B站基于 Flink 的海量用戶行為實時 ETL 應用實踐
1、背景
在數倉分層架構體系中,從 ODS層到 DWD層數據轉換需要進行數據清洗、脫敏、列式壓縮等步驟。在B站用戶行為埋點數據 ODS到 DWD層轉換過程中,為了解決日增千億條、20+TB/天增量規模下數據重復攝取帶來的資源嚴重消耗的問題,引入了北極星(B站用戶埋點行為分析鏈路)分流,按照部門進行分表。在埋點設計中使用spmid模型,將事件類型拆分為瀏覽 pv、曝光 show、點擊 click等多個事件類型,并以這些事件類型作為除天、小時分區以外的第三級分區,再以事件類型產品來源作為四級分區。通過基于部門業務區分按照埋點事件類型+產品來源以多表多分區控制的形式,最大程度降低下游任務文件數據攝取數量以減少資源消耗。

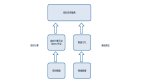
如圖所示,用戶埋點由邊緣上報 bfe-agent到網關 gateway,經過kafka數據緩沖后通過 lancer collector數據分發至 ods hive,再通過北極星分流完成 ODS到 DWD層數據轉換。DWD層數據服務于搜索推薦、推薦、廣告、AI等應用場景。在原有 ODS到 DWD數據轉換中使用Spark離線分流方案。
2、Spark離線分流方案
Spark小時任務定期調起 ETL任務完成 DWD分流、數據同步,由于在讀 ods時由于源表數據量過大造成 Spark緩存 miss,繼續分流需要重新讀全表數據存在讀放大問題造成文件重復攝取。

離線分流讀放大問題
隨著各部門中心業務的擴展,分流表日益增加,而在使用離線Spark sql分流過程中由于多表寫入會重復讀取源表數據,而源表的數據規模過大造成緩存失效,從而重復攝取源表數據的讀放大問題日漸顯現。
分流任務資源消耗高
ODS-DWD同步資源消耗因重復攝取 ODS源表文件跟隨分流表擴展持續增加,部分資源使用不合理。
DWD同步時效性低
在分區通知調度模式下,DWD層數據只會在ODS表分區通知才會進行同步,為了保證 DWD表的及時產出需大量資源滿足同步需要。在高峰期資源使用出現堆積時 ods-dwd同步容易超過1h+。
為了解決這些問題,我們引入新的解決方案--基于Flink的實時增量計算。
3、Flink實時增量計算
如下圖所示,實時北極星增量計算方案由 Flink HDFS File Source通過掃描 Lancer任務每次 checkpoint產出的可見文件進行增量消費計算,與維表數據join之后打寬,分發至 Flink Multi Hive Sink,在這里完成多表多分區分流,sink內部集成 Archer(B站大數據任務調度系統)調度下游搜索、推薦、廣告等數據分析業務。由于 Main表文件數量在實時分區寫入場景下文件數依然過高,因此在sink表之后對Main表單獨添加基于Spark的小文件合并。

增量計算方案預期收益主要包含:
- 讀放大問題解決
Flink DAG支持 Source數據下發之后可自定義分區輸出無需重復攝取,用以解決讀放大問題。
- 分流資源降低
在解決讀放大問題后,源表數據攝取只會執行一次,降低資源消耗。另外在 ODS產生一批可見文件即進行計算,最大程度降低分流任務同步資源消耗。
- 時效性提升
時效性由小時級最高可提高至分鐘級,增量計算即在 ODS產生一批文件之后就會對文件進行消費,理論最高可在 ODS分區歸檔之后的一次 Checkpoint間隔即可完成 DWD表數據完全同步。
4、多級分區小文件解決方案
實時分流在解決以上幾個問題同時,在灰度上線過程中發現文件數量相比離線分流方案增長超100倍,下游Spark分析任務在讀取實時分流表加載文件時由于文件讀放大問題導致內存不足執行失敗。于是解決小文件問題將成為該方案最終落地是否成功的關鍵。由于實時分流在每5min一次 Checkpoint執行文件斬斷會產生大量小文件,導致ns讀寫壓力變大,下游Spark在讀取目錄過程中也增加資源消耗導致任務執行超時。在分析了落地文件后發現很多小文件是由于四級分區并發度分配不合理導致 bucket的數量增加從而產生大量的小文件。因此通過在保證計算能力下盡力減少 bucket數量則可以降低打開的文件數量。
4.1 基于 Flink Partitioner Shuffle優化
在270+四級分區下,按照全并發分配模式,每天將產生約1億4千萬文件數。通過使用 Flink Partitioner,對于 Reader下發的數據按照所屬四級分區進行加簽(tag),根據每個 tag對應歷史分區落地數據大小比例配比計算subtask分配區間,在分配區間內隨機分發至某個 subtask,文件數量由原來一億四千萬/天降為150w/天。文件數縮減100+倍。
優化前
270 (四級分區) * 1800 (并發度) * 12 (每小時文件斬斷次數) * 24 (每天小時數) = 139968000 (約14000w)。
優化后
5000 (Shuffle數量) * 12(每小時文件斬斷次數) * 24 (每天小時數) = 1440000(150w) 。

如上圖所示,可能存在大量 partition僅需一個 bucket分桶即可完成文件落地,不需要所有Bucket處理。因此按照 partition所需 bucket數量進行合理分配是解決問題的關鍵。

但是這里有個弊端,在出現流量激增場景下,該方案可能會導致部分subtask熱點從而導致任務出現嚴重堆積(如佩洛西事件,導致部分subtask流量超過平時12+倍),需要手動調整 shuffle方案以消除熱點。這樣導致運維成本較高,并且用戶在使用該方案時門檻較高,需要長時間的壓測調試才能將多分區之間的比例調整均勻。如果能夠將實時作業處理能力與文件數量之間根據流量自動平衡,這樣運維成本可以降低另外用戶在使用時無門檻,只需配置開關即可。因此提出 Auto Shuffle推測執行以解決小文件合并問題。
4.2 Auto Shuffle推測執行小文件解決方案

1、支持自定義分桶 Tag規則
根據 row的字段來確認分桶的規則,支持根據udf自定義。
2、計算 row的大小
直接按照 row字節數大小計算,即為row的壓縮前大小。
3、滾動窗口+類背包算法+統一字典排序
滾動窗口
以環形數組的形式記錄配額,配額在分配后,各個 subtask對桶內的更新相互間未知的,很容易造成單桶超過8g,現在想到的解決辦法是通過8G/一個小時內滾動時間窗口的次數/并發度來調整。
統一字典排序
主要目標是為了合并背包算法結果,盡可能將不同 subtask相同tag分發到相同的桶里(由于tag分發排序不穩定)。上線選擇使用 tag hashcode排序,減少計算量。
加簽背包算法
類似Flink1.12小文件合并采用的BinPack策略,在此基礎上添加Tag識別,每個分桶歸屬于單個Tag。注意在使用以上基于weight加簽背包的計算結果 shuffle時,容易受到作業反壓的影響從而導致上圖 shuffle operator接收到的數據變少,由于JM無法區分流量降低和反壓影響,因此會根據 weight主動降低 subtask配額,這樣會導致shuffle算子后續算子處理能力下降,繼而增加反壓陷入惡性循環,在測試過程中效果表現不佳。后續在參考根據各四級分區落地文件大小預設比例的思想,取消主動降低 subtask配額的操作,按照上游分發的大小按比例分配subtask,效果表現良好,但文件數量會略高于預設比例(比例調整會導致文件數量增加)。
4、維護比例模型狀態
在堆積恢復時按照重啟前最后一次生成的比例模型來計算 subtask分發,減少因啟動造成文件數膨脹問題(486000單次checkpoint增量)。
5、冷啟動問題解決
由于冷啟動時,沒有流量參考,為了降低文件數只能通過計算tag占用方式分發subtask,這樣的累加操作為O(n),在初始化時cpu壓力較大,吞吐不達預期。因此支持UDF預設置tag規則以及比例,按照該比例進行預分發,在第一次窗口計算前按照預設比例進行O(1)分發。
5、Flink增量計算方案落地
在落地過程中,我們面臨很多問題和挑戰,尤其是在降本增效的大背景下,對于新方案落地提出了高要求。首先面臨的是在資源緊缺情況下如何適應相對物理機集群而言環境較為惡劣的混部集群。在混部環境下需要實時任務做到以下幾點:
- (事前)分流任務穩定性提升
- (事中)分流任務需快速恢復,即 Fast-FailOver
- (事后)分流任務頻繁重啟下不影響數據質量
基于這樣的要求,在實時分流任務中在 Flink Runtime\SQL\Connector以及實時平臺層應用很多功能優化以滿足要求。

5.1 分流任務穩定性提升
首先影響任務穩定的主要有以下幾點:
- JobManager穩定性問題
- Subtask間負載均衡
- Subtask熱點傾斜
解決方案:
5.1.1 JobManager穩定性問題解決
- Metrics Disabled
我們在查找 JobManager掛的RC過程中,發現經常由于 JobManager OOM導致任務重啟,尤其在打開原生監控時經常出現。在 Dump內存進行分析后發現,Jobmanager內存80%以上存儲的是各個 TM上報的 Metrics,由于打開原生監控會主動 pull額外的Metrics從而加重內存壓力導致 OOM。因此實現 Metrics Disabled關閉部分Metrics對JM上報,問題解決。
- JobManager HA
在混部環境下 JobManger常會因所在 Container被驅逐而導致Jobmanager掛掉。因此通過開啟JM HA在JobManger掛掉的過程中,保持TM運行狀態,并重連JobMaster,取消社區JM心跳超時就Cancel Task的行為以保證任務持續穩定運行。
5.1.2 Subtask間負載均衡
- 基于backlog負載均衡
非hash shuffle場景下,Flink默認提供了rebalance或rescale partitioner用于在下游算子的不同并行度間均勻地分發數據(round-robin方式)。在環境問題(例如機器異構等)導致下游算子的不同并行度之間處理能力不均衡時,會導致部分subtask數據堆積,造成反壓。為此,我們引入了下游subtask之間的負載均衡機制,并默認提供了基于backlog進行負載均衡的實現。通過運用該負載均衡機制,可以使得數據根據下游subtask的處理能力進行分發,減少環境問題導致的反壓等問題。
5.1.3 Subtask傾斜問題解決
- Reader File Split負載均衡
File Split在 Round Robin分發時,由于split大小不同以及機器異構等原因,造成部分subtask處理split速度變慢導致熱點堆積。通過JobManager維護Reader算子運行狀態,在Monitor異步線程分發時根據各reader算子是否空閑來分配split,以類似生產者-消費者模式實現Reader算子對于File split處理負載均衡。
5.2 分流任務快速恢復
由于實時分流任務以較小資源流式增量消費,在北極星較大流量場景下任務在重啟的幾分鐘內會造成嚴重堆積,另外在重啟過程中可能出現資源搶占造成實時任務無法及時恢復,因此需要實時分流任務具備快速恢復的能力。主要從以下幾點出發,增加恢復速度
- Checkpoint快速恢復
- 維表Join支持FailOver
- Yarn調度資源搶占解決
5.2.1 Checkpoint快速恢復
- Regional Checkpoint
北極星分流場景下Flink作業的并行度非常大,非常容易因為環境波動等原因導致部分subtask的checkpoint失敗。默認配置下,這會導致作業的checkpoint失敗,從而導致在作業恢復時需要重放大量的數據,造成不必要的資源浪費。通過引入regional checkpoint,可以做到在部分subtask的checkpoint失敗時,作業的checkpoint仍然可以成功。配合Flink社區提供的region failover的功能,可以極大地提高作業在部分subtask失敗時從checkpoint恢復的速度。
配置參數:execution.checkpointing.regional.enabled=true,execution.checkpointing.regional.max-tolerable-consecutive-failures-or-expiratinotallow=3,execution.checkpointing.regional.max-tolerable-failure-or-expiration-ratio=1,execution.checkpointing.tolerable-failed-checkpoints=3
5.2.2 維表Join支持FailOver
- ShutDown Hook Failover
在北極星分流場景下,使用 HDFS維表 Left Join。HDFS維表加載過程是定期將 HDFS文件反序列化并以 KV形式放入內存和 RocksDB中,緩存級別為 TM級。一旦出現 slot通信失敗將 shutdown整個 TM,緩存需重新加載。通過 JDK1.0提供的 ShutDown Hook在 slot失敗時單獨清理 Slot對象,保留 TM級別緩存,支持 Region FailOver在 slot單獨恢復時提高恢復速度。
5.2.3 Yarn調度資源搶占
- Session提交
在集群資源緊張的情況下,任務重啟時會發生由于資源被Pending任務搶占而無法啟動的問題。這會導致高優任務的資源需求無法滿足,時常需要人工介入處理。通過Session提交方式,在任務漂移時保留占用的資源不釋放,保證任務 FailOver成功。
5.3 分流任務數據質量保證
在任務頻繁重啟過程中,容易觸發各功能點的Corner Case導致數據質量異常。在考慮功能的健壯性基礎上,結合Flink兩階段提交能力保證數據處理Exactly Once。ODS數據在分流任務處理過程中主要經過Flink File Source以及Multi Hive Sink,在Flink connectors實現過程中結合Checkpoint實現數據處理 Exactly Once。另外在維表Join處理上,也可能發生維表Join異常導致DQC異常。

5.3.1 File Source兩階段提交
- 文件處理Exactly Once
通過掃描ODS表目錄并根據目錄下索引文件得到可見文件,基于分區寫入文件修改時間單調遞增的特性,Checkpoint記錄已轉換Splits的文件最大Modify Time。任務重啟后掃描的文件過濾出小于記錄的modify time即可保證文件處理精確一次。
- Split分發Exactly Once
文件在轉換Split之后,將會由Monitor統一下發至Reader算子,在分發過程中,Monitor負責記錄未發送的split,Reader算子記錄已接收的split,保證split分發不丟不重。
- Split轉換RowData Exactly Once
Split在轉換為RowData過程中,原生的 HiveTableFileInput不支持Checkpoint,沒有記錄split,任務在重啟時會導致split重復讀取導致數據重復。通過改造在checkpoint時記錄當前每個Split處理的SplitNumber,在重啟恢復Reopen Split時從上次記錄的Split Number處開始消費,保證Split轉換RowData時精確一次。
5.3.2 維表加載數據準確性
- 維表加載降級
由于維表加載需要訪問外部系統,容易產生異常導致維表加載失敗。由于業務存在根據維表加載的數據進行where過濾,一旦維表數據異常則會發生數據丟失。因此在維表加載數據異常時主動降級至上一個分區,雖然可能會導致部分新的數據join miss,但在最大程度上降低數據丟失風險。
- 文件鎖保證原子性
內部在使用維表join時,選擇了直接通過加載hdfs目錄的方式加載數據。在沒有使用分區通知機制的情況下,加載是否完成只能通過Spark是否寫完作為最終標志,由于是天級別目錄小時級更新場景,因此對于檢查SUCCESS文件的方法并不具備原子性。通過加文件鎖的方式,即判斷加載數據前后的文件時間是否發生變更保證HDFS維表加載原子性。
5.3.3 Multi Hive Sink數據質量保證
- 文件兩階段處理
這里使用社區版本,即在寫出文件時為隱藏文件,執行 Checkpoint時Close文件,在下一次checkpoint成功之后notify執行rename操作保證數據一致性。
- 多表多級分區提前調度問題
在內部分流場景下,為了減小下游數據攝取數量,由二級分區分流成為四級分區,四級分區在社區版本分區提交過程中,由于調度是小時級別,則需要判斷該分區下所有四級分區全部ready之后才能通知下游調度,僅通過watermark無法滿足該要求。我們通過在狀態中記錄Flink Bucket的Open和Close狀態,來判斷當前小時分區下所有的四級分區是否完全結束。
- 集成archer新增Archer commit policy
傳統實時調度離線的方法通過打時間差方式進行,需要平臺側通過定時調度拉起下游,為了保證不被提前調起,還要加分區是否創建兜底保障,調度任務拉起與上游分區通知存在gap。通過archer commit主動通知方式可以解決這一gap帶來的調度不準確的問題,因此通過集成archer在hive commit算子內增加archer commit policy,對分流表下游調度基于主動通知的模式拉起,保障數據質量和調度準確性。

6、實時增量計算落地效果
實時增量計算在北極星分流場景落地后,相比原有離線分流方案在各方面有顯著提升。
資源使用降低
在資源使用上整體資消耗降低約20%,峰值資源消耗降低約46%。
數據時效性提升
小時級分區歸檔時間平均提升20%,在 ODS-DWD ETL平均2TB每小時數據場景下,小時級同步99線保持30min內,50線在17min內。
分區可擴展性增強
支持在同步資源不變條件下繼續拆分多表多級分區。
7、未來展望
在實時數倉流批一體的大背景下,實踐通過 Flink+Hudi方式打造北極星分流流批一體,整合實時離線鏈路降低資源開銷,并且通過 Hudi clustering能力進一步降低讀取數據量,達到查詢加速的效果。
8、參考資料
[1]https://mp.weixin.qq.com/s/PQYylmHBjnnH9pX7-nxvQA
[2]https://mp.weixin.qq.com/s/E23JO7YvzJrocbOIGO5X-Q
[3]https://nightlies.apache.org/flink/flink-docs-release-1.16/docs/dev/table/sourcessinks/
[4]https://mp.weixin.qq.com/s/O0AXF74j6UvjtPQp5JQrTw
[5]??https://mp.weixin.qq.com/s/NawxeiP-_DFpyoekRrzlLQ??
本期作者

朱正軍
嗶哩嗶哩資深開發工程師