













處理缺失值的三個(gè)層級(jí)的方法總結(jié)
缺失值
缺失值是現(xiàn)實(shí)數(shù)據(jù)集中的常見(jiàn)問(wèn)題,處理缺失值是數(shù)據(jù)預(yù)處理的關(guān)鍵步驟。缺失值可能由于各種原因而發(fā)生,例如數(shù)據(jù)的結(jié)構(gòu)和質(zhì)量、數(shù)據(jù)輸入錯(cuò)誤、傳輸過(guò)程中的數(shù)據(jù)丟失或不完整的數(shù)據(jù)收集。這些缺失的值可能會(huì)影響機(jī)器學(xué)習(xí)模型的準(zhǔn)確性和可靠性,因?yàn)樗鼈兛赡軙?huì)引入偏差并扭曲結(jié)果,有些模型甚至在在缺少值的情況下根本無(wú)法工作。所以在構(gòu)建模型之前,適當(dāng)?shù)靥幚砣笔е凳潜匾摹?/p>

本文將展示如何使用三種不同級(jí)別的方法處理這些缺失值:
- 初級(jí):刪除,均值/中值插補(bǔ),使用領(lǐng)域知識(shí)進(jìn)行估計(jì)
- 中級(jí):回歸插補(bǔ), K-Nearest neighbors (KNN) 插補(bǔ)
- 高級(jí):鏈?zhǔn)椒匠?MICE)的多元插補(bǔ), MICEforest
檢查缺失的值
首先必須檢查每個(gè)特性中有多少缺失值。作為探索性數(shù)據(jù)分析的一部分,我們可以使用以下代碼來(lái)做到這一點(diǎn):
導(dǎo)入pandas并在數(shù)據(jù)集中讀取它們,對(duì)于下面的示例,我們將使用葡萄酒質(zhì)量數(shù)據(jù)集。
然后可以用下面的代碼行檢查缺失的值。
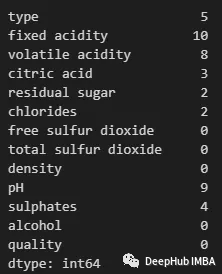
可以使用以下方法查看任何特性中包含缺失值的行:

現(xiàn)在我們可以開(kāi)始處理這些缺失的值了。
初級(jí)方法
最簡(jiǎn)單的方法是刪除行或列(特性)。這通常是在缺失值的百分比非常大或缺失值對(duì)分析或結(jié)果沒(méi)有顯著影響時(shí)進(jìn)行的。
刪除缺少值的行。

使用以下方法刪除列或特性:
通過(guò)刪除行,我們最終得到一個(gè)更短的數(shù)據(jù)集。當(dāng)刪除特征時(shí),我們最終會(huì)得到一個(gè)完整的數(shù)據(jù)集,但會(huì)丟失某些特征。

這兩種方法都最直接的方法,而且都會(huì)導(dǎo)致丟失有價(jià)值的數(shù)據(jù)——所以一般情況下不建議使用。
均值/中值插補(bǔ)
下一個(gè)初級(jí)的方法是用特征的平均值或中值替換缺失的值。在這種情況下不會(huì)丟失特征或行。但是這種方法只能用于數(shù)值特征(如果使用平均值,我們應(yīng)該確保數(shù)據(jù)集沒(méi)有傾斜或包含重要的異常值)。
比如下面用均值來(lái)計(jì)算缺失值:
現(xiàn)在讓我們檢查其中一個(gè)估算值:

如果要用中值,可以使用:

可以看到這里中值和平均值還是有區(qū)別的。
眾數(shù)
與上面的方法一樣,該方法用特征的模式或最常見(jiàn)的值替換缺失的值。這種方法可以用于分類(lèi)特征。
首先,讓我們檢查一下是否有一個(gè)類(lèi)別占主導(dǎo)地位。我們可以通過(guò)value_counts方法來(lái)實(shí)現(xiàn):
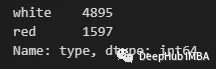
可以看到有一個(gè)“白色”數(shù)量最多。因此可以用下面的方式進(jìn)行填充:
Scikit-Learn的SimpleImputer類(lèi)
也可以使用Scikit-learn的SimpleImputer類(lèi)執(zhí)行平均值、中值和眾數(shù)的插補(bǔ)。將策略設(shè)置為“mean”,“median”或“most_frequency”即可
我們也可以將策略設(shè)置為' constant ',并指定' fill_value '來(lái)填充一個(gè)常量值。
均值/中位數(shù)/眾數(shù)的優(yōu)點(diǎn):
- 簡(jiǎn)單和快速實(shí)現(xiàn)
- 它保留了樣本量,并降低了下游分析(如機(jī)器學(xué)習(xí)模型)的偏差風(fēng)險(xiǎn)。
- 與更復(fù)雜的方法相比,它的計(jì)算成本更低。
缺點(diǎn):
- 沒(méi)有說(shuō)明數(shù)據(jù)的可變性或分布,可能會(huì)導(dǎo)致估算值不能代表真實(shí)值。
- 可能會(huì)低估或高估缺失值,特別是在具有極端值或異常值的數(shù)據(jù)集中。
- 減少方差和人為夸大相關(guān)系數(shù)在估算數(shù)據(jù)集。
- 它假設(shè)缺失的值是完全隨機(jī)缺失(MCAR),這可能并不總是這樣
使用領(lǐng)域知識(shí)進(jìn)行評(píng)估
處理缺失數(shù)據(jù)的另一種可能方法是使用基于領(lǐng)域知識(shí)或業(yè)務(wù)規(guī)則的估計(jì)來(lái)替換缺失的值。可以通過(guò)咨詢相關(guān)領(lǐng)域的專家,讓他們提供專業(yè)的見(jiàn)解,這樣能夠估算出合理和可信的缺失值。
但是這種方法并不一定在現(xiàn)實(shí)中就能夠很好的實(shí)施,因?yàn)槲覀冃枰獙I(yè)的人士來(lái)確保它產(chǎn)生準(zhǔn)確和可靠的估算,但是這樣的領(lǐng)域?qū)<也⒉欢唷K晕覀冞@里把它歸在初級(jí)方法中。
中級(jí)方法
還有一些稍微高級(jí)一些的技術(shù)來(lái)填充那些缺失的值,我們將使用預(yù)測(cè)模型來(lái)解決問(wèn)題。但在此之前需要更好地理解缺失值的性質(zhì)。
缺失值的類(lèi)型
在我們繼續(xù)使用更高級(jí)的技術(shù)之前,需要考慮一下在數(shù)據(jù)集中可能遇到的缺失類(lèi)型。數(shù)據(jù)集中有不同類(lèi)型的缺失,了解缺失類(lèi)型有助于確定合適的方法。以下是一些常見(jiàn)的類(lèi)型:
完全隨機(jī)缺失( Missing Completely at Random):在這種類(lèi)型中,缺失的值是完全隨機(jī)的,這意味著一個(gè)值缺失的概率不依賴于任何觀察到的或未觀察到的變量。例如,如果一個(gè)受訪者在調(diào)查中不小心跳過(guò)了一個(gè)問(wèn)題,這就是MCAR。
隨機(jī)丟失(Missing at Random):在這種類(lèi)型中,一個(gè)值缺失的概率取決于觀察到的變量,而不是值本身。例如,如果調(diào)查對(duì)象不太可能回答敏感問(wèn)題,但不回答問(wèn)題的傾向取決于可觀察到的變量(如年齡、性別和教育),那么這就是MAR。
非隨機(jī)丟失(Missing Not at Random):在這種類(lèi)型中,一個(gè)值缺失的概率取決于未觀察到的變量,包括缺失值值本身。例如,如果抑郁程度較高的個(gè)體不太可能報(bào)告他們的抑郁水平,而不報(bào)告的傾向在數(shù)據(jù)中是無(wú)法觀察到的,那么這就是MNAR。
回歸插補(bǔ)
我們將使用一個(gè)回歸模型來(lái)對(duì)那些缺失的值進(jìn)行有根據(jù)的猜測(cè),通過(guò)分析數(shù)據(jù)集中的其他特征,并使用它們的相關(guān)性來(lái)填補(bǔ)。
在處理遵循某種模式(MAR或MCAR)的缺失數(shù)據(jù)時(shí),回歸插補(bǔ)特別有用。因?yàn)楫?dāng)特征之間存在很強(qiáng)的相關(guān)性時(shí),這種方法很有效。
我們這里將創(chuàng)建一個(gè)不包含分類(lèi)特征的數(shù)據(jù)版本。然后以為每一列的缺失值擬合線性回歸模型。這里就需要使用Scikit-learn的線性回歸模塊。

回歸插補(bǔ)的優(yōu)點(diǎn):
- 可以處理大量缺失值。
- 可以保留數(shù)據(jù)集的統(tǒng)計(jì)屬性,例如均值、方差和相關(guān)系數(shù)。
- 可以通過(guò)減少偏差和增加樣本量來(lái)提高下游分析(例如機(jī)器學(xué)習(xí)模型)的準(zhǔn)確性。
回歸插補(bǔ)的缺點(diǎn):
- 它假設(shè)缺失變量和觀察到的變量之間存在線性關(guān)系。
- 如果缺失值不是隨機(jī)缺失 (MAR) 或完全隨機(jī)缺失 (MCAR),則可能會(huì)引入偏差。
- 可能不適用于分類(lèi)或有序變量。
- 在計(jì)算上昂貴且耗時(shí),尤其是對(duì)于大型數(shù)據(jù)集。
(KNN) 插補(bǔ)
另一種方法是聚類(lèi)模型,例如K-最近鄰 (KNN) 來(lái)估計(jì)那些缺失值。這與回歸插補(bǔ)類(lèi)似,只是使用不同的算法來(lái)預(yù)測(cè)缺失值。

這里我們就要介紹一個(gè)包fancyimpute,它包含了各種插補(bǔ)方法:
使用的方法如下:
KNN 插補(bǔ)的優(yōu)點(diǎn):
- 可以捕獲變量之間復(fù)雜的非線性關(guān)系。
- 不對(duì)數(shù)據(jù)的分布或變量之間的相關(guān)性做出假設(shè)。
- 比簡(jiǎn)單的插補(bǔ)方法(例如均值或中值插補(bǔ))更準(zhǔn)確,尤其是對(duì)于中小型數(shù)據(jù)集。
缺點(diǎn):
- 計(jì)算上可能很昂貴,尤其是對(duì)于大型數(shù)據(jù)集或高維數(shù)據(jù)。
- 可能對(duì)距離度量的選擇和選擇的最近鄰居的數(shù)量敏感,這會(huì)影響準(zhǔn)確性。
- 對(duì)于高度傾斜或稀疏的數(shù)據(jù)表現(xiàn)不佳。
高級(jí)方法
通過(guò)鏈?zhǔn)椒匠?(MICE) 進(jìn)行多元插補(bǔ)
MICE 是一種常用的估算缺失數(shù)據(jù)的方法。它的工作原理是將每個(gè)缺失值替換為一組基于模型的合理值,該模型考慮了數(shù)據(jù)集中變量之間的關(guān)系。
該算法首先根據(jù)其他完整的變量為數(shù)據(jù)集中的每個(gè)變量創(chuàng)建一個(gè)預(yù)測(cè)模型。然后使用相應(yīng)的預(yù)測(cè)模型估算每個(gè)變量的缺失值。這個(gè)過(guò)程重復(fù)多次,每一輪插補(bǔ)都使用前一輪的插補(bǔ)值,就好像它們是真的一樣,直到達(dá)到收斂為止。
然后將多個(gè)估算數(shù)據(jù)集組合起來(lái)創(chuàng)建一個(gè)最終數(shù)據(jù)集,其中包含所有缺失數(shù)據(jù)的估算值。MICE 是一種強(qiáng)大而靈活的方法,可以處理具有許多缺失值和變量之間復(fù)雜關(guān)系的數(shù)據(jù)集。它已成為許多領(lǐng)域(包括社會(huì)科學(xué)、健康研究和環(huán)境科學(xué))中填補(bǔ)缺失數(shù)據(jù)的流行選擇。
fancyimpute包就包含了這個(gè)方法的實(shí)現(xiàn),我們可以直接拿來(lái)使用
這個(gè)實(shí)現(xiàn)沒(méi)法對(duì)分類(lèi)變量進(jìn)行填充,那么對(duì)于分類(lèi)變量怎么辦呢?
MICEforest
MICEforest 是 MICE的變體,它使用 lightGBM 算法來(lái)插補(bǔ)數(shù)據(jù)集中的缺失值,這是一個(gè)很奇特的想法,對(duì)吧。
我們可以使用 miceforest 包來(lái)實(shí)現(xiàn)它
使用也很簡(jiǎn)單:
可以看到,分類(lèi)變量 'type' 的缺失值已經(jīng)被填充了
總結(jié)
我們這里介紹了三個(gè)層級(jí)的缺失值的處理方法,這三種方法的選擇將取決于數(shù)據(jù)集、缺失數(shù)據(jù)的數(shù)量和分析目標(biāo)。也需要仔細(xì)考慮輸入缺失數(shù)據(jù)對(duì)最終結(jié)果的潛在影響。處理缺失數(shù)據(jù)是數(shù)據(jù)分析中的關(guān)鍵步驟,使用合適的填充方法可以幫助我們解鎖隱藏在數(shù)據(jù)中的見(jiàn)解,而從主題專家那里尋求輸入并評(píng)估輸入數(shù)據(jù)的質(zhì)量有助于確保后續(xù)分析的有效性。
最后我們介紹的兩個(gè)python包的地址,有興趣的可以看看:
https://pypi.org/project/fancyimpute/
https://pypi.org/project/miceforest/















