服務發現:CP or AP?
1 服務發現的意義
為高可用,生產環境中服務提供方都以集群對外提供服務,集群里這些IP隨時可能變化,也需要用一本“通信錄”及時獲取對應服務節點,這獲取過程即“服務發現”。
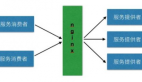
對服務調用方和服務提供方,其契約就是接口,相當于“通信錄”中的姓名,服務節點就是提供該契約的一個具體實例。服務IP集合作為“通信錄”中的地址,從而可通過接口獲取服務IP的集合來完成服務的發現。即PRC框架的服務發現:

RPC服務發現原理圖
1.1 服務注冊
在服務提供方啟動時,將對外暴露的接口注冊到注冊中心,注冊中心將這個服務節點的IP和接口保存
1.2 服務訂閱
在服務調用方啟動時,去注冊中心查找并訂閱服務提供方的IP,然后緩存到本地,并用于后續的遠程調用
2 為何不使用DNS?
服務發現的本質,就是完成接口跟服務提供者IP的映射。能否把服務提供者IP統一換成一個域名,利用DNS實現?
2.1 DNS流程

DNS查詢流程
所有服務提供者節點都配置在同一域名下,調用方是可通過DNS拿到隨機的一個服務提供者的IP,并建立長連接,但業界為何不用這方案?
異常考慮
- ? 若該IP端口下線了,服務調用者能否及時摘除服務節點
- ? 若在之前已上線一部分服務節點,突然對這服務擴容,新上線的服務節點能否及時接收到流量
都不能。因為為提升性能和減少DNS服務壓力,DNS采取多級緩存,緩存時間較長,特別是JVM的默認緩存是永久有效,所以服務調用者不能及時感知到服務節點變化。
是否可加一個負載均衡設備?將域名綁定到這臺負載均衡設備,通過DNS拿到負載均衡的IP。服務調用時,服務調用方就能直接跟VIP建立連接,然后由VIP機器完成TCP轉發:

VIP方案
這是能解決DNS遇到的一些問題,但RPC里不是很合適:
- ? 搭建負載均衡設備或TCP/IP四層代理,需額外成本
- ? 請求流量都經過負載均衡設備,多經過一次網絡傳輸,浪費性能
- ? 負載均衡添加節點和摘除節點,一般要手動添加,當大批量擴容和下線時,會有大量人工操作和生效延遲
- ? 服務治理時,需更靈活的負載均衡策略,目前負載均衡設備的算法不滿足靈活需求
由此可見,DNS或者VIP方案雖然可以充當服務發現的角色,但在RPC場景里面直接用還是很難的。
3 基于zk的服務發現(CP)
服務發現的本質:完成接口跟服務提供者IP的映射。就是一種命名服務,還希望注冊中心完成實時變更推送,zk、etcd都能實現。
搭建一個zk集群作為注冊中心集群,服務注冊時,只需服務節點向zk寫入注冊信息,利用zk的Watcher機制完成服務訂閱與服務下發功能。
整體流程

基于ZooKeeper服務發現結構圖
1. 服務平臺管理端先在zk創建一個服務根路徑,可根據接口名命名(如:/service/com.javaedge.xxService),在這路徑再創建服務提供方目錄與服務調用方目錄(如:provider、consumer),分別存儲服務提供方、服務調用方的節點信息
2. 當服務提供方發起注冊時,會在服務提供方目錄中創建一個臨時節點,節點中存儲該服務提供方的注冊信息
3. 當服務調用方發起訂閱時,則在服務調用方目錄中創建一個臨時節點,節點中存儲該服務調用方的信息,同時服務調用方watch該服務的服務提供方目錄(/service/com.demo.xxService/provider)中所有的服務節點數據。
4. 當服務提供方目錄下有節點數據發生變更時,zk通知給發起訂閱的服務調用方
zk缺陷
早期RPC框架服務發現就是基于zk實現,但后續團隊微服務化程度越來越高,zk集群整體壓力越來越高,尤其在集中上線時越發明顯。“集中爆發”是在一次大規模上線時,當時有超大批量服務節點在同時發起注冊操作,ZooKeeper集群的CPU飆升,導致集群不能工作,也無法立馬將zk集群重新啟動,一直到zk集群恢復后業務才能繼續上線。
根本原因就是zk本身性能問題,當連接到zk的節點數量特多,對zk讀寫特頻繁,且zk存儲目錄達到一定數量,zk將不再穩定,CPU持續升高,最終宕機。宕機后,由于各業務的節點還在持續發送讀寫請求,剛一啟動,zk就因無法承受瞬間的讀寫壓力,馬上宕機。
要重新考慮服務發現方案。
4 消息總線(AP)
zk強一致性,集群的每個節點的數據每次發生更新操作,都通知其它節點同時執行更新。它要求保證每個節點的數據實時完全一致,直接導致集群性能下降。
而RPC框架的服務發現,在服務節點剛上線時,服務調用方可容忍在一段時間后(如幾s后)發現這個新上線的節點。畢竟服務節點剛上線后的幾s內,甚至更長的一段時間內沒有接收到請求流量,對整個服務集群沒有什么影響,可犧牲掉CP(強制一致性),選擇AP(最終一致),換取整個注冊中心集群的性能和穩定性。
是否有一種簡單、高效,并且最終一致的更新機制,代替zk數據強一致的數據更新機制?最終一致性,可考慮消息總線機制。注冊數據可全量緩存在每個注冊中心的內存,通過消息總線來同步數據。當有一個注冊中心節點接收到服務節點注冊時,會產生一個消息推送給消息總線,再通過消息總線通知給其它注冊中心節點更新數據并進行服務下發,從而達到注冊中心間數據最終一致性。
4.1 總體流程

流程圖
? 服務上線,注冊中心節點收到注冊請求,服務列表數據變化,生成一個消息,推送給消息總線,每個消息都有整體遞增的版本
? 消息總線主動推送消息到各注冊中心,同時注冊中心定時拉取消息。對獲取到消息的,在消息回放模塊里面回放,只接受大于本地版本號的消息,小于本地版本號的消息直接丟棄,實現最終一致性
? 消費者訂閱可從注冊中心內存拿到指定接口的全部服務實例,并緩存到消費者的內存
? 采用推拉模式,消費者可及時拿到服務實例增量變化情況,并和內存中的緩存數據進行合并。
為性能,這里采用兩級緩存,注冊中心和消費者的內存緩存,通過異步推拉模式確保最終一致性。
服務調用方拿到的服務節點不是最新的,所以目標節點存在已下線或不提供指定接口服務的情況,這時咋辦?這問題放到RPC框架里處理,在服務調用方發送請求到目標節點后,目標節點會進行合法性驗證,若指定接口服務不存在或正在下線,則拒絕該請求。服務調用方收到拒絕異常后,會安全重試到其它節點。
通過消息總線,完成注冊中心集群間數據變更的通知,保證數據最終一致性,并能及時觸發注冊中心的服務下發。服務發現的特性是允許我們在設計超大規模集群服務發現系統的時候,舍棄強一致性,更多考慮系統健壯性。最終一致性才是分布式系統設計更常用策略。
5 總結
通常可使用zk、etcd或分布式緩存(如Hazelcast)解決事件通知問題,但當集群達到一定規模之后,依賴的ZooKeeper集群、etcd集群可能就不穩定,無法滿足需求。
在超大規模的服務集群下,注冊中心所面臨的挑戰就是超大批量服務節點同時上下線,注冊中心集群接受到大量服務變更請求,集群間各節點間需要同步大量服務節點數據,導致:
? 注冊中心負載過高
? 各節點數據不一致
? 服務下發不及時或下發錯誤的服務節點列表
RPC框架依賴的注冊中心的服務數據的一致性其實并不需要滿足CP,只要滿足AP即可。我們就是采用“消息總線”的通知機制,來保證注冊中心數據的最終一致性,來解決這些問題的。
如服務節點數據的推送采用增量更新的方式,這種方式提高了注冊中心“服務下發”的效率,而這種方式,還可用于如統一配置中心,用此方式可以提升統一配置中心下發配置的效率。
6 FAQ
某大廠中間件的用戶平臺,服務掛了,在注冊中心上還得手動刪除死亡的節點,若是zk,服務沒了,就代表會話也沒了,臨時節點應該會被通知到把?為何還要手動刪除?
臨時節點是需要等到超時時間之后才刪除,不夠實時。
如果要能切換流量,要服務端配置權重負載均衡策略,這樣服務器端即可通過調整權重安排流量。
服務消費者都是從注冊中心拉取服務提供者的地址信息,所以要切走某些服務提供者數據,只需要將注冊中心這些實例的地址信息刪除(其實下線應用實例,實際也是去刪除注冊中心地址信息),然后注冊中心反向通知消費者,消費者受到拉取最新提供者地址信息就沒有這些實例了。
通過服務發現來摘除流量是最常見的手段,還可以上下線狀態、權重等方式。
現有開源注冊中心是不是還沒有消息總線這種實現方式?消息總線有沒有開源實現?
現成MQ也可充當消息總線。
消息總棧類似一個隊列,隊列表示是遞增的數字,注冊中心集群的任何一個節點接收到注冊請求,都會把服務提供者信息發給消息總棧,消息總棧會像隊列以先進先出的原則推送消息給所有注冊中心集群節點,集群節點接收到消息后會比較自己內存中的當前版本,保存版本大的,這種方式有很強的實效性,注冊中心集群也可以從消息總棧拉取消息,確保數據AP,個人理解這是為了防止消息未接收到導致個別節點數據不準確,因為服務提供者可以向任意一個節點發送注冊請求,從而降低了單個注冊中心的壓力,而注冊和注冊中心同步是異步的,也解決了集中注冊的壓力,在Zookeeper中,因為Zookeeper注冊集群的強一致性,導致必須所有節點執行完一次同步,才能執行新的同步,這樣導致注冊處理性能降低,從而高I/O操作宕機。
當集中注冊時,消息總棧下發通知給注冊中心集群節點,對于單個節點也會不停的收到更新通知,這里也存在高I/O問題,會不會有宕機?event bus可以改造成主從模式保證高可用。
AP實現中“兩級緩存,注冊中心和消費者的內存緩存,通過異步推拉模式來確保最終一致性的具體實現?
推主要實現callback,拉的動作在客戶端。
消息總線策略怎么保證消息總線全局版本遞增?最簡單的用時間戳。
消息總線構建ap 型注冊中心,不是很理解。是多個注冊中心獨立提供讀寫,他們之間通過消息隊列做數據同步?那么一致性感覺不好保證,比如服務a 先注冊,再反注冊,但是分別發到兩個注冊中心節點,最終同步可能是亂序的哇?一般不會出現這種情況,只有連接斷開后,那需要重新注冊。
消息總線的另一個應用case:配置中心。