













作者 | 蔡柱梁
審校 | 重樓
目錄
- ES是什么
- 倒排索引
- 使用ES必須知道的基本概念
- 了解常用的DSL
1 ES是什么
Elasticsearch 是一個(gè)分布式的 RESTful 搜索和分析引擎,可用來(lái)集中存儲(chǔ)您的數(shù)據(jù),以便您對(duì)形形色色、規(guī)模不一的數(shù)據(jù)進(jìn)行搜索、索引和分析。
上面是??官網(wǎng)-API文檔??對(duì)的定位描述。ES 是一個(gè)分布式的搜索引擎,數(shù)據(jù)存儲(chǔ)形式與我們常用的 MySQL 的存儲(chǔ)形式 — rows 不同,ES 會(huì)將數(shù)據(jù)以 JSON 結(jié)構(gòu)存儲(chǔ)到一個(gè)文檔。一個(gè)文檔寫入 ES 后,我們可以在 1 秒左右查詢到它,因此我們稱 ES 在分布式中數(shù)據(jù)查詢是準(zhǔn)實(shí)時(shí)的。
提問(wèn):那么這種將一行行數(shù)據(jù)變成
我們傳統(tǒng)的關(guān)系型數(shù)據(jù)庫(kù)一般的存儲(chǔ)形式是數(shù)據(jù)結(jié)構(gòu)不固定,長(zhǎng)度不固定。這時(shí)如果用關(guān)系型數(shù)據(jù)庫(kù)做存儲(chǔ),那么我們表設(shè)計(jì)上,只能用一個(gè)
為了可以適應(yīng)高并發(fā),又能快速檢索、分析數(shù)據(jù)的搜索分析引擎,像倒排索引實(shí)現(xiàn)可以通過(guò)詞條快速查找文檔的,而倒排索引的實(shí)現(xiàn)與這種文檔存儲(chǔ)數(shù)據(jù)的方式密不可分。
ES 的適用場(chǎng)景所具有的特點(diǎn):
- 海量數(shù)據(jù)的搜索服務(wù)
- 對(duì)實(shí)時(shí)性要求較高
- 對(duì)事務(wù)要求不高
2 倒排索引
倒排索引是文檔檢索系統(tǒng)中最常用的數(shù)據(jù)結(jié)構(gòu)。
說(shuō)到幫助搜索引擎檢索數(shù)據(jù)的數(shù)據(jù)結(jié)構(gòu),我們最熟悉的應(yīng)該就是倒排索引了。過(guò)去很多人喜歡用字典來(lái)舉例,因?yàn)樗脑砗臀覀兪褂弥形淖值洳檎覞h字是相似的。
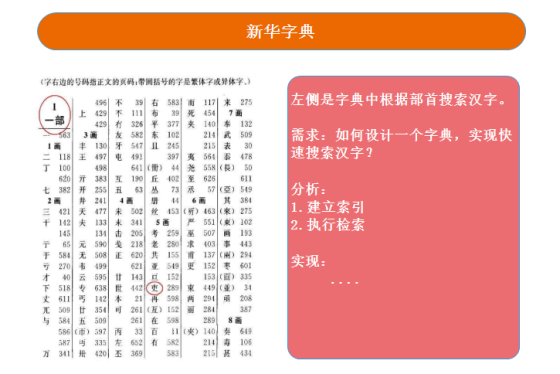
ES 會(huì)在我們保存一份文檔的時(shí)候,將文檔根據(jù)指定分詞器進(jìn)行分詞,然后維護(hù)關(guān)鍵詞和文檔的關(guān)系——倒排索引。后面我們通過(guò)一些詞條進(jìn)行檢索的時(shí)候,就可以通過(guò)這個(gè)索引找到對(duì)應(yīng)相關(guān)的文檔。
2.1 例子
下面舉個(gè)例子。
插入兩份文檔,內(nèi)容如下:
- we like java java java
- we like lucene lucene lucene
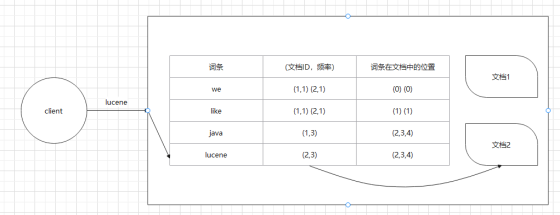
建立倒排索引大體流程如下:
- 首先對(duì)所有數(shù)據(jù)的內(nèi)容進(jìn)行拆分,拆分成唯一的一個(gè)個(gè)詞語(yǔ)(詞條)
- 然后建立詞條和對(duì)應(yīng)文檔的對(duì)應(yīng)關(guān)系,具體如下:
詞條? | (文檔ID,頻率)? | 詞條在文檔中的位置? |
we | (1,1) (2,1) | (0) (0) |
like | (1,1) (2,1) | (1) (1) |
java | (1,3) | (2,3,4) |
lucene | (2,3) | (2,3,4) |
注意:這里用表格來(lái)展示是為了方便理解,但是倒排索引其實(shí)是樹結(jié)構(gòu)。
那這時(shí)我檢索詞條:
3 使用ES必須知道的基本概念
這里的概念是我們?cè)谑褂眠^(guò)程中絕對(duì)無(wú)法繞開(kāi)的概念,所以我們需要知道,否則無(wú)法和同事交流,哪怕僅僅是使用級(jí)別。
3.1 document(文檔)
在 ES 中,一份文檔相當(dāng)于 MySQL 中的一行記錄,數(shù)據(jù)以 JSON 格式保存。文檔被更新時(shí),版本號(hào)會(huì)被增加。
3.2 Index(索引)
存儲(chǔ)文檔的地方,類似 MySQL 中的表。
3.3 Mapping(映射)
映射是定義一個(gè)文件和它所包含的字段如何被存儲(chǔ)和索引的過(guò)程(??這是官方定義??)。
文檔里面有許多字段,這些字段有自己的類型,采用什么分詞器等等,我們可以通過(guò)。
3.4 type(類型)
這是比較老舊版本會(huì)用到的定義,在 ES5 的時(shí)代,它可以對(duì) Index 做更精細(xì)地劃分,那個(gè)時(shí)代的 Index 更像 MySQL 的實(shí)例,而 type 類似 MySQL 的 table。
ES 5.x 中一個(gè)index可以有多種type。
ES 6.x 中一個(gè)index只能有一種type。
ES 7.x 以后,將逐步移除type這個(gè)概念,現(xiàn)在的操作已經(jīng)不再使用,默認(rèn)_doc。
4 了解常用的DSL
在 MySQL 中,我們經(jīng)常使用 SQL 通過(guò)客戶端操作 MySQL,而 DSL 正是我們通過(guò)客戶端發(fā)送給 ES 的操作指令。
下面只寫一些現(xiàn)在我們常常接觸的簡(jiǎn)單的 DSL,更多的請(qǐng)看 官網(wǎng)。
4.1 Index
官網(wǎng)API:??https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-index_.html??
4.1.1 創(chuàng)建索引
可以先建索引,再設(shè)置 mapping,也可以直接一次完成。
一次建好
4.1.2 查詢 index 信息
GET index_name
4.1.3 刪除 index
DELETE index_name
4.1.4 關(guān)閉 index
POST index_name/_close
當(dāng)索引進(jìn)入關(guān)閉狀態(tài),是不能操作文檔的。
4.1.5 打開(kāi) index
POST index_name/_open
4.1.6 Aliases(別名) & Reindex
實(shí)際工作中,有很多情況可能都會(huì)需要重建 index,同時(shí)將舊的數(shù)據(jù)遷移到新 index 上,并且期望這個(gè)過(guò)程可以零停機(jī),那么這時(shí)我們就可以用到 aliases 和 reindex 了。
事實(shí)上,我們程序訪問(wèn) index,很少是訪問(wèn)真正的 indexName,一般我們會(huì)對(duì) index 建別名,程序訪問(wèn)的是別名。因?yàn)槿绻褂脛e名,那么此別名背后的索引需要進(jìn)行更換的時(shí)候?qū)Τ绦蚩梢宰龅綗o(wú)感知。
下面是一個(gè)需要添加分詞器而導(dǎo)致需要重建 index 和數(shù)據(jù)遷移的場(chǎng)景(這里只是舉個(gè)簡(jiǎn)單場(chǎng)景,方便感受這些命令如何使用而已)。
1)先建立了一個(gè) person,具體如下:
2)后端程序訪問(wèn)是用別名
3)添加了一些數(shù)據(jù)
4)添加分詞器,更改 mapping 設(shè)置
5)別名操作(支持多個(gè)操作,并具有原子性)
這時(shí)我們后端程序只能對(duì) person_index 進(jìn)行讀操作,無(wú)法進(jìn)行寫操作。
6)將 person 中的數(shù)據(jù)導(dǎo)入到 person2 中(如果是不同進(jìn)程,支持遠(yuǎn)程訪問(wèn))
7)去掉 person
這時(shí)后端程序?qū)?person_index 的讀寫操作均恢復(fù)正常。
更多信息可以查閱官網(wǎng):??reindex??? ??aliases??
4.2 設(shè)置 Mapping
添加 index。
已經(jīng)建好索引 person,但是沒(méi)有設(shè)置 mapping,現(xiàn)在設(shè)置。
index 確定后,不能修改已有字段,只能添加,以下增加一個(gè) test字段作為例子。
查詢 mapping 信息
4.3 使用頻率較高的查詢
這里只寫一些比較常接觸的語(yǔ)句,不過(guò)像 wildcard 這種,也有很多公司是禁止使用的,所以用的時(shí)候一定要了解公司規(guī)范要求。
先設(shè)置一個(gè)商品 index,具體如下:
字段說(shuō)明:
- title:商品標(biāo)題
- price:商品價(jià)格
- num:商品庫(kù)存
- category:商品類別
- brand:品牌名稱
4.3.1 分頁(yè)與排序
4.3.1.1 深度翻頁(yè)
ES 深度分頁(yè)存在的問(wèn)題:
- 性能問(wèn)題
- 深度分頁(yè)會(huì)導(dǎo)致搜索引擎遍歷大量的數(shù)據(jù),因此會(huì)對(duì)性能產(chǎn)生負(fù)面影響。尤其是在數(shù)據(jù)量龐大的情況下,可能會(huì)導(dǎo)致搜索請(qǐng)求變得非常慢。
- 排序問(wèn)題
- 這是由于不同分片上的數(shù)據(jù)排序不一致所導(dǎo)致的(每個(gè)分片需要將自己的處理結(jié)果給到協(xié)調(diào)節(jié)點(diǎn),再由協(xié)調(diào)節(jié)點(diǎn)來(lái)計(jì)算出最后的結(jié)果)。
- 索引更新問(wèn)題
- 如果在進(jìn)行深度分頁(yè)時(shí),索引被更新了,那么可能會(huì)導(dǎo)致部分?jǐn)?shù)據(jù)被遺漏或重復(fù)顯示(為了避免這個(gè)問(wèn)題,可以使用游標(biāo)或滾動(dòng)搜索等機(jī)制來(lái)遍歷數(shù)據(jù))。
- 內(nèi)存問(wèn)題
- 在進(jìn)行深度分頁(yè)時(shí),Elasticsearch 需要將所有的搜索結(jié)果都存儲(chǔ)在內(nèi)存中。如果結(jié)果集非常大,那么會(huì)占用大量的內(nèi)存,甚至可能導(dǎo)致內(nèi)存溢出(為了避免這個(gè)問(wèn)題,可以使用游標(biāo)或滾動(dòng)搜索等機(jī)制來(lái)逐步處理數(shù)據(jù))。
在 Elasticsearch 7.0 之前,我們是采用 scroll 來(lái)解決深度分頁(yè)的,但是到了 Elasticsearch 7.0 就開(kāi)始不再推薦采用 scroll 了,推薦采用 search_after。
4.3.1.1.1 scroll
詳細(xì)請(qǐng)看??官方文檔??。
以下例子來(lái)自于官網(wǎng)
1)先查詢并生成快照
scroll=1m 是保留1分鐘快照的意思,即是符合當(dāng)前查詢條件的數(shù)據(jù)的結(jié)果集合保留快照1分鐘
假設(shè)返回的 scroll_id 是 DXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAD4WYm9laVYtZndUQlNsdDcwakFMNjU1QQ==
2)那么,我們就可以使用這個(gè) ID 進(jìn)行滾動(dòng)翻頁(yè)了
3)查詢完后,記得刪除游標(biāo)
這里詳細(xì)說(shuō)下游標(biāo)的工作方式:
當(dāng)?shù)谝淮伟l(fā)起 scroll 請(qǐng)求時(shí),ES 會(huì)創(chuàng)建一個(gè)包含搜索結(jié)果的快照,并返回一個(gè)唯一的滾動(dòng) ID。在接下來(lái)的每個(gè) scroll 請(qǐng)求中,都需要帶上這個(gè)滾動(dòng) ID,表示要獲取與該搜索上下文匹配的下一批結(jié)果。因?yàn)槊總€(gè) scroll 請(qǐng)求都使用了相同的搜索上下文,所以每個(gè)請(qǐng)求返回的結(jié)果都是相同的,只是可能包含不同的文檔。如果 scroll 請(qǐng)求返回的結(jié)果集合大小不足以填滿請(qǐng)求的大小限制,則 ES 會(huì)在后臺(tái)繼續(xù)搜索,并將結(jié)果添加到當(dāng)前結(jié)果集中,直到結(jié)果集合大小達(dá)到請(qǐng)求的大小限制或搜索完成為止。
由于 scroll 機(jī)制的實(shí)現(xiàn)方式,每次請(qǐng)求返回的結(jié)果可以是任意大小,可以避免一次性讀取所有結(jié)果可能導(dǎo)致的內(nèi)存問(wèn)題。同時(shí),由于滾動(dòng) ID 只在指定的時(shí)間段內(nèi)有效,所以可以在不消耗過(guò)多內(nèi)存的情況下,分批次處理大量數(shù)據(jù)。但是,需要注意的是,如果時(shí)間段設(shè)置得過(guò)短,可能會(huì)導(dǎo)致滾動(dòng) ID 過(guò)期,需要重新發(fā)起搜索請(qǐng)求。
4.3.1.1.2 search_after
詳細(xì)請(qǐng)看??官網(wǎng)??。
以下例子來(lái)自于官網(wǎng)
1)先查詢
假設(shè)響應(yīng)如下:
2)接著,使用上面響應(yīng)結(jié)果中最后一個(gè)文檔的排序鍵
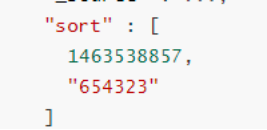
作為參數(shù)傳遞到下一次查詢中(這里其實(shí)就是對(duì)應(yīng)了查詢示例中的兩個(gè)排序字段 date 和 tie_breaker_id)
這里有一個(gè)問(wèn)題,如果我在第2頁(yè)準(zhǔn)備翻到第3頁(yè)時(shí),refresh 了可能會(huì)打亂排序,那么這個(gè)分頁(yè)的結(jié)果就不對(duì)了。為了避免這種情況,我們可以使用 PIT 來(lái)保存當(dāng)前搜索的索引狀態(tài)。
具體使用如下:
1)先得到 PIT ID
響應(yīng)如下:
2)使用 PIT ID 搜索
響應(yīng)如下:
3)pit id + 排序鍵 翻頁(yè)
4)查詢完后,刪除 PIT
scroll 和 search after 都是用來(lái)處理大數(shù)據(jù)時(shí)避免深度翻頁(yè)的,它們區(qū)別如下:
- 實(shí)現(xiàn)方式不同
- scroll 使用游標(biāo)來(lái)保持搜索上下文,而 search after 使用排序鍵來(lái)跟蹤搜索進(jìn)度。
- 參數(shù)設(shè)置不同
- scroll 需要指定一個(gè)時(shí)間段來(lái)保持搜索上下文,而 search after 需要指定一個(gè)排序字段和一個(gè)起始排序鍵來(lái)開(kāi)始搜索。
- 數(shù)據(jù)處理方式不同
- scroll 適用于一次性處理所有數(shù)據(jù)的場(chǎng)景,每次請(qǐng)求返回的結(jié)果可以是任意大小,直到搜索上下文過(guò)期或搜索完成為止。而。
- 排序方式不同
- scroll 可能會(huì)導(dǎo)致排序不穩(wěn)定的問(wèn)題,而 search after 使用排序鍵來(lái)跟蹤搜索進(jìn)度,可以避免這個(gè)問(wèn)題。
- 兼容性不同
- scroll 是 Elasticsearch 5.x 及之前版本的遺留功能,而 search after 是 Elasticsearch 7.0 中引入的新特性,Elasticsearch 7.0 開(kāi)始推薦使用 search after。
4.3.2 match
想對(duì)搜索關(guān)鍵字進(jìn)行分詞,搜索的結(jié)果更全面。
特點(diǎn)
- 會(huì)對(duì)查詢條件進(jìn)行分詞
- 然后將分詞后的查詢條件和詞條進(jìn)行等值匹配
- 默認(rèn)取并集
4.3.3 term
不想對(duì)搜索關(guān)鍵字進(jìn)行分詞,搜索的結(jié)果更加精確。
4.3.4 range
當(dāng)想對(duì)數(shù)值類型的字段做區(qū)間的搜索,例如商品價(jià)格。
4.3.5 wildcard
當(dāng)使用match搜索仍然查詢不到數(shù)據(jù),可以嘗試使用模糊查詢,范圍更廣。
運(yùn)行結(jié)果:
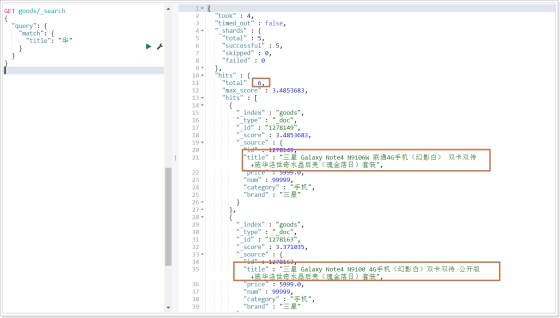
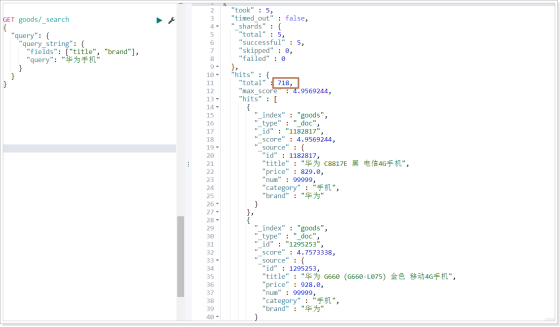
可以發(fā)現(xiàn)查詢的結(jié)果中,那些title包含“華為”的數(shù)據(jù)查不出來(lái),因?yàn)槟切?shù)據(jù),沒(méi)有分出"華"這一個(gè)字,而分出的就是"華為",這個(gè)時(shí)候我們?nèi)粝氚寻?華為"的數(shù)據(jù)都查出來(lái),就可以使用模糊查詢。
4.3.6 query_string
當(dāng)不知道搜索的內(nèi)容存儲(chǔ)在哪個(gè)字段時(shí),可以使用字符串搜索。
特點(diǎn)
- 會(huì)對(duì)查詢條件進(jìn)行分詞
- 將分詞后的查詢條件和詞條進(jìn)行等值匹配
- 默認(rèn)取并集(OR)
- 可以指定多個(gè)查詢字段
1)不指定字段
2)指定字段
運(yùn)行結(jié)果:
4.3.7 bool?
當(dāng)存在多個(gè)查詢條件時(shí)
語(yǔ)法
must(and):條件必須成立。
must_not(not):條件必須不成立,必須和must或filter連接起來(lái)使用。
should(or):條件可以成立。
filter:條件必須成立,性能比must高(不會(huì)計(jì)算得分)。
運(yùn)行結(jié)果:

4.3.8 Aggregations?
聚合查詢
聚合類型:
- 指標(biāo)聚合:相當(dāng)于MySQL的聚合函數(shù)。比如max、min、avg、sum等。
- 桶聚合:相當(dāng)于MySQL的 group by 操作。(不要對(duì)text類型的數(shù)據(jù)進(jìn)行分組,會(huì)失敗)
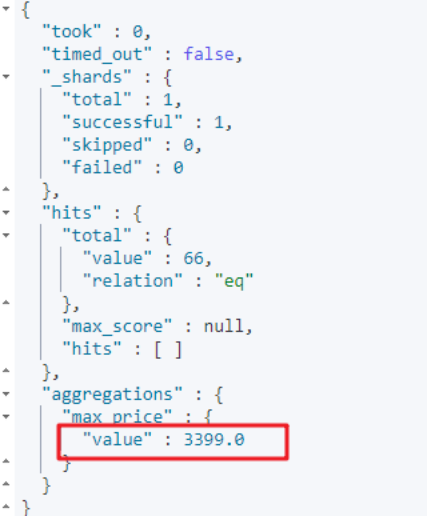
4.3.8.1 指標(biāo)聚合
運(yùn)行結(jié)果:
4.3.8.2 桶聚合
運(yùn)行結(jié)果:

4.3.9 highlight(高亮查詢)
運(yùn)行結(jié)果:

5 總結(jié)
這篇文章的宗旨是希望可以幫助剛接觸ES 的人可以快速了解ES,和掌握ES 的一些常用查詢。

















