













我們一起聊聊分布式事務
一. 分布式事務問題的理論模型
1.1 CAP三進二
CAP的定義
- Consistency (一致性):
“all nodes see the same data at the same time”,即更新操作成功并返回客戶端后,所有節點在同一時間的數據完全一致,這就是分布式的一致性。一致性的問題在并發系統中不可避免,對于客戶端來說,一致性指的是并發訪問時更新過的數據如何獲取的問題。從服務端來看,則是更新如何復制分布到整個系統,以保證數據最終一致。
- Availability (可用性):
可用性指“Reads and writes always succeed”,即服務一直可用,而且是正常響應時間。好的可用性主要是指系統能夠很好的為用戶服務,不出現用戶操作失敗或者訪問超時等用戶體驗不好的情況。
- Partition Tolerance (分區容錯性):
即分布式系統在遇到某節點或網絡分區故障的時候,仍然能夠對外提供滿足一致性或可用性的服務。比如現在的分布式系統中有某一個或者幾個機器宕掉了,其他剩下的機器還能夠正常運轉滿足系統需求,對于用戶而言并沒有什么體驗上的影響。
CAP三進二的含義
CAP理論就是說在分布式存儲系統中,最多只能實現上面的兩點。而由于當前的網絡硬件肯定會出現延遲丟包等問題,所以分區容忍性是我們必須需要實現的。所以我們只能在一致性和可用性之間進行權衡,沒有NoSQL系統能同時保證這三點。
CA:傳統Oracle數據庫 || AP:大多數網站架構的選擇 || CP:Redis、Mongodb
注意:分布式架構的時候必須做出取舍。一致性和可用性之間取一個平衡。多余大多數web應用,其實并不需要強一致性。因此犧牲C換取P,這是目前分布式數據庫產品的方向。
CAP的核心理論是:就是一個分布式體統不可能同時滿足一致性、可用性、分區容錯性三個需求,最多只能較好的同時滿足兩個。
- CA without P:放棄P的同時也就意味著放棄了系統的擴展性,也就是分布式節點受限,沒辦法部署子節點,這是違背分布式系統設計的初衷的。
- CP without A:如果不要求A(可用),相當于每個請求都需要在服務器之間保持強一致,而P(分區)會導致同步時間無限延長(也就是等待數據同步完才能正常訪問服務),一旦發生網絡故障或者消息丟失等情況,就要犧牲用戶的體驗,等待所有數據全部一致了之后再讓用戶訪問系統。設計成CP的系統其實不少,最典型的就是分布式數據庫,如Redis、HBase等。對于這些分布式數據庫來說,數據的一致性是最基本的要求,因為如果連這個標準都達不到,那么直接采用關系型數據庫就好,沒必要再浪費資源來部署分布式數據庫。
- AP wihtout C:高可用并允許分區,放棄一致性。一旦分區發生,節點之間可能會失去聯系,為了高可用,每個節點只能用本地數據提供服務,而這樣會導致全局數據的不一致性。典型的應用就如某米的搶購手機場景,可能前幾秒你瀏覽商品的時候頁面提示是有庫存的,當你選擇完商品準備下單的時候,系統提示你下單失敗,商品已售完。這其實就是先在 A(可用性)方面保證系統可以正常的服務,然后在數據的一致性方面做了些犧牲,雖然多少會影響一些用戶體驗,但也不至于造成用戶購物流程的嚴重阻塞。
1.2 BASE定理
在上邊,我們談到,因為P總是存在的,放棄不了。另外,可用性、一致性也是我們一般系統必須要滿足的,如何在可用性和一致性進行權衡,所以就出現了各種一致性的理論與算法。
BASE理論是:BASE是指基本可用(Basically Available)、軟狀態( Soft State)、最終一致性( Eventual Consistency)。BASE是對CAP中一致性和可用性權衡的結果,其來源于對大規模互聯網系統分布式實踐的總結,是基于CAP定理逐步演化而來的,其核心思想是即使無法做到強一致性(Strong consistency),但每個應用都可以根據自身的業務特點,采用適當的方式來使系統達到最終一致性(Eventual consistency)。
- 基本可用:
基本可用是指分布式系統在出現不可預知故障的時候,允許損失部分可用性,以下兩個就是“基本可用”的典型例子。
1. 響應時間上的損失:正常情況下,一個在線搜索引擎需要在0.5秒之內返回給用戶相應的查詢結果,但由于出現故障(比如系統部分機房發生斷電或斷網故障),查詢結果的響應時間增加到了1~2秒。
2. 功能上的損失:正常情況下,在一個電子商務網站上進行購物,消費者幾乎能夠順利地完成每一筆訂單,但是在一些節日大促購物高峰的時候,由于消費者的購物行為激增,為了保護購物系統的穩定性,部分消費者可能會被引導到一個降級頁面。
- 弱狀態
弱狀態也稱為軟狀態,和硬狀態相對,是指允許系統中的數據存在中間狀態,并認為該中間狀態的存在不會影響系統的整體可用性,即允許系統在不同節點的數據副本之間進行數據同步的過程存在延時。
- 最終一致性
最終一致性強調的是系統中所有的數據副本,在經過一段時間的同步后,最終能夠達到一個一致的狀態。因此,最終一致性的本質是需要系統保證最終數據能夠達到一致,而不需要實時保證系統數據的強一致性。
1.3 二階段提交協議
二階段提交(Two-phase Commit)被稱為是一種協議(Protocol)。在分布式系統中,每個節點雖然可以知曉自己的操作時成功或者失敗,卻無法知道其他節點的操作的成功或失敗。當一個事務跨越多個節點時,為了保持事務的ACID特性,需要引入一個作為協調者的組件來統一掌控所有節點(稱作參與者)的操作結果并最終指示這些節點是否要把操作結果進行真正的提交(比如將更新后的數據寫入磁盤等等)。
二階段提交分為兩階段:
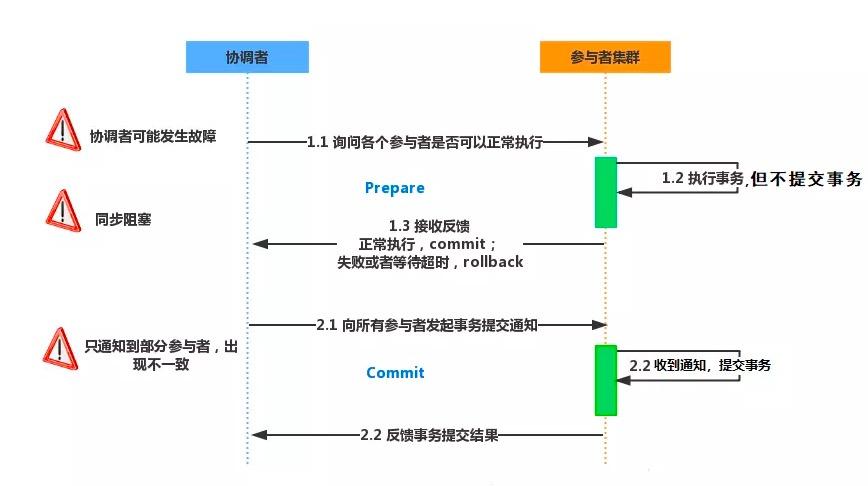
二階段提交優點:
- 盡量保證了數據的強一致,但不是100%一致。
缺點:
- 單點故障,由于協調者的重要性,一旦協調者發生故障,參與者會一直阻塞,尤其時在第二階段,協調者發生故障,那么所有的參與者都處于鎖定事務資源的狀態中,而無法繼續完成事務操作
- 同步阻塞,由于所有節點在執行操作時都是同步阻塞的,當參與者占有公共資源時,其他第三方節點訪問公共資源不得不處于阻塞狀態
- 數據不一致,在第二階段中,當協調者向參與者發送提交事務請求之后,發生了局部網絡異常或者在發送提交事務請求過程中協調者發生了故障,這會導致只有一部分參與者接收到了提交事務請求。這部分參與者接到提交事務請求之后就會執行提交事務操作。但是其他部分未接收到提交事務請求的參與者則無法提交事務。從而導致分布式系統中的數據不一致
1.4 三階段提交協議
三階段提交(Three-phase commit),三階段提交是為解決兩階段提交協議的缺點而設計的。與兩階段提交不同的是,三階段提交是“非阻塞”協議。三階段提交在兩階段提交的第一階段與第二階段之間插入了一個準備階段,使得原先在兩階段提交中,參與者在投票之后,由于協調者發生崩潰或錯誤,而導致參與者處于無法知曉是否提交或者中止的“不確定狀態”所產生的可能相當長的延時的問題得以解決。
三階段提交的三個階段:
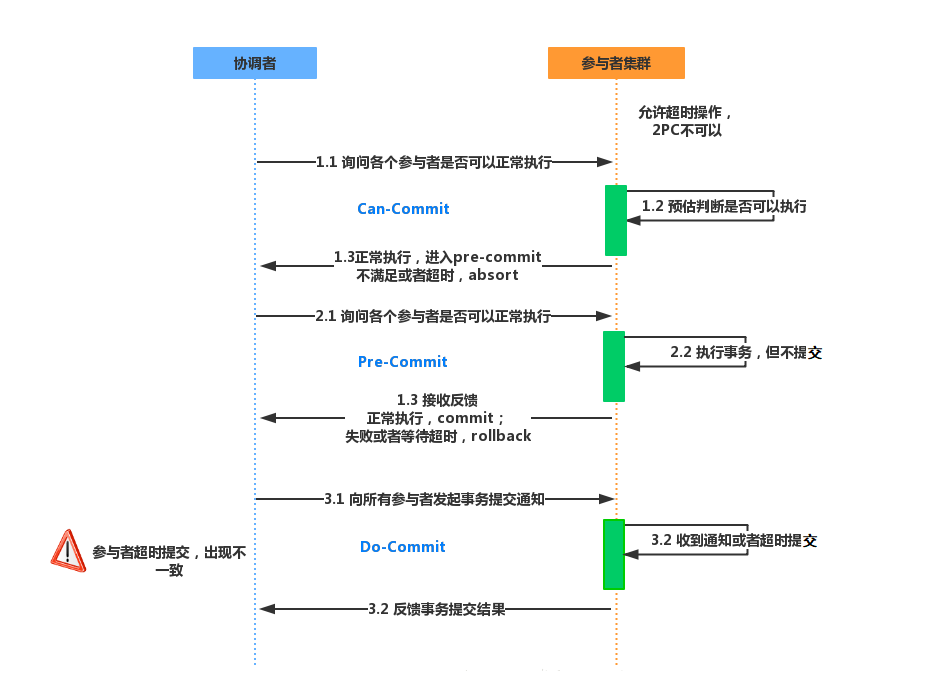
詢問階段 CanCommit
協調者向參與者發送CanCommit請求,參與者如果可以提交就返回Yes響應,否則返回No響應。
準備階段 PreCommit
協調者根據參與者在詢問階段的響應判斷是否執行事務還是中斷事務:
- 如果所有參與者都返回Yes,則執行事務
- 如果參與者有一個或多個參與者返回No或者超時,則中斷事務
參與者執行完操作之后返回ACK響應,同時開始等待最終指令
提交階段 DoCommit
協調者根據參與者在準備階段的響應判斷是否執行事務還是中斷事務:
- 如果所有參與者都返回正確的ACK響應,則提交事務
- 如果參與者有一個或多個參與者收到錯誤的ACK響應或者超時,則中斷事務
- 如果參與者無法及時接收到來自協調者的提交或者中斷事務請求時,會在等待超時之后,會繼續進行事務提交
協調者收到所有參與者的ACK響應,完成事務。
解決二階段提交時的問題
相比二階段提交,三階段提交降低了阻塞范圍,在等待超時后協調者或參與者會中斷事務。避免了協調者單點問題。階段 3 中協調者出現問題時,參與者會繼續提交事務。
三階段提交的問題
數據不一致問題依然存在,當在參與者收到 preCommit 請求后等待 do commite 指令時,此時如果協調者請求中斷事務,而協調者無法與參與者正常通信,會導致參與者繼續提交事務,造成數據不一致。
所以無論是2PC還是3PC都不能保證分布式系統中的數據100%一致。
二. 解決方式
2.1 補償事務(TCC)
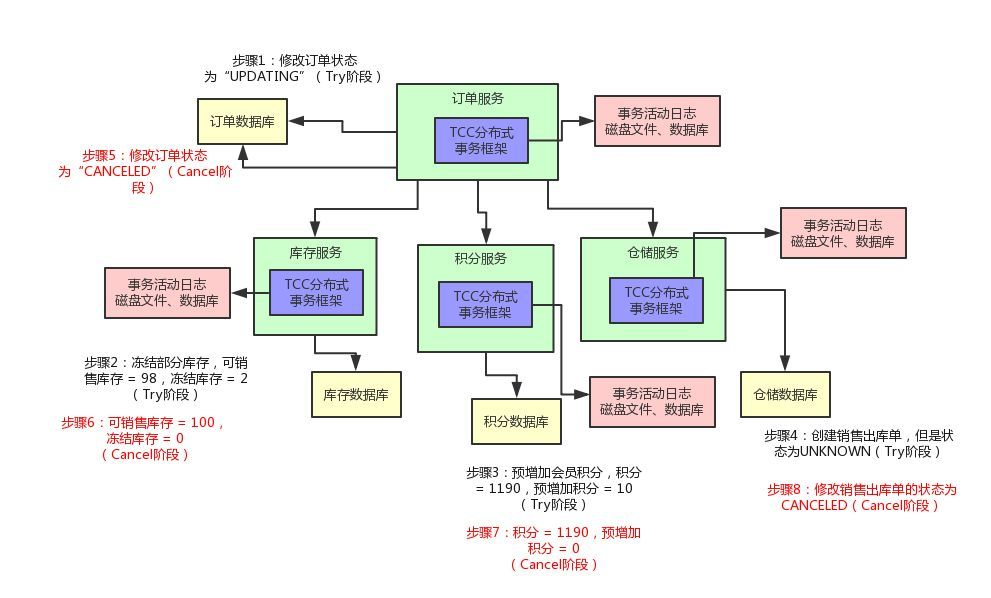
TCC 是基于二階段提交協議的服務化編程模型,是把一個完整的業務拆分為三個步驟
TCC分為三個階段:
1. Try 階段是做業務檢查(一致性)及資源預留(隔離),此階段僅是一個初步操作,它和后續的Confirm 一起才能
真正構成一個完整的業務邏輯。
2. Confirm 階段是做確認提交,Try階段所有分支事務執行成功后開始執行 Confirm。通常情況下,采用TCC則
認為 Confirm階段是不會出錯的。即:只要Try成功,Confirm一定成功。若Confirm階段真的出錯了,需引
入重試機制或人工處理。
3. Cancel 階段是在業務執行錯誤需要回滾的狀態下執行分支事務的業務取消,預留資源釋放。通常情況下,采
用TCC則認為Cancel階段也是一定成功的。若Cancel階段真的出錯了,需引入重試機制或人工處理。
優點:
性能提升:具體業務來實現控制資源鎖的粒度變小,不會鎖定整個資源。
數據最終一致性:基于 Confirm 和 Cancel 的冪等性,保證事務最終完成確認或者取消,保證數據的一致性。
可靠性:解決了 XA 協議的協調者單點故障問題,由主業務方發起并控制整個業務活動,業務活動管理器也變成多點,引入集群。
缺點:TCC 的 Try、Confirm 和 Cancel 操作功能要按具體業務來實現,業務耦合度較高,提高了開發成本。
舉例說明:
2.2 本地消息表
本地消息表的核心思想是將分布式事務拆分成本地事務進行處理。
在訂單系統新增一條消息表,將新增訂單和新增消息放到一個事務里完成,然后通過輪詢的方式去查詢消息表,將消息推送到MQ,庫存系統去消費MQ。
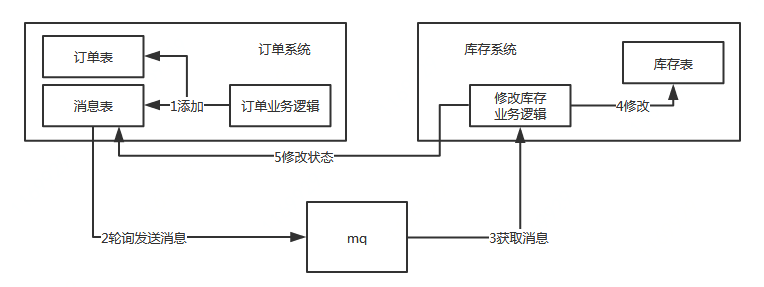
執行流程:
- 訂單系統,添加一條訂單和一條消息,在一個事務里提交
- 訂單系統,使用定時任務輪詢查詢狀態為未同步的消息表,發送到MQ,如果發送失敗,就重試發送
- 庫存系統,接收MQ消息,修改庫存表,需要保證冪等操作
- 如果修改成功,調用rpc接口修改訂單系統消息表的狀態為已完成或者直接刪除這條消息
- 如果修改失敗,可以不做處理,等待重試
訂單系統中的消息有可能由于業務問題會一直重復發送,所以為了避免這種情況可以記錄一下發送次數,當達到次數限制之后報警,人工接入處理;庫存系統需要保證冪等,避免同一條消息被多次消費造成數據一致。
本地消息表這種方案實現了最終一致性,需要在業務系統里增加消息表,業務邏輯中多一次插入的DB操作,所以性能會有損耗,而且最終一致性的間隔主要有定時任務的間隔時間決定。
2.3 MQ消息事務
消息事務的原理是將兩個事務通過消息中間件進行異步解耦。
訂單系統執行自己的本地事務,并發送MQ消息,庫存系統接收消息,執行自己的本地事務,乍一看,好像跟本地消息表的實現方案類似,只是省去了對本地消息表的操作和輪詢發送MQ的操作,但實際上兩種方案的實現是不一樣的。
消息事務一定要保證業務操作與消息發送的一致性,如果業務操作成功,這條消息也一定投遞成功。
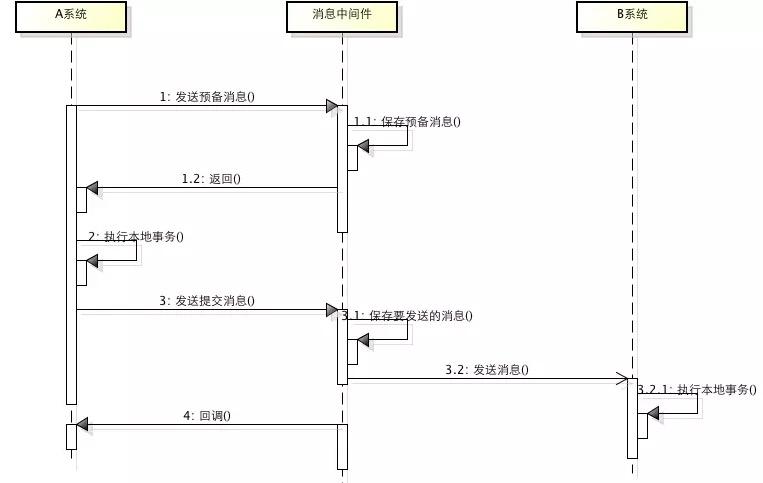
消息事務依賴于消息中間件的事務消息,基于消息中間件的二階段提交實現的,RocketMQ就支持事務消息。
執行流程:
- 發送prepare消息到消息中間件
- 發送成功后,執行本地事務
- 如果事務執行成功,則commit,消息中間件將消息下發至消費端
- 如果事務執行失敗,則回滾,消息中間件將這條prepare消息刪除
- 消費端接收到消息進行消費,如果消費失敗,則不斷重試
這種方案也是實現了最終一致性,對比本地消息表實現方案,不需要再建消息表,不再依賴本地數據庫事務了,所以這種方案更適用于高并發的場景。
三. 總結
在實際生產中我們要盡量避免使用分布式事務,能轉化為本地事務就用本地事務,如果必須使用分布式事務,還需要從業務角度多思考使用哪種方案更適合。




























