AWS Aurora 數據庫 Failover 處理方案
Aurora簡述
Amazon Aurora 是亞馬遜自研的云原生數據庫,除兼容性、性能、擴展性外,它在設計之初,就以極致的可用性作為目標,盡可能減少故障對應用程序的影響。
Amazon Aurora 在故障恢復方面的設計理念主要包括:
- 1. 能在較大范圍故障時仍然提供服務:跨3個可用區的6備份存儲使它在一個可用區和另一個額外備份發生故障時仍能提供服務;跨區域的全球數據庫能在主區域發生故障時快速切換到從區域;
- 2. 加快故障恢復的速度:將數據拆分成10 GB 粒度存儲單元使單個存儲單元能在秒級別恢復;通過分布式存儲進行并行恢復等;快速找到健康計算節點先進行節點替換來使整個集群盡快提供服務。

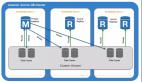
Amazon Aurora 的架構示意圖如上所示,僅有Primary RW(Read/Write) DB一個主節點用于處理寫請求,而其余的則為從節點Secondary RO(Read-Only) DB用于處理讀請求,在其論文中指出Secondary RO DB可以多達15個。( Aurora論文翻譯版本 )
Aurora有多主架構嗎?如果是多主架構會怎樣?
它們以端點 cluster endpoint 的形式對外提供服務,用戶可以通過讀寫端點來訪問 Aurora 寫節點;通過只讀端點訪問 Aurora 讀節點。
這里的只讀端點只有一個,我們在應用程序中的配置也只有一個,但并不表示我們只有一個只讀實例。
只讀端點下面可以掛載多個實例,通過 Route53(高度可用和可擴展的云托管域名系統 (DNS) 服務) 進行負載輪訓到不同的只讀節點實例。
Failover介紹
在 Amazon Aurora 中,Failover 是指在主節點不可用時,自動或手動的將一個從節點提升為新的主節點的過程。
Failover 通常發生在以下情況:
主節點故障:如果主節點發生故障或停止服務,Amazon Aurora 將自動將一個從節點提升為新的主節點,以確保數據庫的高可用性和容錯性。
可用區故障:如果主節點所在的可用區發生故障,Amazon Aurora 將自動將一個在其他可用區中的從節點提升為新的主節點。
手動干預:如果需要執行主節點的計劃維護或升級操作,可以手動將一個從節點提升為新的主節點,以確保數據庫的可用性和穩定性。
當寫節點發生故障時,Aurora 會進行如下的 Failover 過程:
1. 根據不同節點 failover 優先級和復制延遲來選擇一個讀節點,將其提升成新的寫節點。因為該節點角色發生切換,需要重啟該節點。
2. 嘗試恢復原來的寫節點并讓它成為新的讀節點。這里也會涉及到節點重啟。
3. 待新的寫節點重啟成功以后,定位讀寫端點指向新的寫節點。這里涉及到域名的更新,依賴于 Route53 的實現。
4. 待新的讀節點重啟成功以后,定位只讀端點指向新的讀節點。這里同樣涉及到域名更新,依賴于 Route53 的實現。
AWS在控制臺提供了手動觸發failover的操作,我們可以通過觀測 Event 事件來查看 failover 過程中 Aurora 的讀寫節點究竟發生了哪些操作。
以一寫一讀的集群為例,在控制臺點擊 failover,可以觀測并整理出如下事件。

并繪制出事件時間圖

整個集群 failover 過程在29秒完成,其中,新的寫節點重啟成功用了7秒,新的寫節點在7秒以后就可以接受請求。
由于用戶訪問 Aurora 是利用域名的方式(Aurora 的讀寫域名和只讀域名),新寫節點啟動后需要更新域名,而域名更新需要一定的時間,所以應用程序在數據庫實例可用到 DNS 更新完成這個時間段內通過域名的方式連接 Aurora 集群時會發生連接錯亂的現象。
在DNS發生切換前,使用寫域名會連接到新讀庫上、使用讀域名會連接到新寫庫上。而這種情況會對應用程序產生較大影響~~~
Failover對應用程序的影響
我們分別使用Maria和AWS驅動做了測試。
這里我們使用當前自身中間件版本的 ORM (基于 Mybatis 的封裝)和 Maria驅動,分析每個階段對程序的讀寫影響。

階段一
這個階段還未開始觸發failover,讀寫一切正常。
階段二
這個階段讀庫開始并正在重啟中,寫庫正常,對于寫庫的操作一切正常。
讀庫連接池狀態: RO - Pool Status: Active: 0, Idle: 0, Total: 0, Waiting: 1
寫庫連接池狀態: WR - Pool Status: Active: 1, Idle: 1, Total: 2, Waiting: 0
DEBUG級別日志:Connection refused (Connection refused)- 補充讀庫連接
對于讀庫的操作則會發生慢接口(queryTime > 業務sql執行時間 + 階段二 + 階段三)。但這并不會意味著一定會產生ERROR異常,具體要看連接參數connection-timeout設置和restart的過程時長。
connection-timeout > restart
會有長查詢,但不會有ERROR級別異常。因為會在restart成功后正常建立TCP連接。
在這個過程中,Hikari連接池會做很多事情。
首先,這個階段連接池內的連接都是一個time_wait狀態的,獲取連接時,這個連接如果空閑超出500ms,會在連接存活檢測失效,如果空閑在500ms內,會在執行請求時立即得到連接關閉的狀態。
不管哪種此時連接池都會把它關閉并從維護的池中清理,直到把維護的連接都嘗試并清理個遍,然后嘗試創建新的連接進行補充。
如果此時我們開啟DEBUG日志的話會看到大量Connection refused (Connection refused)debug級別日志,只要restart時間在connection-timeout的范圍內,也就無所謂了,大不了就查詢時間長一些。
connection-timeout < restart
這時是會真的報ERROR級別的錯誤了
Cause: java.sql.SQLTransientConnectionException: single:RO - Connection is not available, request timed out after 30005ms.
階段三
主從數據庫全部不可用
寫庫也會進入讀庫的上個階段
階段四
讀庫連接池逐漸補充、讀請求正常
[single:RO connection adder] DEBUG com.zaxxer.hikari.pool.HikariPool - single:RO - Added connection org.mariadb.jdbc.MariaDbConnection@515740ab
讀庫連接池狀態: RO - Pool Status: Active: 1, Idle: 1, Total: 2, Waiting: 0
注意: 此時DNS并未發生切換,補充進來的讀庫連接實際上是連接到老的讀庫上(新的寫庫)。
階段五
寫庫連接池逐漸補充、寫請求發生 --read-only異常!!!
[single:WR connection adder] DEBUG com.zaxxer.hikari.pool.HikariPool - single:WR - Added connection org.mariadb.jdbc.MariaDbConnection@2ca547c0
寫庫連接池狀態: WR - Pool Status: Active: 1, Idle: 1, Total: 1, Waiting: 0
注意: 此時DNS并未發生切換,補充進來的寫庫連接實際上是連接到老的寫庫上(新的讀庫)。
階段六
連接池狀態
RO - Pool Status: Active: 0, Idle: 2, Total: 2, Waiting: 0
WR - Pool Status: Active: 1, Idle: 2, Total: 3, Waiting: 0
應用異常日志
15:36:55.030 [http-nio-8080-exec-7] ERROR o.a.c.c.C.[.[.[.[dispatcherServlet] - Servlet.service() for servlet [dispatcherServlet] in context with path [] threw exception [Request processing failed; nested exception is org.springframework.jdbc.UncategorizedSQLException:
### Error updating database. Cause: java.sql.SQLException: (cnotallow=5) The MySQL server is running with the --read-only option so it cannot execute this statement
### The error may exist in file [/sample-single/target/classes/mapper/StatusMapper.xml]
### The error may involve sample.orm.single.mapper.StatusMapper.longUpdate-Inline
### The error occurred while setting parameters階段七
- 1. 讀請求正常
- 2. 寫請求持續 read-only,直到連接生命周期結束(默認30分鐘)
。。。
很顯然、30分鐘的寫業務不可用是不可接受的……
如何應對數據庫的Failover
通常情況下,Aurora 的 failover 通常能在30~60秒左右內完成,對應用程序產生較低影響。
那么,是否有可能進一步加快 Aurora failover 的速度呢?實現部分會重點介紹如何在 Aurora 進行故障恢復的時候避免或者減少 DNS 的影響,從而加快故障切換速度。
控制客戶端 DNS TTL 的時間
檢查客戶端是否緩存了DNS及設置時間,如果設置較久的話,可以考慮將客戶端的 DNS 的 TTL 調小,但這并不能消除DNS切換帶來的影響。
數據庫實例的底層 IP 地址在故障轉移完成后可能會發生變化,也就是說如果我在故障轉移過程中建立連接還是會有出錯的可能性。
使用 RDS Proxy
RDS Proxy 是基于 Aurora/RDS 之上提供的一個代理層,它有三個特性:
1. 連接池能夠實現連接的多路復用,如果應用對數據庫的并發請求比較多,直接打到 Aurora 數據庫上會耗費很多資源。可以使用 RDS Proxy 來實現連接復用,支持更多的并發應用,并減少新建連接的需要。
2. 增強的安全性,如果不希望直接把底層數據庫的密碼直接暴露,可以使用 RDS Proxy,通過使 RDS Proxy 訪問 Secrets Manager 里的密碼來增強安全性。
3. 快速的故障恢復時間,RDS Proxy 避開了 Aurora 發生故障切換時節點切換帶來的域名 DNS 記錄更新的問題,用戶通過連接 RDS Proxy 可以避免域名更新的時間消耗。
AWS 的另一個產品,據說會有SQL上的性能損耗,未使用、未調研、未測試。
AWS智能驅動
智能驅動在連接到 Aurora 集群時,會拿到整個集群的拓撲和各個節點的角色信息(是寫節點還是讀節點)維持在緩存中。
有了這個拓撲,在節點發生變化時,就可以快速拿到變化的節點的角色信息,而無需再依賴的 DNS 的解析。

AWS 官方圖
上圖是AWS智能驅動自身的邏輯示意,應用程序連接到它時,會維護一個邏輯的連接和物理的連接。
比如現在的寫節點是 C,但同時它的拓撲緩存中會存放著節點 A 和 B 的信息,這樣如果節點 C 發生了故障,能夠及時檢測并將物理連接切換到 A 或 B 節點(取決于 Aurora 決定 failover 到哪個節點)而邏輯連接是保持不變的。
智能驅動與 MySQL 的普通驅動使用方法是一樣的,您只需要更換驅動,并將連接字符串更換為如下格式即可。
注意這里的 url 的字符串前面是 jdbc:mysql:aws。缺省情況下,故障切換的能力是開啟的,也可以通過參數調整的方式進行關閉。
jdbc:mysql:aws://集群名稱.集群id.us-east-2.rds.amazonaws.com:3306/數據庫名?useSSL=false&characterEncoding=utf-8
在對AWS智能驅動實驗中,failover這塊表現甚好,查看其failover代碼實現,發現其為每個連接綁定了一套插件執行鏈,其中就有failover插件。

AWS 官方圖
插件鏈的執行必然會對SQL帶來點性能上的損失,為了能夠正常failover,這點損失也能接受。
查看其版本變化和ISSUE、嗯…… 很活躍。
中間件的處理方式
AWS是自己實現了JDBC的Connection,為每一個連接綁定了插件機制,在每個業務SQL執行時檢測拓普變化,決定是否替換掉真實的物理連接,參考上上圖。
而我們使用Maria驅動每個創建的都是真實物理連接,如果要在物理連接上再抽象邏輯連接的話,工作量和實現都還是挺復雜的。
第一版:等待DNS切換的實現方案

在應用程序中開啟一個線程每隔20s去拓普表中檢查當前集群的寫節點是否發生變化,因為DNS切換的時間大概就是20s左右。
SELECT SERVER_ID, SESSION_ID, LAST_UPDATE_TIMESTAMP, REPLICA_LAG_IN_MILLISECONDS
FROM information_schema.replica_host_status
WHERE time_to_sec(timediff(now(), LAST_UPDATE_TIMESTAMP)) <= 300
當檢測到集群拓普發生變化時,獲取集群主節點端點HOST和當前集群寫端點域名進行探測,當兩個端點指向相同IP時,認為DNS切換完成,發出重建數據源事件,進行數據源重建。(寫節點DNS切換基本維持在20s左右)
我們看下failover過程中DNS探測解析的日志(此過程和上圖不是在同一個failover中搜集的,時間會有偏差)
while true; do
/bin/echo 'infra-test-cluster.cluster-cbot6qvorv5g : ' $(date +%T) $(nslookup infra-test-cluster.rds.amazonaws.com | grep Address | grep -v '#53')
/bin/echo 'infra-test-cluster.cluster-ro-cbot6qvorv5g: ' $(date +%T) $(nslookup infra-test-cluster.rds.amazonaws.com | grep Address | grep -v '#53')
/bin/echo '---------------------------------------'
sleep 0.5 # 0.5 second
done
===============================================================================================================================================================================================
infra-test-cluster.cluster-cbot6qvorv5g : 16:37:33 Address: 10.57.51.213
infra-test-cluster.cluster-ro-cbot6qvorv5g: 16:37:33 Address: 10.57.52.67
---------------------------------------
infra-test-cluster.cluster-cbot6qvorv5g : 16:37:34 Address: 10.57.51.213
infra-test-cluster.cluster-ro-cbot6qvorv5g: 16:37:34 Address: 10.57.52.67
---------------------------------------
infra-test-cluster.cluster-cbot6qvorv5g : 16:37:35 Address: 10.57.52.67
infra-test-cluster.cluster-ro-cbot6qvorv5g: 16:37:35 Address: 10.57.52.67
---------------------------------------
中間相同省略……
---------------------------------------
infra-test-cluster.cluster-cbot6qvorv5g : 16:38:07 Address: 10.57.52.67
infra-test-cluster.cluster-ro-cbot6qvorv5g: 16:38:07 Address: 10.57.52.67
---------------------------------------
infra-test-cluster.cluster-cbot6qvorv5g : 16:38:08 Address: 10.57.52.67
infra-test-cluster.cluster-ro-cbot6qvorv5g: 16:38:13 Address: 10.57.51.213
---------------------------------------failover 過程中域名DNS解析總結
1. 【寫域名】轉移到【老讀庫】 -- 16:37:35
2. 此時間段讀寫域名都解析到【老讀庫】(后續晉升為新寫庫) -- ----
3. 【讀域名】轉移到【老寫庫】(后續降級為新讀庫) -- 16:38:13
此方案的問題:
- 1. DNS完成切換前會有寫業務的 read-only報錯,持續在階段五,時間10~20s,主要看老讀庫重啟時長。
- 2. 從上面DNS探測的結果可以看出,會有持續較長一個階段讀寫域名解析到同一個實例上(老讀庫=新寫庫)。當探測到寫庫域名切換時發起數據源重建,此時創建的讀連接會連接到新寫庫上。盡管不會對業務產生影響,但是讀寫分離的功能會持續30min失效。

如果是由于瞬時流量造成的寫庫故障發生failover,這樣切換到新寫庫上的話,除了正常的寫流量還會有所有的讀流量涌入,這樣將更快的把寫庫打垮,然后繼續failover……
那再把讀庫域名的切換加入到探測過程中呢?等待讀寫域名指向全部穩定后再發起數據源重建事件怎樣?
首先,read-only的報錯時長會拉長,因為要同時等待讀寫域名的切換完成。
其次,如果我們只讀端點掛載多個讀實例的話,讀庫域名會在 Rout53 下每 5~30s 進行輪訓,固定不下來不好作為 DNS 切換完成的依據。
可以對只讀端點域名進行多次探測,當發現輪訓結束后的IP數量等同于讀庫數量時認為讀庫DNS切換完成。這個時間就太長了,并且還不確定是不是采用的輪詢算法。
此時,又想起了AWS智能驅動…… 不幸的是它也沒有解決上述問題(上圖AWS-1.1.5版本測試結果)
第二版:依賴拓普結構創建連接
上面看AWS故障轉移模塊代碼的時候發現,當發生故障轉移時,邏輯連接不變,物理連接會通過拓普中的實例端點進行連接替換。
要在Maria的連接中按照此方案實現的話,工作量太大、實現太復雜。
我們使用的是HikariCP連接池管理的鏈接生命周期,那如果我們在連接池創建連接時讓它按照我們給定的拓普去連接呢?
這樣的話,我們不僅解除了對DNS的解析依賴、還可以按照指定算法對讀庫進行連接負載,同時還可以把故障影響范圍控制在數據庫實例重啟的時間范圍內了!!!
在連接池創建連接前,我們通過外部配置給定的集群讀/寫端點獲取當前集群拓普結構,在連接池創建連接的時候,寫庫連接我們分配主端點、從庫連接我們按照自己的分配算法(輪詢),將分配后的實例端點給到連接池,讓它按照我們給定的實例端點進行連接的創建。

其中SwitchHostDatasource需要自己實現并給到Hikari,讓連接池使用我們提供的Datasource進行連接的創建和維護。
經驗證,在 Failover 過程中, 僅影響當前活躍連接在數據庫重啟過程中對應的讀/寫業務,徹底消除 Failover 過程 DNS 帶來的read-only異常、也避免了 failover 后的連接傾斜現象,最小化的處理數據庫 failover 對應用程序造成的影響。
巨人的肩膀:
https://aws.amazon.com/cn/blogs/china/be-vigilant-in-times-of-peace-amazon-aurora-fault-recovery-reduces-the-impact-of-dns-switching-on-applications/