













我們一起聊聊Hdfs Disk Balancer 磁盤均衡器
1、背景
在我們的hadoop集群運行一段過程中,由于多種原因,數據在DataNade的磁盤之間的分布可能是不均勻。比如: 我們剛剛給某個DataNode新增加了一塊磁盤或者集群上存在大批量的write & deltete操作等燈。那么有沒有一種工具,能夠使單個DataNode中的多個磁盤的數據均衡呢?借助Hadoop提供的Diskbalancer命令行工具可以實現。
2、hdfs balancer和 hdfs disk balancer有何不同?
hdfs balancer:是為了集群中DataNode的數據均衡,即針對多個DataNode的。
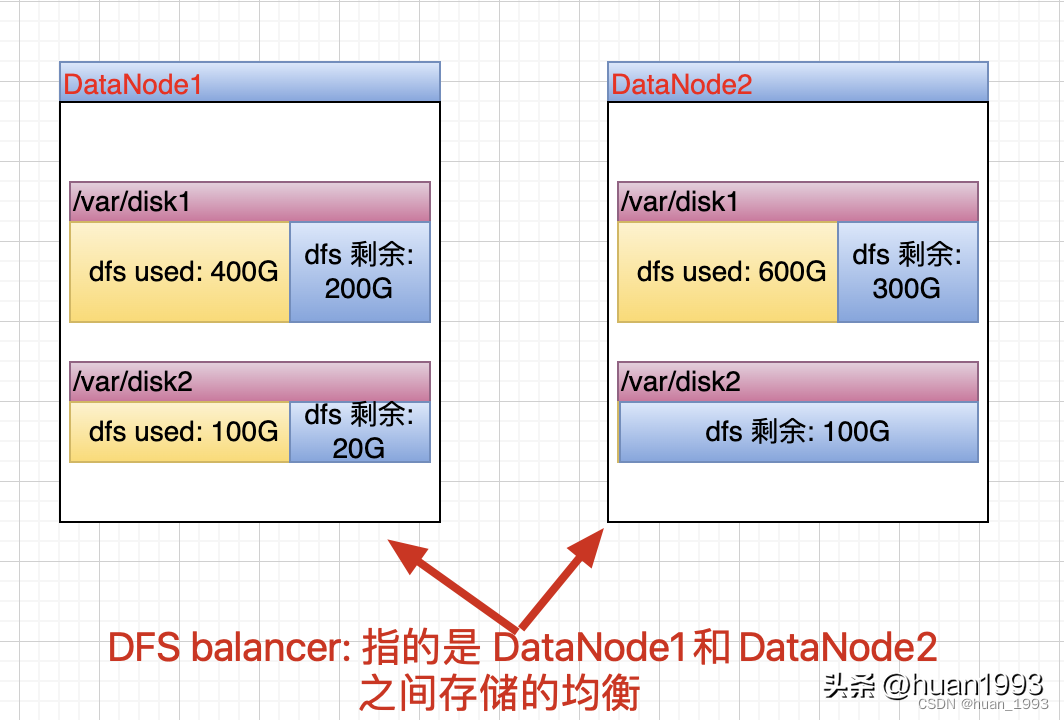
hdfs balancer
hdfs disk balancer:是為了使單臺DataNode中的多個磁盤中的數據均衡。
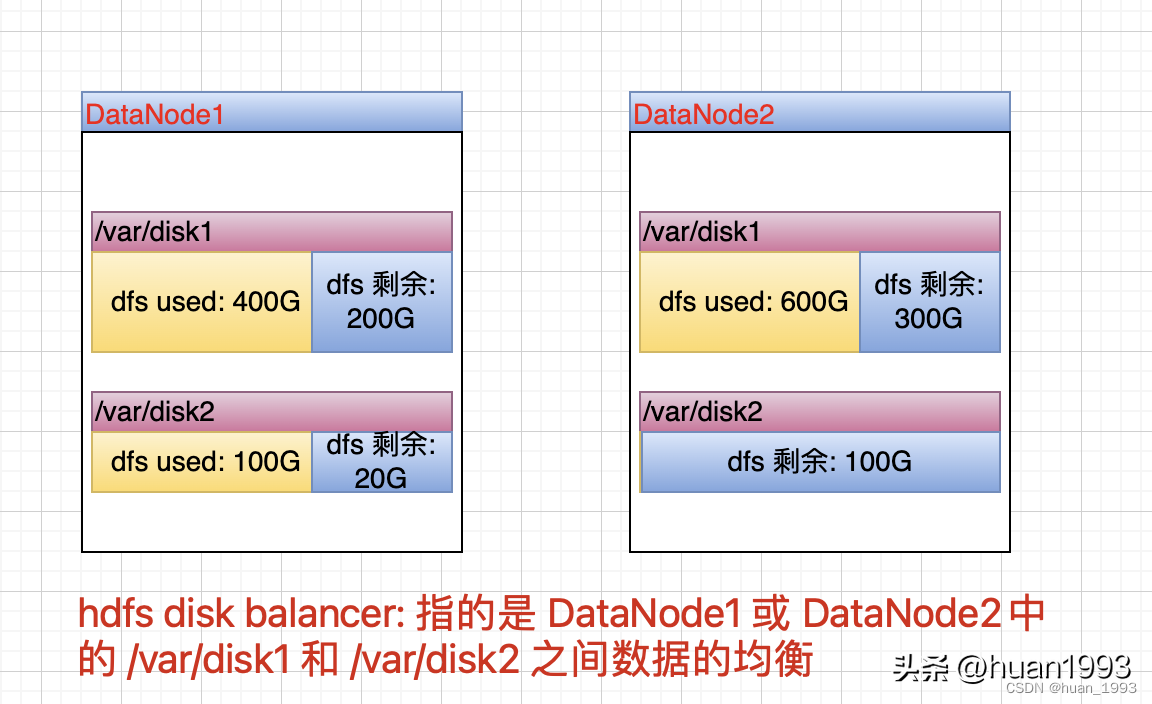
hdfs disk balancer
注意: 目前DiskBalancer不支持跨存儲介質(SSD、DISK等)的數據轉移,所以磁盤的均衡都是要求在一個storageType下的。因為hdfs中存在異構存儲。
3、操作
3.1 生成計劃
-plan:后面接的是主機名。-out:指定計劃文件的輸出位置。

生成計劃
3.2 執行計劃

執行計劃
3.3 查詢計劃
-query 后面跟的是 主機名

查詢計劃
3.4 取消計劃

取消計劃
4、和disk balancer相關的配置
配置 | 描述 |
dfs.disk.balancer.enabled | 此參數控制是否為集群啟用diskbalancer。如果未啟用,任何執行命令都將被DataNode拒絕。默認值為true。 |
dfs.disk.balancer.max.disk.throughputInMBperSec | 這控制了diskbalancer在復制數據時消耗的最大磁盤帶寬。如果指定了10MB之類的值,則diskbalancer平均只會復制10MB/S。默認值為10MB/S。 |
dfs.disk.balancer.max.disk.errors | 設置能夠容忍的在指定的移動過程中出現的最大錯誤次數,超過此閾值則失敗。例如,如果一個計劃有3對磁盤要在其中復制,并且第一個磁盤集遇到超過5個錯誤,那么我們放棄第一個副本并啟動計劃中的第二個副本。最大錯誤的默認值設置為5。 |
dfs.disk.balancer.block.tolerance.percent | 設置磁盤之間進行數據均衡操作時,各個磁盤的數據存儲量與理想狀態之間的差異閾值。取值范圍[1-100],默認為10。例如,各個磁盤的理想數據存儲量為100 GB,此參數設置為10。那么,當目標磁盤的數據存儲量達到90 GB時,則認為該磁盤的存儲狀態就已經達到預期。 |
dfs.disk.balancer.plan.threshold.percent | 設置在磁盤數據均衡中可容忍的兩磁盤之間的數據密度域值差,取值范圍[1-100],默認為10。如果任意兩個磁盤數據密度差值的絕對值超過了閾值,則說明需要對該的磁盤進行數據均衡。例如,如果一個2盤節點上的總數據為100 GB,那么磁盤均衡器計算每個磁盤上的期望值為50 GB。如果容差為10%,則單個磁盤上的數據需要大于60 GB(50 GB + 10%容差值),DiskBalancer才能開始工作。 |
dfs.disk.balancer.plan.valid.interval | 磁盤平衡器計劃有效的最大時間。支持以下后綴(不區分大小寫):ms(milis)、s(sec)、m(min)、h(h)、d(day)以指定時間(例如2s、2m、1h等)。如果未指定后綴,則假定為毫秒。默認值為1d |
5、額外知識點
5.1 新的block存儲到那個磁盤(卷)中
當數據寫入新的block時,DataNode會根據策略選擇不同的磁盤來存儲。
循環策略: 默認策略,將新的塊均勻的分布在可用的磁盤上,可能造成數據傾斜。
可用空間策略: 選擇更多可用空間(按百分比)的磁盤。可能造成在某段時間內,某個磁盤的IO壓力變大。
5.2 磁盤數據密度度量標準

磁盤數據密度度量標準
上圖來自https://www.bilibili.com/video/BV11N411d7Zh/?p=81
6、參考文檔
- ??https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/HDFSDiskbalancer.html???
- https://help.aliyun.com/document_detail/467585.html 3、https://www.bilibili.com/video/BV11N411d7Zh/?p=81?





























