譯者 | 朱先忠?
審校 | 孫淑娟?
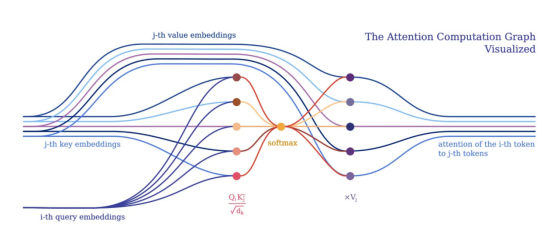
從令牌角度的注意力計(jì)算圖可視化(注意令牌間的關(guān)系)?
在過去幾年中,我們看到了不少基于Transformer的模型的興起(引文1),并在許多領(lǐng)域得到成功的應(yīng)用,如自然語言處理或計(jì)算機(jī)視覺等。在本文中,我們將探索一種簡潔、可解釋和可擴(kuò)展的方式,將深度學(xué)習(xí)模型(特別是Transformer)表達(dá)為混合架構(gòu),即通過將深度學(xué)習(xí)與符號人工智能相結(jié)合。為此,我們將使用一個(gè)名為PyNeuraLogic的基于Python語言的神經(jīng)符號框架中實(shí)現(xiàn)模型設(shè)計(jì)。?
【注意】本文作者也是??PyNeuraLogic框架??的設(shè)計(jì)者之一。
“如果沒有混合架構(gòu)、豐富的先驗(yàn)知識和復(fù)雜的推理技術(shù)這三大要素,我們就無法以充分、自動(dòng)化的方式構(gòu)建豐富的認(rèn)知模型。”(引文2)?
-加里·馬庫斯(新硅谷機(jī)器人創(chuàng)業(yè)公司Robust.AI首席執(zhí)行官兼創(chuàng)始人)?
將符號表示與深度學(xué)習(xí)相結(jié)合,填補(bǔ)了當(dāng)前深度學(xué)習(xí)模型中的空白,例如開箱即用的可解釋性或缺少推理技術(shù)等。也許,提高參數(shù)的數(shù)量并不是實(shí)現(xiàn)這些理想結(jié)果的最佳方法,就像增加相機(jī)百萬像素的數(shù)量不一定會產(chǎn)生更好的照片一樣。?
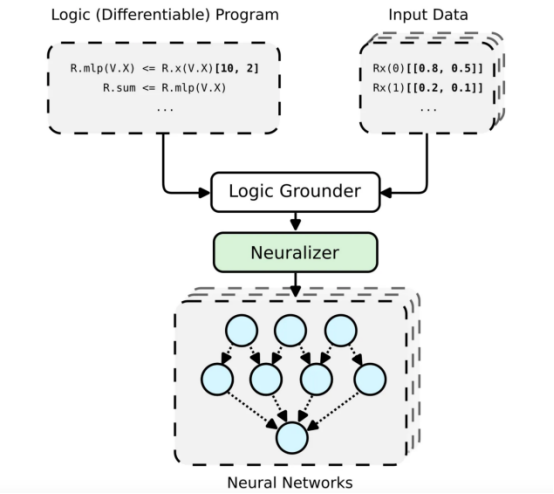
PyNeuraLogic框架工作流總體架構(gòu)?
神經(jīng)符號概念的高級可視化提升關(guān)系神經(jīng)網(wǎng)絡(luò)(LRNN,見引文3),這可以借助(Py)NeuraLogic實(shí)現(xiàn)。這里我們展示了一個(gè)簡單的模板(邏輯程序)——通過一個(gè)線性層后面跟著一個(gè)求和聚合。對于每個(gè)(輸入)樣本,構(gòu)建一個(gè)獨(dú)特的神經(jīng)網(wǎng)絡(luò)。?
PyNeuraLogic框架是基于特別設(shè)計(jì)的邏輯編程(邏輯程序中包含可微參數(shù))實(shí)現(xiàn)的。該框架非常適合于較小的結(jié)構(gòu)化數(shù)據(jù)(如分子)和復(fù)雜模型(如Transformers和圖形神經(jīng)網(wǎng)絡(luò))。但是,另一方面需要注意的是,PyNeuraLogic不是非關(guān)系型和大張量數(shù)據(jù)的最佳選擇。?
框架的關(guān)鍵組成部分是一個(gè)可微邏輯程序,我們稱之為模板。模板由以抽象方式定義神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)的邏輯規(guī)則組成,我們可以將模板視為模型架構(gòu)的藍(lán)圖。然后,將模板應(yīng)用于每個(gè)輸入數(shù)據(jù)實(shí)例以產(chǎn)生(通過接地和神經(jīng)化)輸入樣本特有的神經(jīng)網(wǎng)絡(luò)。這個(gè)過程與其他具有預(yù)定義架構(gòu)的框架完全不同,預(yù)定義架構(gòu)無法根據(jù)不同的輸入樣本進(jìn)行調(diào)整。為了更詳細(xì)地介紹該框架,您可以參考另一篇關(guān)于從圖形神經(jīng)網(wǎng)絡(luò)的角度關(guān)注??PyNeuralogic的文章??。
符號式Transformer?
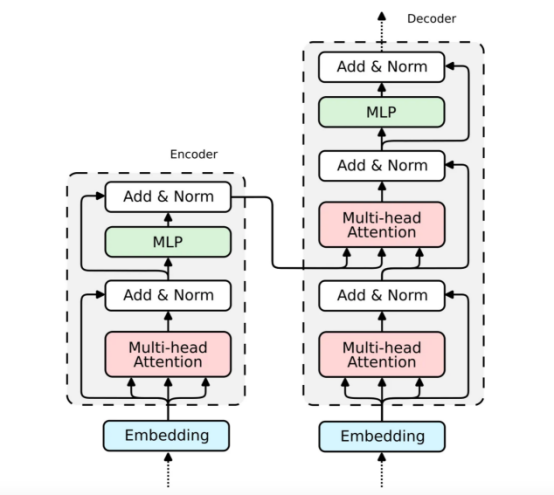
經(jīng)典Transformer模型示意圖?
Transformer架構(gòu)由兩個(gè)塊組成——編碼器(左)和解碼器(右)。兩個(gè)塊共享相似之處——解碼器是一個(gè)擴(kuò)展編碼器。因此,在本文中我們將只關(guān)注編碼器的解析,因?yàn)榻獯a器的實(shí)現(xiàn)是類似的。?
我們通常傾向于將深度學(xué)習(xí)模型實(shí)現(xiàn)為對批量輸入到一個(gè)大張量中的輸入令牌的張量操作。這是有意義的,因?yàn)樯疃葘W(xué)習(xí)框架和硬件(例如GPU)通常被優(yōu)化為處理更大的張量,而不是不同形狀和大小的多個(gè)張量。Transformers也不例外,通常將單個(gè)令牌向量表示批量化為一個(gè)大矩陣,并將模型表示為這些矩陣上的運(yùn)算。然而,這樣的實(shí)現(xiàn)隱藏了各個(gè)輸入令牌之間的相互關(guān)系,正如Transformer的注意力機(jī)制所展示的那樣。?
注意力機(jī)制?
注意力機(jī)制是所有Transformer模型的核心。具體來說,它的經(jīng)典版本利用了所謂的多頭縮放點(diǎn)積注意力。為了清晰起見,我們不妨借助于一個(gè)頭來將縮放的點(diǎn)積注意力分解成一個(gè)簡單的邏輯程序。?
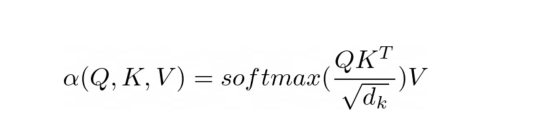
縮放的點(diǎn)積注意力方程?
注意力的目的是決定網(wǎng)絡(luò)應(yīng)該關(guān)注輸入的哪些部分。注意力是通過計(jì)算值V的加權(quán)和來實(shí)現(xiàn)的,其中權(quán)重表示輸入鍵K和查詢Q的兼容性。在該特定版本中,通過查詢Q和鍵K的點(diǎn)積的softmax函數(shù)除以輸入特征向量維度d_k的平方根來計(jì)算權(quán)重。?
在PyNeuraLogic中,我們可以通過上述邏輯規(guī)則充分捕捉注意力機(jī)制。第一個(gè)規(guī)則表示權(quán)重的計(jì)算,它計(jì)算維度的平方根與轉(zhuǎn)置的第j個(gè)關(guān)鍵向量和第i個(gè)查詢向量的乘積。然后我們用softmax聚合給定i和所有可能j的所有結(jié)果。?
然后,第二條規(guī)則計(jì)算該權(quán)重向量與對應(yīng)的第j個(gè)值向量之間的乘積,并對每個(gè)相應(yīng)的第i個(gè)令牌的不同j的結(jié)果求和。?
注意力掩碼?
在訓(xùn)練和評估期間,我們通常會限制輸入令牌可以注意的內(nèi)容。例如,我們希望限制令牌向前看并注意即將出現(xiàn)的單詞。如PyTorch這樣的流行框架是通過掩碼技術(shù)實(shí)現(xiàn)這一點(diǎn)的,即通過將縮放的點(diǎn)積結(jié)果的元素子集設(shè)置為非常低的負(fù)數(shù)。這些數(shù)字強(qiáng)制softmax函數(shù)將零分配為相應(yīng)令牌對的權(quán)重。?
通過我們的符號表示,我們可以通過簡單地添加一個(gè)單體關(guān)系作為約束來實(shí)現(xiàn)這一點(diǎn)。在計(jì)算權(quán)重時(shí),我們將j索引限制為小于或等于i索引。與掩碼方案相反,我們只計(jì)算所需的縮放點(diǎn)積。?
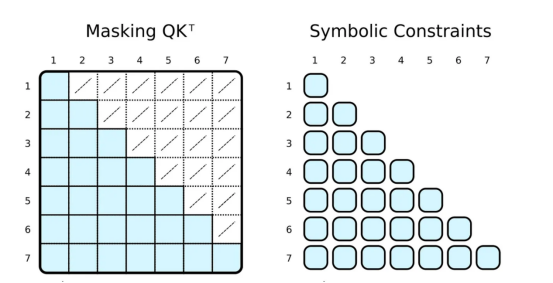
正則張量表示與符號表示中注意力的可視化?
常規(guī)的深度學(xué)習(xí)框架通過掩碼(左側(cè))限制注意力。首先,計(jì)算整個(gè)QK^T矩陣,然后通過覆蓋低值(白色交叉單元格)來屏蔽值,以模擬只注意相關(guān)的令牌(藍(lán)色單元格)。在PyNeuraLogic中,我們通過應(yīng)用符號約束(右側(cè))只計(jì)算所需的標(biāo)量值,因此沒有多余的計(jì)算。這一優(yōu)勢在以下注意力版本中更為顯著。?
更優(yōu)秀的注意力聚合?
當(dāng)然,符號式的“掩碼”可以是完全任意的。我們大多數(shù)人都聽說過基于稀疏Transformer的GPT-3(或其應(yīng)用程序,如ChatGPT,【引文4】)。稀疏Transformer的注意力(跨步版本)可分為兩種類型的注意力頭部:?
- 只關(guān)注前面的n個(gè)令牌(0≤i?j≤n)?
- 僅關(guān)注每n-th個(gè)前面的令牌((i?j)%n=0)?
兩種類型的頭部的實(shí)現(xiàn)同樣只需要微小的修改(例如,對于n=5)。?
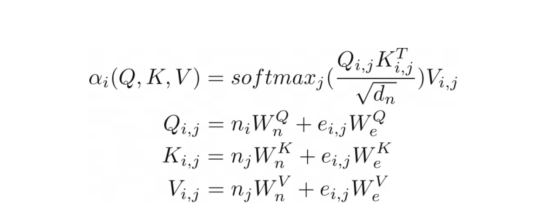
關(guān)系注意力方程?
其實(shí),我們可以更進(jìn)一步將注意力推廣到類似于圖的(關(guān)系)輸入,就像在關(guān)系注意力中一樣。這種類型的注意力作用于圖,其中節(jié)點(diǎn)只關(guān)注其鄰節(jié)點(diǎn)(由邊連接的節(jié)點(diǎn))。然后,查詢Q、鍵K和值V是與節(jié)點(diǎn)向量嵌入相加的邊緣嵌入。?
在我們的示例中,這種注意力與之前顯示的縮放點(diǎn)積注意力幾乎相同。唯一的區(qū)別是添加了額外的術(shù)語來捕捉邊緣。將圖形作為注意力機(jī)制的輸入似乎很自然,考慮到Transformer是一種??圖形神經(jīng)網(wǎng)絡(luò)??,作用于完全連接的圖形(當(dāng)不應(yīng)用掩碼時(shí)),這并不完全令人驚訝。在傳統(tǒng)的張量表示中,這不是那么明顯。
Transformer編碼器?
現(xiàn)在,我們已經(jīng)展示注意力機(jī)制的實(shí)現(xiàn)。其實(shí),構(gòu)建整個(gè)Transformer編碼器塊所缺少的部分也是比較直觀的。?
嵌入?
我們已經(jīng)在關(guān)系注意(Relational Attention)中看到了如何實(shí)現(xiàn)嵌入。對于傳統(tǒng)的Transformer,嵌入都是非常相似的。我們只需將輸入向量投影為三個(gè)嵌入向量——鍵、查詢和值。?
跳過連接、標(biāo)準(zhǔn)化和前饋網(wǎng)絡(luò)?
查詢嵌入通過跳過連接與注意力輸出相加。然后將得到的向量歸一化并傳遞到多層感知器(MLP)中。?
對于MLP,我們將實(shí)現(xiàn)具有兩個(gè)隱藏層的完全連接的神經(jīng)網(wǎng)絡(luò),這可以優(yōu)雅地表示為一個(gè)邏輯規(guī)則。?
最后一個(gè)帶有規(guī)范化的跳過連接與前一個(gè)相同。?
組裝到一起?
至此,我們已經(jīng)構(gòu)建了Transformer編碼器所需的所有部件。解碼器使用相同的組件;因此,它的實(shí)現(xiàn)是類似的。現(xiàn)在,讓我們將上面所有的代碼塊組合成一個(gè)可微的邏輯程序中。該程序可以嵌入到Python腳本內(nèi),并通過使用PyNeuraLogic被編譯成神經(jīng)網(wǎng)絡(luò)。?
結(jié)論?
在本文中,我們分析了Transformer架構(gòu),并演示了它在一個(gè)稱為??PyNeuraLogic???的神經(jīng)符號框架中的實(shí)現(xiàn)。通過這種方法,我們能夠在只需對代碼進(jìn)行微小的更改的情況下實(shí)現(xiàn)各種類型的Transformer,從而向廣大讀者展示了如何快速地轉(zhuǎn)向和開發(fā)新的Transformer架構(gòu)。此外,文章還指出了各種版本的Transformer以及帶有圖形神經(jīng)網(wǎng)絡(luò)(GNN)的Transformer的明顯相似之處。
參考文獻(xiàn)?
[1]: Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A., Kaiser, L., & Polosukhin, I.. (2017). Attention Is All You Need.?
[2]: Marcus, G.. (2020). The Next Decade in AI: Four Steps Towards Robust Artificial Intelligence.?
[3]: Gustav ?ourek, Filip ?elezny, & Ond?ej Ku?elka (2021). Beyond graph neural networks with lifted relational neural networks. Machine Learning, 110(7), 1695–1738.?
[4]: Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D., Wu, J., Winter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radford, A., Sutskever, I., & Amodei, D.. (2020). Language Models are Few-Shot Learners.?
[5]: Child, R., Gray, S., Radford, A., & Sutskever, I.. (2019). Generating Long Sequences with Sparse Transformers.?
- : Diao, C., & Loynd, R.. (2022). Relational Attention: Generalizing Transformers for Graph-Structured Tasks.?
譯者介紹?
朱先忠,51CTO社區(qū)編輯,51CTO專家博客、講師,濰坊一所高校計(jì)算機(jī)教師,自由編程界老兵一枚。?
原文標(biāo)題:??Beyond Transformers with PyNeuraLogic??,作者:Luká? Zahradník