如何用Apache Kafka搭建可擴展的數據架構?
譯文?Apache Kafka是一種基于發布者-訂閱者模型的分布式消息傳遞系統。它由Apache軟件基金會開發,用Java和Scala編寫。Kafka的初衷是為了克服傳統消息傳遞系統的分布和可擴展性面臨的問題。它可以處理和存儲大量數據,具有延遲低、吞吐量高的優點。因此,它適用于構建實時數據處理應用程序和流媒體服務。它目前已開源,被Netflix、沃爾瑪和領英等許多組織使用。
消息傳遞系統使多個應用程序可以相互收發數據,不用擔心數據的傳輸和共享。點到點和發布者-訂閱者是兩種廣泛使用的消息傳遞系統。在點到點模型中,發送方將數據推送到隊列,接收方從隊列中彈出數據,就像遵循先進先出(FIFO)原則的標準隊列系統一樣。此外,一旦讀取數據,數據就被刪除,并且每次只允許一個接收方。接收方讀取消息時不存在時間依賴關系。

圖1. 點對點消息系統
在發布者-訂閱者模型中,發送方稱為發布者,接收方稱為訂閱者。在這種模型中,多個發送方和接收方可以同時讀取或寫入數據。但是它有時間依賴關系。消費者必須在一定的時間之前消費消息,因為此后消息被刪除,即使它沒有被讀取。這個時間限制可能是一天、一周或一個月,視用戶的配置而定。

圖2. 發布者-訂閱者消息系統
一、Kafka的架構
Kafka架構由幾個關鍵組件組成:
1. 主題
2. 分區
3. 代理
4. 生產者
5. 消費者
6. Kafka集群
7. Zookeeper

圖3. Kafka的架構
不妨簡單了解一下每個組件。
Kafka將消息存儲在不同的主題中。主題是一個組,含有特定類別的消息。它類似數據庫中的表。主題由名稱作為唯一標識符。不能創建名稱相同的兩個主題。
主題進一步劃分為分區。這些分區的每個記錄都與一個名為Offset的唯一標識符相關聯,該標識符表示了記錄在該分區中的位置。
除此之外,系統中還有生產者和消費者。生產者使用Producing API編寫或發布主題中的數據。這些生產者可以在主題或分區層面寫入數據。
消費者使用Consumer API從主題中讀取或消費數據。它們還可以在主題或分區層面讀取數據。執行類似任務的消費者將組成一個組,名為消費者組。
還有其他系統,比如代理(Broker)和Zookeeper,它們在Kafka服務器的后臺運行。代理是維護和保存已發布消息記錄的軟件。它還負責使用offset以正確的順序將正確的消息傳遞給正確的使用者。相互之間進行集體通信的代理集可以稱為Kafka集群。代理可以動態添加到Kafka集群中或從集群中動態刪除,系統不會遇到任何停機。Kafka集群中的其中一個代理名為控制器。它負責管理集群內的狀態和副本,并執行管理任務。
另一方面,Zookeeper負責維護Kafka集群的健康狀態,并與該集群的每個代理進行協調。它以鍵值對的形式維護每個集群的元數據。
本教程主要介紹實際實現Apache Kafka的例子。
二、出租車預訂應用程序:實際用例
以優步之類的出租車預訂服務這一用例為例。這個應用程序使用Apache Kafka通過各種服務(比如事務、電子郵件、分析等)發送和接收消息。

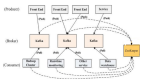
圖4出租車應用程序架構圖
架構由幾個服務組成。Rides服務接收來自客戶的打車請求,并將打車詳細信息寫入到Kafka消息系統上。
然后,Transaction服務讀取這些訂單詳細信息,確認訂單和支付狀態。在確認這趟打車之后,該Transaction服務將再次在消息系統中寫入確認的打車信息,并添加一些額外的詳細信息。最后,電子郵件或數據分析等其他服務讀取已確認的打車細節,并向客戶發送確認郵件,并對其進行一些分析。
我們可以以非常高的吞吐量和極小的延遲實時執行所有這些進程。此外,由于Apache Kafka能夠橫向擴展,我們可以擴展這個應用程序以處理數百萬用戶。
三、上述用例的實際實現
本節包含在我們的應用程序中實現Kafka消息系統的快速教程。它包括下載和配置Kafka、創建生產者-消費者函數的步驟。
注意:本教程基于Python編程語言,使用Windows機器。
1.Apache Kafka下載步驟
1)從這個鏈接(https://kafka.apache.org/downloads)下載最新版本的Apache Kafka。Kafka基于JVM語言,所以必須在系統中安裝Java 7或更高版本。
2) 從計算機的C:驅動器解壓已下載的zip文件,并將文件夾重命名為/apache-kafka。
3)父目錄包含兩個子目錄:/bin和/config,分別含有Zookeeper和Kafka服務器的可執行文件和配置文件。
2.配置步驟
首先,我們需要為Kafka和Zookeeper服務器創建日志目錄。這些目錄將存儲這些集群的所有元數據以及主題和分區的消息。
注意:默認情況下,這些日志目錄創建在/tmp目錄中,這是一個易變目錄:當系統關閉或重啟時,該目錄中的所有數據都會消失。我們需要為日志目錄設置永久路徑來解決這個問題。不妨看看怎么做。
導航到apache-kafka >> config,打開server.properties文件。在這里您可以配置Kafka的許多屬性,比如日志目錄路徑、日志保留時間和分區數量等。
在server.properties文件中,我們必須將日志目錄文件的路徑從臨時/tmp目錄改為永久目錄。日志目錄含有Kafka Server中的生成或寫入的數據。若要更改路徑,將log.dirs變量由/tmp/kafka-logs改為c:/apache-kafka/kafka-logs。這將使您的日志永久存儲。
Zookeeper服務器還包含一些日志文件,用于存儲Kafka服務器的元數據。若要更改路徑,重復上面的步驟,即打開zookeeper.properties文件,并按如下方式替換路徑。
該Zookeeper服務器將充當Kafka服務器的資源管理器。
四、運行Kafka和Zookeeper服務器
若要運行Zookeeper服務器,在父目錄中打開一個新的cmd提示符,并運行以下命令。

圖5
保持Zookeeper實例運行。
若要運行Kafka服務器,打開一個單獨的cmd提示符,并執行以下代碼:
保持Kafka和Zookeeper服務器運行;在下一節中,我們將創建生產者和消費者函數,它們用于讀取數據并將數據寫入到Kafka服務器。
五、創建生產者和消費者函數
為了創建生產者和消費者函數,我們將以前面討論的電子商務應用程序為例。“訂單”服務將充當生產者,將訂單細節寫入到Kafka服務器,而電子郵件和分析服務將充當消費者,從服務器讀取該數據。交易服務將充當消費者和生產者。它讀取訂單詳細信息,并在交易確認后再次將它們寫回來。
但首先我們需要安裝Kafka Python庫,該庫含有生產者和消費者的內置函數。
現在,創建一個名為kafka-tutorial的新目錄。我們將在該目錄中創建含有所需函數的Python文件。
生產者函數:
現在,創建一個名為' rides.py '的Python文件,并將以下代碼粘貼到其中。
解釋:
首先,我們導入了所有必要的庫,包括Kafka。然后,定義主題名稱和各項目的列表。記住,主題是一個含有類似類型消息的組。在本例中,該主題將包含所有訂單。
然后,我們創建一個KafkaProducer函數的實例,并將其連接到在localhost:9092上運行的Kafka服務器。如果您的Kafka服務器在不同的地址和端口上運行,那么您必須在那里提及服務器的IP和端口號。
之后,我們將生成一些JSON格式的訂單,并根據定義的話題名稱將它們寫入到Kafka服務器。睡眠函數用于生成后續訂單之間的間隔。
消費者函數:
解釋:
transaction.py文件用于確認用戶所做的交易,并為他們分配司機和估計的載客時間。它從Kafka服務器讀取打車細節,并在確認打車后將其再次寫入到Kafka服務器。
現在,創建兩個名為email.py和analysis .py的Python文件,分別用于向客戶發送電子郵件以確認打車和執行一些分析。創建這些文件只是為了表明甚至多個消費者都可以同時從Kafka服務器讀取數據。
現在,我們已完成了應用程序。在下一節中,我們將同時運行所有服務并檢查性能。
六、測試應用程序
在四個單獨的命令提示符中逐一運行每個文件。

圖6
當打車詳細信息被推送到服務器時,您可以同時接收來自所有文件的輸出。您還可以通過刪除rides.py文件中的延遲函數來提高處理速度。'rides.py'文件將數據推送到Kafka服務器,另外三個文件同時從Kafka服務器讀取數據,并發揮相應的作用。
但愿您對Apache Kafka以及如何實現它已有了基本的了解。
七、結語
我們在本文中了解了Apache Kafka工作原理及實際實現該架構的出租車預訂應用程序用例。使用Kafka設計一條可擴展的管道需要認真計劃和實施。您可以增加代理和分區的數量,提高這些應用程序的可擴展性。每個分區都獨立處理,這樣負載可以在它們之間予以分配。此外,您還可以通過設置緩存大小、緩沖區大小或線程數量來優化Kafka配置。
本文中使用的完整代碼的GitHub鏈接如下:https://github.com/aryan0141/apache-kafka-tutorial/tree/master。
原文鏈接:https://www.kdnuggets.com/2023/04/build-scalable-data-architecture-apache-kafka.html