同為發展中國家,印度也受到空氣質量問題的困擾,本文就以印度的城市為例進行數據分析。利用簡單的Python代碼,分析城市空氣質量及其每天在全國范圍內(即印度水平)的排名。
在開始之前,先介紹一下整個分析過程中使用的一些基本原理。印度政府中央污染控制委員會(CPCB)是該國環境空氣質量監測的監管機構,每天為那些設有連續環境空氣質量監測站的印度城市發布空氣質量相關信息公告。該公告包含有特定城市的空氣質量指數(AQI)、空氣質量類別、標準污染物以及該城市運行的監測站數量相關的信息。本文正是通過分析這個空氣質量指數(AQI)來對城市進行排名。
如下所示是對于公告中一些術語的解釋:
- a)空氣質量指數(AQI):空氣質量指數是一個表示空氣質量狀況的無量綱數字。
- b)空氣質量類別或等級:根據空氣質量指數,空氣質量情況被分為6個類別,即“優秀”、“良好”、“中等”、“差”、“非常差”和“嚴重”。隨著空氣質量的下降,該類別從“優秀”到“嚴重”,表明有可能對健康產生不利影響。
- c)標準污染物:尺寸為2.5和10微米的顆粒物、二氧化氮(NO2)、二氧化硫(SO2)、一氧化碳(CO)、臭氧(O3)、氨(NH3)和鉛(Pb)是空氣質量指數計算中涉及的具有潛在不利健康影響的主要標準污染物。在計算單個污染物的空氣質量指數值時,應將空氣質量指數最高的污染物宣布為該市的空氣質量指數,并將相應的污染物宣布為標準污染物。
- d)監測站:表示該城市在特定日期內運行的空氣質量監測站的總數。這些監測站監測的污染物濃度(即標準污染物)用于評估任何城市的空氣質量指數。
進行此分析有何好處?
官員們從AQI公告中實際匯編了感興趣的城市信息。隨著所關注的城市的增加,這項工作變得更加困難,必須在下午6點前報告上級,而公告在每天4點后才發布,這可能會導致無意的人為錯誤。由于這些原因開發了這套Python代碼。這種分析的好處包括減少人工分析的人力,可靠的結果減少了人為的錯誤,提高了公眾的知識水平,提高了政策制定者做出明智選擇的能力,包括監測當地空氣質量管理的結果等。
現在開始編碼:
第1步:導入庫
導入庫numpy、requests、pandas、sys和tabula。requests?庫是為了從出版商的頁面上采集AQI公告。然后tabula?庫將PDF格式的公告讀到數據框中。pandas和numpy用作數據分析和科學計算。
## 導入庫
import pandas as pd
import requests
from tabula import read_pdf
import numpy as np
import sys
第2步:用戶定義的輸入
a)感興趣的日期(YYYYMMDD格式);
b)下載PDF格式的AQI公告文件的路徑;
c)特定城市/感興趣的城市名單(可選)。
最終分析提供了每日AQI公告中提到的所有城市的排名。然而,在提取特定城市/感興趣的城市的排名的情況下,可以在c)中提供這些城市的名單。確保與c)中提供的城市相關的信息必須出現于AQI公報中。
## 用戶輸入
date = input('a) Enter the date of interest (on or after 29th January 2018) in the format YYYYMMDD: ') ##20180129 onwards
pathway = input('b) Define the Pathway address to download the bulletin: ') ##example C:/Users/USER/Downloads
list_of_cities = input('c) Enter the list of cities separated by commas and no space: ') ##Example Mumbai,Bangalore,Kolkata. Disclaimer: Make sure the cities mentioned are present in the Bulletin list
警告:請確保調用的意向日期是在2018年1月29日或之后。
## 日期調用檢查
if date<'20180129':
sys.exit('Call the dates on or after 29th January 2018 and re-run the codes')
檢查完成后繼續進行后續步驟。
第3步:下載AQI公告
使用request?庫下載AQI公告。使用tabula庫以數據幀格式讀取下載的pdf文件。如果在用戶定義的日期內無法獲得AQI公報,運行將被終止。
## 下載公告
k = requests.get('https://cpcb.nic.in//upload/Downloads/AQI_Bulletin_'+str(date)+'.pdf')
if k.status_code==404:
sys.exit('No Bulletin exists for the mentioned date. Please try different date')
with open(pathway+'/AQI_Bulletin_'+str(date)+'.pdf','wb') as f:
f.write(k.content)
## 以數據幀格式讀取pdf
pathway = pathway+'/AQI_Bulletin_'+str(date)+'.pdf'
file = read_pdf(pathway,pages='all')
第4步:基本數據清理
在這里,刪除重復的和不適用的數據,重新設置列名,并按AQI的降序對數據框進行排序。包含AQI值的數據框列被命名為“索引”。
## 刪除重復的內容
new_file = pd.DataFrame()
for i in range (0, len(file)):
if i%2==0:
extract_file = file[i]
new_file = pd.concat([new_file,extract_file], axis=0)
## 提取列名
k= new_file.loc[0, ]
k.reset_index(inplace=True)
column_names = k.loc[1, ]
column_names = column_names[1: ]
## 重置列
new_file.columns = column_names
##從`new_file`中刪除`NA`
new_file.dropna(inplace=True)
## 按AQI的降序對數據幀進行排序
final_file = new_file.loc[(new_file['City']!='City'), ]
final_file['Index Value']= final_file['Index Value'].astype(int)
final_file.sort_values(by='Index Value',ascending=False, inplace=True)
final_file.reset_index(inplace=True)
final_file.drop(columns=['S.No', 'index'], inplace=True)
第5步:根據空氣質量指數對城市進行排名
當天擁有最高AQI值的城市獲得最高排名。輸出final_file包括根據AQI值在AQI公告中指定的城市的排名。2個或更多具有相同AQI值的城市被提供相同的排名。
## 基于AQI的城市排名
final_file['ranking'] = np.arange(1, len(final_file)+1)
for i in range(0,len(final_file)-1):
if final_file.loc[i,'Index Value']== final_file.loc[(i+1), 'Index Value']:
final_file.loc[(i+1), 'ranking']= final_file.loc[i, 'ranking']
for k in range(i+2,len(final_file)):
final_file.loc[k, 'ranking'] = final_file.loc[k, 'ranking']-1
第6步:對用戶定義的城市進行排名并生成單獨的數據幀
生成的輸出文件名為city_ranking,包含了用戶定義的特定城市的所有必要信息。
## 用戶定義的城市排名
if len(city_list)> 0:
city_list = list_of_cities.split(',')
city_ranking = final_file.loc[final_file['City'].isin(city_list), ]
數據分析
首先運行代碼。現在輸入每個用戶定義的預設條件:
- a) 輸入分析的日期,格式為YYYMMDD:20230401
- b) 定義下載公告的Pathway地址:由用戶決定,這里使用C:/Users/USER/Downloads
- c) 輸入由逗號和無空格分隔的城市列表:Mumbai、Delhi、Bangalore、Hyderabad、Ahmedabad、Chennai、Kolkata、Surat、Vadodara、Pune
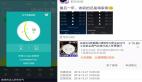
輸出如下圖所示:

輸出(city_ranking)顯示了用戶定義的城市的空氣質量狀況、指數、主要污染物、監測空氣污染的監測站數量和排名。注:在用戶定義的分析日期,AQI公報中沒有與Bangalore和Vadodara有關的信息,因此沒有顯示在數據框中。
使用這套代碼,可以了解許多有用的內容。例如,使用for循環,就可以使用來自AQI公告庫的數據,并查看數據是如何隨時間變化的。