













如何使用自己的數據和文檔自定義像ChatGPT這樣的大型語言模型

如果企業提示ChatGPT關于其企業的文檔中包含的內容,它將提供不準確的響應。如果用戶正在處理的應用程序的語言是高度技術性的或特定于某個領域的,那么這可能會出現問題。
為了解決這個問題,用戶可以用自己的定制文檔來增強大型語言模型。本文將展示一個框架,通過使用文檔嵌入為用戶自己的數據提供ChatGPT或GPT-4(或任何其他大型語言模型)的場景。
為大型語言模型提供場景
大型語言模型對場景敏感。如果用戶給它一個簡單的提示,就會根據它們從訓練數據中提取的知識做出反應。但是,如果在提示符前添加自定義信息,則可以修改它們的行為。
例如,如果用戶問ChatGPT這個問題,“使用運行率的風險是什么?”,它會提供一個很長的答案。
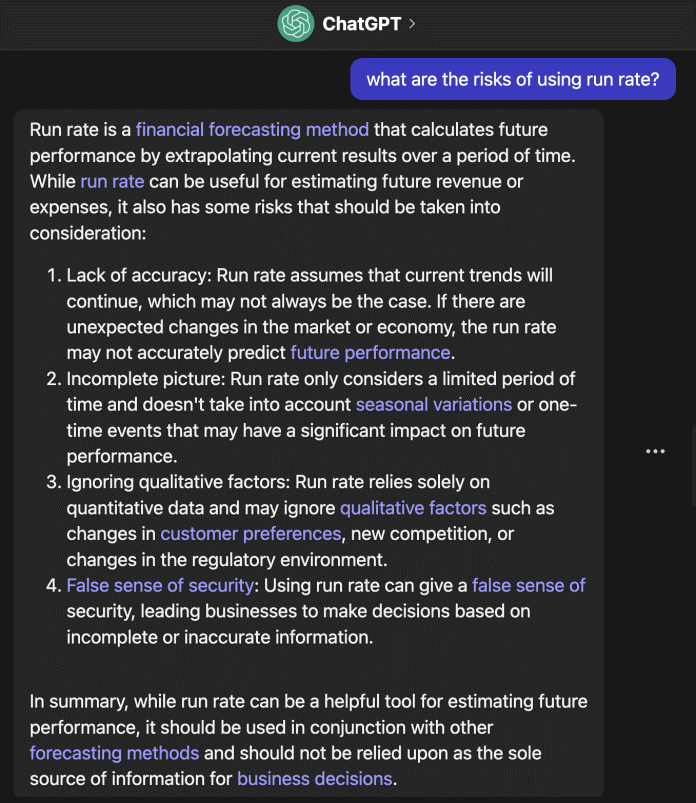
ChatGPT給出的一般性答案
但是,用戶可以提示ChatGPT根據特定文檔提供答案。在下面的例子中,問了ChatGPT同樣的問題,但是在提示符前加上了“根據以下文檔回答我的問題”,后面是來自Investopedia公司的一篇關于運行率的文章。這一次,ChatGPT提供了一個不同的答案,從文章的文本中提取。

從文檔中給出ChatGPT場景

ChatGPT根據文檔場景進行響應
這種技術的價值是顯而易見的,特別是在場景非常重要的應用程序中。但是,人工向提示添加場景是不切實際的,特別是有數千個文檔時。
假設企業有一個網站,該網站有數千個頁面,其中包含有關金融主題的豐富內容,并且希望創建一個基于ChatGPT API的聊天機器人,以幫助用戶瀏覽這些內容。用戶需要一種系統的方法來將其提示與正確的頁面相匹配,并使用大型語言模型來提供場景感知的響應。這就是文檔嵌入的用武之地。
使用嵌入捕獲語義
在進入嵌入之前,先為聊天機器人創建一個高級框架:
- 用戶輸入提示。
- 檢索與提示相關的最佳文檔。
- 創建一個新的提示,其中包括用戶的問題以及文檔中的場景。
- 給語言模型提供新制作的提示。
- 將答案返回給用戶。
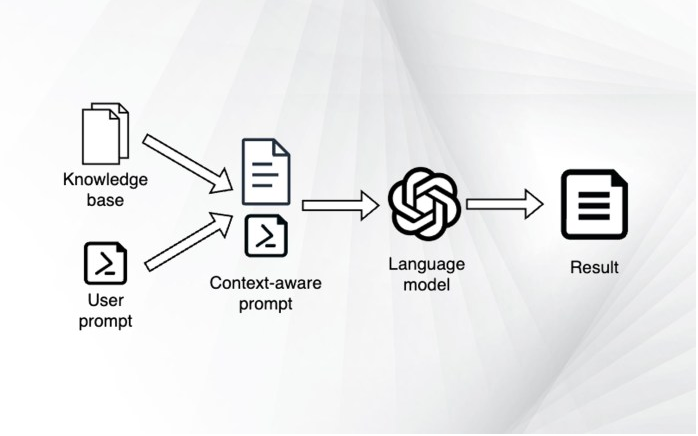
為ChatGPT提供場景
從編程的角度來看,除了第2步之外,這個過程非常簡單。那么如何決定哪個文檔與用戶的查詢相關?一個基本的答案是使用經典的索引和關鍵字搜索。更好的解決方案是使用嵌入。
嵌入是一個數字向量(一個數字列表),它捕獲了一條信息的不同特征。嵌入的維度越多,它可以學習的特征就越多。
用戶可以對不同類型的數據使用嵌入。例如,在與圖像相關的任務中,嵌入可以表示不同物體的存在與否,不同顏色的強度,不同物體之間的距離等。
在文本中,嵌入捕獲文本的不同語義方。例如,單詞嵌入可能包含有關單詞是否與城市或國家、動物物種、體育活動、政治概念等相關的信息。在同樣的意義上,短語嵌入創建了單詞序列內容的數字表示。通過測量兩個嵌入向量之間的距離,可以得到它們對應內容的相似度。
通過訓練機器學習模型(通常是深度神經網絡)在大量示例數據集上創建嵌入。在許多情況下,嵌入模型是用于最終應用(例如,文本生成或圖像分類)的相同模型的修改版本。
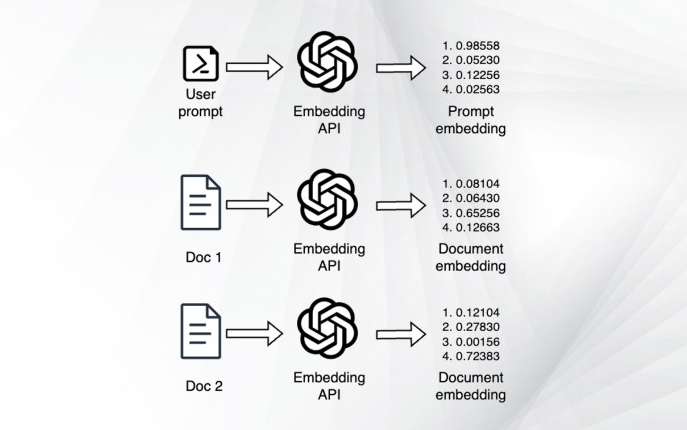
為文檔創建嵌入數據庫
要將嵌入集成到聊天機器人工作流中,用戶需要一個包含所有文檔嵌入的數據庫。如果文檔已經在數據庫中以純文本形式存在,那么就可以創建嵌入了。如果沒有,需要使用某種技術,例如使用Python Beautiful Soup的網頁抓取來從網頁中提取文本。如果其文檔是PDF文件,例如研究論文,則需要從中提取文本(可以使用Python PyPDF庫執行此操作)。
要為文檔創建嵌入,用戶可以使用在線服務,例如OpenAI的嵌入API。用戶向API提供文檔的文本,它將返回其嵌入。OpenAI的嵌入有1536個維度,是最大的嵌入之一。或者可以使用其他嵌入服務,例如Hugging Face或用戶自己的自定義Transformer模型。
一旦有了嵌入,就必須將它們存儲在“矢量數據庫”中。向量數據庫專門用于嵌入,并提供不同的功能,例如基于不同度量(歐幾里得距離,余弦相似度等)的查詢。
Facebook公司的Faiss是一個流行的開源矢量數據庫,它提供了一個豐富的Python庫來托管用戶自己的嵌入數據。另外,可以使用Pinecone,這是一個在線矢量數據庫系統,它抽象了存儲和檢索嵌入的技術復雜性。
現在,用戶已經擁有了創建針對自己的專有數據定制的大型語言模型應用程序所需的一切。現在可以像下面這樣改變應用程序的邏輯:
- 用戶輸入提示
- 為用戶提示創建嵌入
- 在嵌入數據庫中搜索最接近提示嵌入的文檔
- 檢索文檔的實際文本
- 創建一個新的提示,其中包括用戶的問題以及文檔中的場景
- 給語言模型提供新制作的提示
- 將答案返回給用戶
- 獎勵:提供一個鏈接到文件,用戶可以進一步獲取信息
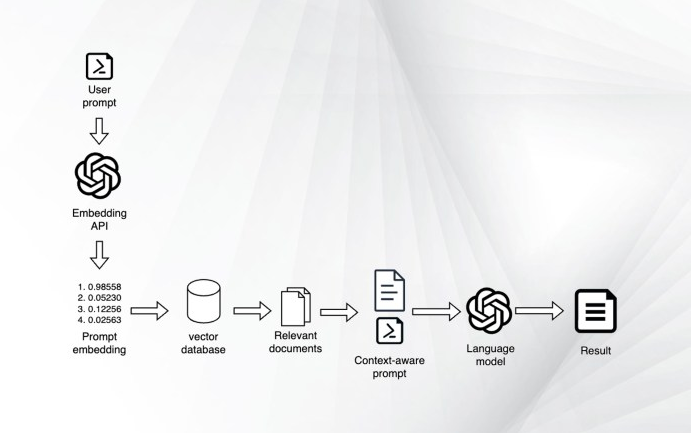
使用嵌入和矢量數據庫檢索相關文檔
為了避免人工創建整個工作流,用戶可以使用LangChain,這是一個用于創建大型語言模型應用程序的Python庫。LangChain支持不同類型的大型語言模型和嵌入式,包括OpenAI、Cohere、AI21Labs以及開源模型。它還支持不同的矢量數據庫,包括Pinecone和FAISS。它為不同類型的應用程序提供了現成的模板,包括聊天機器人、問答和活動代理。
關于嵌入的重要考慮
為了正確使用大型語言模型的嵌入,需要記住以下事項:
- 在用戶使用的嵌入框架中保持一致:確保在整個應用程序中使用相同的嵌入模型。例如,如果用戶選擇OpenAI嵌入,需要確保使用相同的API和模型來創建文檔嵌入、用戶提示嵌入和搜索矢量數據庫。否則,將得到不一致的結果。
- 令牌限制:每個大型語言模型都有令牌限制。例如,ChatGPT可以保留多達4096個令牌的場景。GPT-4有8000個和32000個令牌限制。許多開源模型限制為2048個令牌。這包括文檔場景、用戶提示和模型響應。因此,用戶必須確保場景數據不會填滿大型語言模型的內存。一個良好的經驗法則是將文檔限制為1000個令牌。如果文檔比這個大,可以將其分成幾個塊,每個部分之間有一點重疊(大約100個令牌)。
- 使用多個文檔:用戶的回復不必局限于單個文檔。可以檢索嵌入與提示符相似的幾個文檔,并使用它們來獲取響應。為了確保不會遇到令牌限制,可以為每個文檔分別提示模型。
為什么不微調大型語言模型呢?
為什么不用微調大型語言模型來代替場景嵌入?微調是一個很好的選擇,使用它取決于用戶的應用程序和資源。通過適當的微調,用戶可以從大型語言模型中獲得良好的結果,而無需提供場景數據,從而降低了付費API的令牌和推理成本。然而,微調可能是昂貴和復雜的。使用場景嵌入是一種簡單的選擇,能夠以最小的成本和努力實現。
最后,如果用戶有一個良好的數據收集管道,可以通過根據其目的的微調模型來改進系統。



























