多元時序預測:獨立預測 or 聯合預測?
今天介紹一篇南大今年4月份發表的文章,主要探討了多元時間序列預測問題中,獨立預測(channel independent)和聯合預測(channel dependent)二者效果的差異、背后的原因以及優化方法。

論文標題:The Capacity and Robustness Trade-off: Revisiting the Channel Independent Strategy for Multivariate Time Series Forecasting
下載地址:https://arxiv.org/pdf/2304.05206v1.pdf
1、獨立預測和聯合預測
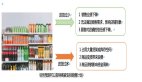
多元時間序列預測問題中,從多變量建模方法的維度有兩種類型,一種是獨立預測(channel independent,CI),指的是把多元序列當成多個單變量預測,每個變量分別建模;另一種是聯合預測(channel dependent,CD),指的是多變量一起建模,考慮各個變量之間的關系。二者的差異如下圖。

這兩種方式各有特點:CI方法只考慮單個變量,模型更簡單,但是天花板也較低,因為沒有考慮各個序列之間的關系,損失了一部分關鍵信息;而CD方法考慮的信息更全面,但是模型也更加復雜。
2、哪種方法更好
文中首先做了詳細的對比實驗,在多個數據集,觀察CI方法和CD方法哪種效果更好(采用線性模型)。文中實驗得到的一個核心結論是:CI方法在大多數任務上表現的更好,并且效果方差也更小。下面這張圖中可以看到,CI的MAE、MSE等指標在各個數據集上基本都小于CD,同時效果的波動也更小一些。

從下面的實驗結果可以看到,CI相比CD,在絕大多數預測窗口長度和數據集上,效果都是提升的。

為什么CI方法在實際應用中比CD效果更好、更穩定呢?文中進行了一些理論證明,核心的結論是:真實數據往往存在Distribution Drift,而使用CI方法有助于緩解這個問題,提升模型泛化性。下面這張圖,展示了各個數據集trainset和testset的ACF(自相關系數,反映了未來序列和歷史序列之間的關系)隨時間變化分布,可以看到Distribution Drift在各個數據集上是廣泛存在的(也就是trainset的ACF和testset的ACF不同,即兩者的歷史與未來序列的關系不同)。

文中通過理論證明了CI對于緩解因此Distribution Drift有效,CI和CD之間的選擇,是一種模型容量和模型魯棒性之間的權衡。CD模型更加復雜,但是也對于Distribution Drift更敏感。這其實和模型容量與模型泛化性之間的關系類似,越復雜的模型,模型擬合的訓練集樣本越準確,但是泛化性較差,一旦訓練集和測試集分布差異較大,效果就會變差。
3、如何優化
針對CD建模的問題,文中提出了一些優化方法,可以幫助CD模型更具魯棒性。
正則化:引入一個正則化損失,用序列減去最近的樣本點作為歷史序列輸入模型進行預測,同時使用平滑約束預測結果,讓預測結果和最近鄰的觀測值偏差不要太大,使得預估結果更平;

低秩分解:將全連接參數矩陣分解成兩個低階矩陣,相當于減少了模型容量,緩解過擬合問題,提升模型魯棒性;
損失函數:采用MAE替代MSE,降低模型對于異常值的敏感度;
歷史輸入序列長度:對于CD模型來說,輸入的歷史序列越長,可能反而會造成效果的下降,也是因為歷序列越長,模型越容易受到Distribution Shift的影響,而對于CI模型,增長歷史序列長度可以比較穩定的提升預測效果。
4、實驗效果
文中將上面提到的改進CD模型的方法在多個數據集上進行實驗,相比CD取得比較穩定的效果提升,說明上述方法對于提升多元序列預測魯棒性有比較明顯的作用。此外,文中也列舉了低秩分解、歷史窗口長度、損失函數類型等對于效果的影響實驗結果。