Kubernetes部署讓Spark更靈活
作者 | 陽沁珂
Spark 是一個開源的數據處理框架,能快速處理大量數據的轉換。其高性能來自Spark的分布式框架,通常一個任務會被平均分配,跨機器集群工作。但Spark本身并不管理這些計算機,他需要一個集群的管理器來管理集群。Spark定義了需要執行的任務,而管理器決定了任務將如何被分配被執行,由此可見其重要性。這個管理器需要負責任務的接收、資源的調度和分配、任務的啟動、TaskTrack監控等。
傳統上,我們會選擇Hadoop YARN來作為資源調度管理器,并且使用spark-submit提交任務。但隨著云計算的推廣與容器的流行,因其需要依賴于HDFS的本地環境,YARN的部署方式顯得捉襟見肘。在技術的遞進下,從Spark3.3.1開始正式推出了Kubernetes的資源管理方式,其設計框架與云計算緊密結合,將Spark應用從本地HDFS集群中解耦合,賦予其更多的靈活性。

YARN Spark的傳統部署方式
YARN是一種資源管理系統,其建筑于Hadoop之上,用于管理協調多個機器之間的任務提交執行和監控。

Spark部署在YARN集群上,需要開發人員在安裝有Hadoop的每個機器配置上JAVA,Scala,YARN和Spark,并且不同機器之間可以免密登錄,還需要修改多個配置文件來明確master和slave節點。(詳細配置過程請參考running Spark on YARN)在任務提交之后,會首先向資源管理Resource manager申請資源,并且決定driver和executor node的分布。在我們配置集群時,就要考慮到將來的任務需要的資源量,如果工作負載高而資源不足,將顯著拖慢集群性能。
將Spark提交給YARN執行有兩種模式,yarn-client和yarn-cluster。yarn-client是將driver執行在提交任務的客戶端上,而yarn-cluster是將driver執行在集群的某臺機器上。采用client 模式可以方便開發者查看driver的log,但如果driver和cluster不在同一個集群中,需要考慮通信帶寬的限制。

提交的方式通常我們采用spark-submit的方法,在參數中指明提交到YARN中:

YARN Spark的困境
在實際的生產中使用傳統的YARN的部署方式,我們可能會遇見以下的場景:
在初期搭建一個YARN on Hadoop是需要大量工作的,并且需要有相關經驗的工程師來進行調整,因為大部分的設定需要通過conf去修改,并且需要在各個機器之間配置免密登錄。在使用時,不僅僅是初期搭建,在運營維護上也有額外的成本。使用過一定時間的YARN on Hadoop需要升級jdk或者Spark版本時,很容易因為jdk不兼容造成整個生產環境宕機。這就需要配備專業的人員來維護各個機器的環境。
YARN在做第一次配置的時候就需要預估好生產所需的資源。假設我們配備了10臺機器的集群來處理線上消費訂單,但雙十一的活動使得訂單激增,為了保證能高性能完成任務,我們臨時決定再增加五臺機器,提高并行度。經過一整夜的配置調試,終于擴大了集群,能及時處理線上的訂單。但當雙十一過去后,訂單量銳減,YARN集群的15臺機器,總是有一半以上是空置的。但已經購買和配置好的資源,變成了固定資產,很難再減少到10臺機器。
如果你的項目也遇見了上述的情況,了解下面這種新的Spark部署方法可能可以幫助你走出困境。
Spark on Kubernetes的部署
云計算在近幾年飛速發展,云已經變成了許多公司的首選。為了更好地滿足Spark應用的云遷移需求,Spark on Kubernetes的部署方法于 Spark 2.3 版本引入開始,到 Spark 3.1 社區標記 GA,基本上已經具備了在生產環境大規模使用的條件。
Kubernetes(也稱 k8s 或 “kube”)是一個開源的容器編排平臺,可以自動完成在部署、管理和擴展容器化應用過程中涉及的許多手動操作。主流的云平臺都提供Kubernetes的應用,如Amazon Elastic Kubernetes Service (Amazon EKS) , Azure Kubernetes Service (AKS) 等。
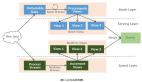
深度解析Spark on Kubernetes的部署架構是由Kubernetes的應用接受spark-submit的命令,可以查看到Kubernetes啟動一個driver和多個executor的pod,當任務完成之后,container的狀態會轉為complete。下面我們會介紹幾種在這種部署下的任務提交方法。

Submit提交
使用spark-submit命令可以直接向Kubernetes集群提交Spark應用程序。其提交的命令與Spark on YARN的提交方式幾乎一致,唯一的區別是需要修改master的鏈接到Kubernetes的集群。

Operator提交
除了直接向 Kubernetes Scheduler 提交作業的方式,還可以通過 Spark Operator 的方式來提交,Operator 在 Kubernetes 中是一個里程碑似的產物。Operator的安裝可以使用helm快速部署(quick-start-guide)。他將Spark的任務提交與傳統Kubernetes的yaml apply方法相結合,將許多的Spark調度參數管理轉為方便管理文檔模式。如下圖的yaml是一個向Kubernetes部署應用的例子。可以看見在這個部署中,部署了一個叫spark-pi的應用,使用gcr.io/spark/spark:v3.1.1的鏡像,如果需要其他版本的Spark,切換基礎鏡像即可。應用的部署是cluster的模式,會啟動一個driver和1個executor來完成jar文件中的SparkPi應用。此外,ServiceAccount可以和Kubernetes的secret管理相結合,更好地管理應用的安全密鑰。

Airflow的提交
一般的應用都需要與Airflow結合起來做到執行管理,傳統的Spark on YARN,都會選擇SSHOperator或者SparkSubmitOperator,使用spark-submit的方式提交通過Airflow提交任務。在Spark與Kubernetes結合之后,Airflow也開發了新的組件支持:使用yaml提交任務到Kubernetes的SparkKubernetesOperator和用于監聽的SparkKubernetesSensor。對于Spark所需的參數化管理,我們可以使用jinja的語法定義好yaml的template,在實時執行的時候傳入參數生成最終的執行yaml。其dag代碼如下:

在Airflow的UI上可以看見dag有兩個operator,一個負責提交Spark應用,一個負責監聽Spark應用是否成功地收集log信息。
Kubernetes 與 YARN 對比
環境隔離
不同于YARN的機器只能擁有一個JAVA_HOME,Kubernetes是基于容器來進行管理的,不同容器的環境是隔離的,相互不影響,環境的隔離顆粒度更細。當需要進行Spark版本升級時,直接通過修改基礎鏡像的版本即可。并且在啟動時,不需要修改conf和配置免密登錄等額外的配置工作。
更易擴展
使用Kubernetes,資源不再是固定離線的了,而是動態啟動的。executor是由pod來完成,當運算完成之后,會立即釋放pod占用的空間。特別是與云資源相結合,比如AWS的EKS(Elastic Kubernetes Service),可以做到極好的成本控制。當計算峰值來臨時,可以彈性增長,并且在峰值過后,立即降低釋放資源。
學習成本
不同于傳統的部署方式,Kubernetes是完全建立在pods上的,并且要完全發揮其靈活擴展的特性需要與云計算相結合。這就注定了,使用Kubernetes部署的開發者不僅僅需要了解Spark的基礎框架,還需要精通pods部署與基礎云知識。
數據湖
傳統的Spark集群,會將數據直接存儲在Hive或者HDFS中,實現本地化的數據湖。但是使用Kubernetes部署的Spark,是計算與存儲隔離的架構,啟動的執行pods是臨時的,并不能作為長久的數據存儲。一般數據也將放在云系統如snowflake,s3數據湖中。
日志
和Spark on YARN的很大的區別是,Kubernetes的log是存在于不同的pod上的,其自帶的功能并不支持將所有log集合到一個web UI上查看。如有查看日志需要,開發者需要kubectl logs命令指定查看一個pod的log,當pod執行完成被清理的時候log的信息也丟失了。使用Spark history web應用,我們需要將pod內存的log長久化(比如存在aws S3bucket上),然后deploy一個Spark history server指向到我們所存儲的位置上。其部署過程需要改動幾個config,參考:Spark history on k8s。
性能對比
因為Spark和Kubernetes都是主要負責計算資源和任務的調度,不涉及任何應用框架上的差別,所以其性能本身的差別是微乎甚微的。由TPC-DS提供的基準測試來看,兩者之間只有4.5%的差距,是幾乎可以忽略的。另外一方面,Spark on Kubernetes 一般選擇存算分離的架構,而 YARN 集群一般和 HDFS 耦合在一起,前者會在讀寫 HDFS 時喪失“數據本地性”,數據的讀寫將受限于網絡的性能。但隨著網絡性能的發展,各種高效的傳輸和壓縮算法的出現,這影響也幾乎可以忽略不計。
成本對比
我們之前有提及,Spark是離線資源,需要提前預估好需要的資源量,并且在應急擴展后很難將成本再降回來,即使資源空置,成本依舊在那里。但Kubernetes的基礎是云,其部署完全可以實現動態按需增長的資源,可以說不會存在需要為空閑未被使用的資源付費的需求。這是Kubernetes部署方式的一大優勢,也是其深受用戶追捧的主要原因之一。
總結
自從 2018 年初隨著 2.3.0 版本發布以來,Spark on Kubernetes 經過長期的發展和版本更新,在社區和用戶的打磨下已經擁有成熟的特性。現在IT設備的成本逐年上漲,給許多企業帶來難題。Spark+Kubernetes+云的組合的靈活性和超高性價比,給用戶帶來了更多的想象空間。Kubernetes的容器式管理Spark應用是很好的實踐,如果有云端或者混合部署的需求,建議采用Spark on Kubernetes的方式來統一管理,更好地實現與云計算的結合,并且靈活控制成本。但若大量數據仍是在本地存儲,或者有其他Hadoop的應用需求,Kubernetes并不能很好地滿足這些需求,還是建議維持YARN的部署方式。