存使用會怎樣呢?
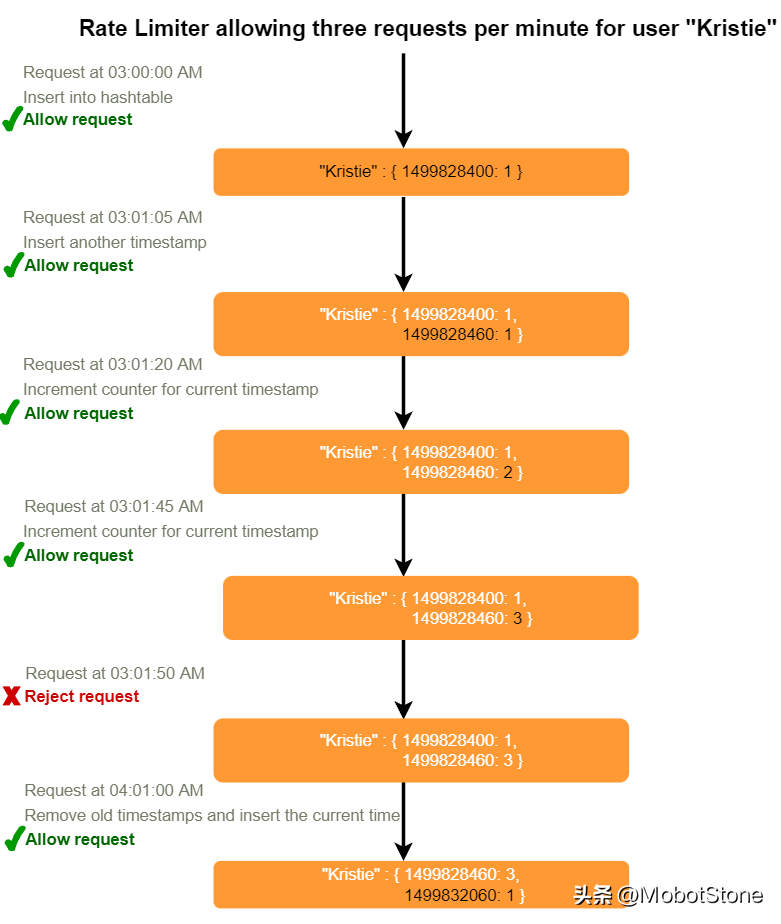
10、帶計數器的滑動窗口
如果我們用多個固定的時間窗口來追蹤每個用戶的請求計數,例如,1/60的我們速率限制的時間窗口大小會怎樣呢?例如,如果我們有一個小時的速率限制,我們可以每分鐘計數一次,并在收到新請求時計算過去一個小時內所有計數器的總和,以計算閾值。這樣可以減少我們的內存占用。比如,我們限制每小時500次請求,每分鐘最多10次請求。這意味著,當過去一小時內帶時間戳的計數器之和超過請求閾值(500)時,用戶就超過了速率限制。此外,她每分鐘不能發送超過十個請求。這是一個合理而實用的考慮,因為沒有真實的用戶會頻繁發送請求。即使他們這么做,他們也會因為每分鐘限制都會重置而看到重試的成功。
我們可以在Redis哈希中存儲我們的計數器,因為它為少于100個鍵提供了極其高效的存儲。當每個請求在哈希中增加一個計數器時,它也會設置哈希在一小時后過期。我們將每個'time'(時間)標準化到一分鐘。
我們使用帶計數器的滑動窗口,存儲所有用戶的數據需要多少內存呢?假設'UserID'需要8byte。每個epoch時間將需要4byte,Counter(計數器)將需要2byte。假設我們需要每小時500個請求的速率限制。假設哈希表有20byte的開銷,Redis哈希有20byte的開銷。因為我們每分鐘都會進行計數,所以最多,每個用戶需要60個條目。我們需要總共1.6KB來存儲一個用戶的數據:
8 + (4 + 2 + 20 (Redis哈希開銷)) * 60 + 20 (哈希表開銷) = 1.6KB
如果我們需要在任何時候跟蹤一百萬用戶,我們需要的總內存將是1.6GB:
1.6KB * 1百萬 ~= 1.6GB
所以,我們的'帶計數器的滑動窗口'算法比簡單的滑動窗口算法少用86%的內存。
11、數據分片和緩存
對于用戶ID的數據,我們可以進行分片處理以分散用戶數據。為了容錯和復制,我們應該使用“一致性哈希”。如果我們希望對不同的API實施不同的限流標準,我們可以選擇每個用戶每個API進行分片。以“URL短鏈接生成器”為例,我們可以對每個用戶或IP的createURL()和deleteURL() API設置不同的限流規則。
如果我們的API是分區的,一個實際的考慮是為每個API分片也設置一個相對較小的限流器。以我們的URL短鏈接生成器為例,我們希望限制每個用戶每小時不超過100個短URL的創建。假設我們使用基于哈希的分區方式對createURL() API進行分區,我們可以設置每個分區的限流器,允許每個用戶每分鐘創建不超過3個短URL,另外每小時創建不超過100個短URL。
我們的系統可以從緩存近期活躍用戶中獲得巨大的好處。應用服務器可以在擊中后端服務器之前快速檢查緩存是否有所需記錄。我們的限流器可以從Write-back緩存中獲得顯著的好處,只在緩存中更新所有計數器和時間戳。對永久存儲的寫入可以在固定的時間間隔進行。這樣我們可以確保限流器對用戶請求增加的延遲最小。讀取操作始終先擊中緩存,這在用戶達到最大限制時非常有用,因為限流器將只讀取數據而不進行任何更新。
對于API速率限制服務來說,最近最少使用(Least Recently Used,LRU)可能是一個合理的緩存驅逐策略。
12、我們應該按照IP還是用戶進行限流?
讓我們來討論一下使用這兩種方案的優缺點:
IP:在此方案中,我們對每個IP的請求進行限流;盡管在區分“好”與“壞”行為者方面并非最佳,但它仍然比完全沒有限流要好。基于IP的限流最大的問題在于,當多個用戶共享一個公網IP時,如在網吧或使用相同網關的智能手機用戶。一個行為不當的用戶可能導致對其他用戶的限流。另一個問題可能出現在緩存IP限制時,因為即使一個計算機也有大量的IPv6地址可供黑客使用,讓服務器因跟蹤IPv6地址而耗盡內存是輕而易舉的事!
用戶:限流可以在用戶認證后對API進行。一旦認證成功,用戶將獲得一個令牌,用戶將在每次請求時傳遞該令牌。這將確保我們對具有有效認證令牌的特定API進行限流。但是,如果我們必須對登錄API本身進行限流怎么辦?這種限流的弱點是,黑客可以通過輸入錯誤的憑證達到限流閾值來對用戶進行拒絕服務攻擊;之后,實際的用戶將無法登錄。
如果我們結合以上兩種方案會怎么樣呢?
混合:一個正確的方法可能是同時進行每IP和每用戶的限流,因為它們在單獨實施時都有弱點,然而,這將導致更多的緩存條目,每個條目需要更多的細節,因此需要更多的內存和存儲空間。