服務架構:事件驅動架構
作者:趙帥虎
事件通常來源于外部系統,比如IoT中的物理設備、互聯網用戶的端上。我們在設計時,必須認真評估總體的數據量和吞吐量,以保證系統能支撐這個量級。

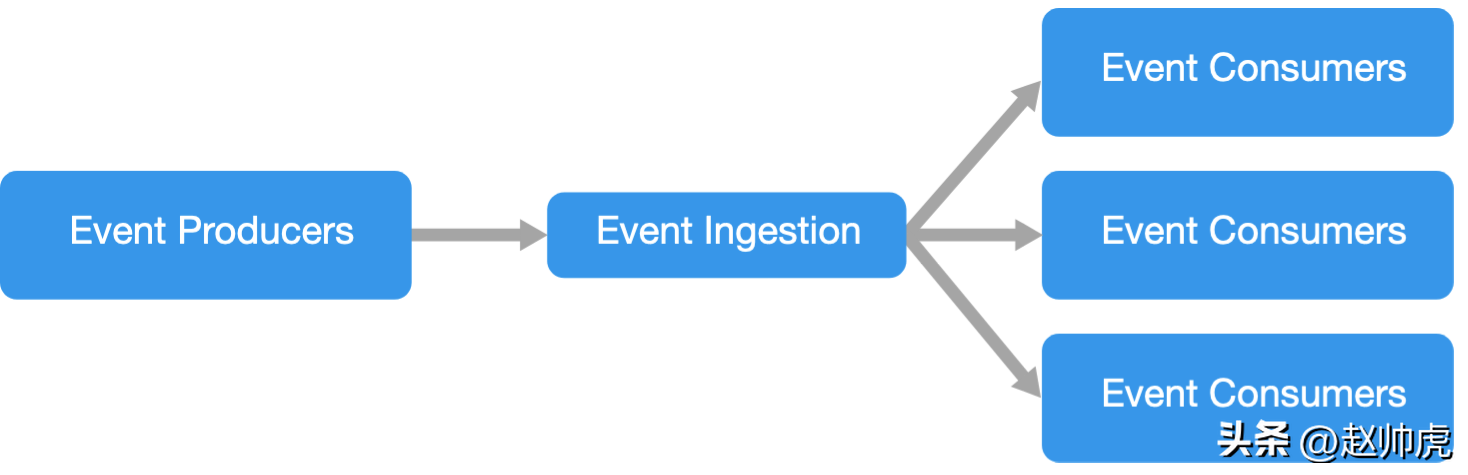
事件驅動架構是由生產者和消費者組成,生產者負責生產事件,消費者監聽并消費事件。
事件驅動架構
事件分發以近實時的方式進行,所以當事件產生時,消費者可以立即做出應對。
- 生產者和消費者是解耦的,它不知道有哪些消費者在監聽事件
- 消費者之間也是解耦的,每個消費者都可以讀取所有事件。
還有一種模式,多個消費者是競爭的關系,它們從同一個隊列消費,不出現錯誤的情況下每個事件都只被處理一次。
另外,在某些系統中,事件導入的吞吐量要求也很高,比如IoT系統。
事件驅動架構可以通過發布/訂閱模型或事件流模型來實現:
- 發布/訂閱模型:消息隊列負責追蹤訂閱者,事件被發布后,消息隊列負責發送給訂閱者。一旦事件被接收,就不能再重放,新增的訂閱者也看不到該事件。
- 事件流模型:將事件寫入日志并持久存儲下來,在單個分區里事件嚴格有序。client端不需要訂閱這個事件流,而且能夠從任意一個位置開始讀取事件。當然,移動偏移量也要靠客戶端自己完成。這意味著client可以在任意時間點加入,也支持事件重放。
在事件的消費上,也可以有一些略微不同的方式:
- 簡單模式:事件產生后立刻觸發消費者下一步的動作。比如風控、治理等場景下的異常行為檢測。
- 復雜模式:消費者處理一組數據,找到其中的規律,比如基于時間窗口做聚合求sum/count/avg。
- 純流式:通過流式平臺比如Kafka作為數據中轉的工具,接收事件并喂給下游的processor。下游的processor通常做簡單的transform之后再寫入的kafka。
事件通常來源于外部系統,比如IoT中的物理設備、互聯網用戶的端上。我們在設計時,必須認真評估總體的數據量和吞吐量,以保證系統能支撐這個量級。
在上面的流程圖中,右側的三個格子表示三種類型的消費者,每種類型的消費者下面有多個實例。在實際場景中,出于容災的目的,多個消費者實例的情況非常普遍。為了保證事件處理的吞吐量,多個實例也是有必要的。
在處理事件時,一個消費者實例可以創建多個線程。這也能提高處理的吞吐量,不過事件被處理的順序就亂了,業務上可能無法接受;另外多線程處理也很難保證exactly-once語義。
應用場景
- 多個子系統都需要處理這些事件
- 需要實時處理,且延遲越小越好
- 處理邏輯比較復雜的場景,比如要對事件繼續模式匹配或者基于時間窗口的聚合
- 事件量級非常大,生產的速度也很快
架構優勢
- 生產者和消費者解耦
- 沒有點對點的集成,增加新消費者幾乎沒有難度
- 消費者可以即時處理到來的事件
- 天生分布式、可擴展性非常高
- 每個下游子系統都可以訪問全部事件,且互相獨立
有哪些挑戰
- 不丟事件:一些業務場景要求,事件必須發送成功,不能丟。比如金融、電商等涉及錢的場景;
- 按順序消費:由于架構的分布式特性,消費者本身就是多實例的,不支持全局有序消費;
- exactly-once消費:事件消費的每個環節都可能會失敗,失敗就會重試。重試的話,就需要額外的機制去保障exactly once
補充說明
在設計系統時,我們通常需要考慮單條消息的大小,它對系統的性能和金錢成本影響都非常大。如果走兩個極端的話,可以是:
如果將所有需要的信息都放到單個事件里,處理起來會很方便,并且能夠避免額外的信息查詢。
如果將非常少的信息放到單個事件里,比如ID字段,那么會節省大量傳輸數據的時間和金錢成本,但其他信息需要訪問其他服務才能獲取到。
這其中的利益權衡,看自己的業務來定了。
責任編輯:姜華
來源:
今日頭條