













實(shí)施推薦系統(tǒng)過(guò)程中遇到的坑
引言
推薦系統(tǒng)本身很成熟,但是在落地過(guò)程當(dāng)中,仍然會(huì)有很多困難。通過(guò)經(jīng)歷幾個(gè)大型推薦系統(tǒng)項(xiàng)目,總結(jié)一些經(jīng)驗(yàn),幫助大家避坑。
1、推薦系統(tǒng)的技術(shù)架構(gòu)
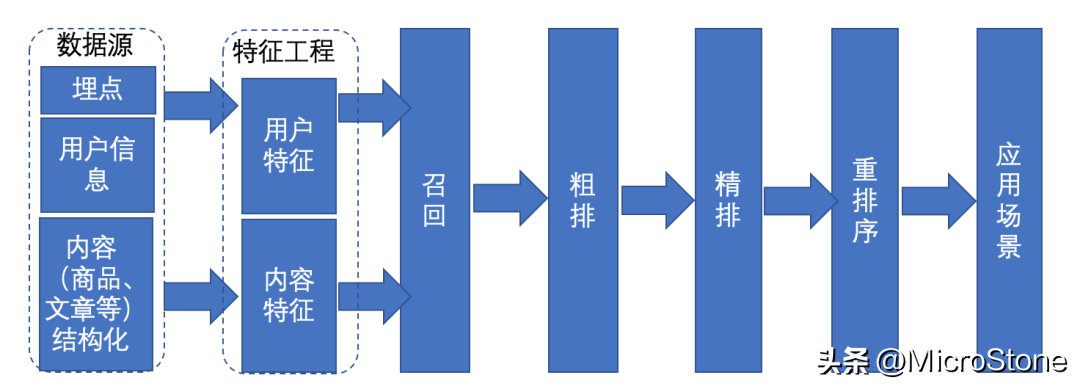
推薦系統(tǒng)模塊一般如上圖所示,先通過(guò)召回模塊,將候選集召回,然后經(jīng)過(guò)粗排、精排、重排等排序方式,將排序靠前的候選集推送給用戶。
2、數(shù)據(jù)源
1. 埋點(diǎn)
個(gè)人觀點(diǎn):
埋點(diǎn)不難,用埋點(diǎn)的數(shù)據(jù)構(gòu)造樣本比較難,特別是實(shí)時(shí)社交比如直播。
理想的樣本:
- 用用戶id把用戶所有行為串起來(lái);
- 可以回溯用戶過(guò)去看直播間的行為,比如評(píng)論、打賞等。
實(shí)際上面臨的困難:
- 埋點(diǎn)的數(shù)據(jù)不準(zhǔn)確,是臟數(shù)據(jù);
- 埋點(diǎn)數(shù)據(jù)排查困難:前端代碼工程復(fù)雜,很容易出問(wèn)題。但是前端的同學(xué)的主要工作也不是數(shù)據(jù)上報(bào),所以數(shù)據(jù)出了問(wèn)題,也不會(huì)實(shí)時(shí)排查,非常容易導(dǎo)致數(shù)據(jù)臟;
- 回溯模型也很復(fù)雜;
- 非常耗資源。
綜上,將用戶對(duì)應(yīng)的行為,拼成樣本,需要花費(fèi)很多精力。
2. 用戶畫(huà)像
包括用戶的基礎(chǔ)畫(huà)像和興趣畫(huà)像。興趣畫(huà)像來(lái)源于兩個(gè)部分:用戶的離線畫(huà)像、用戶的實(shí)時(shí)畫(huà)像。其中,離線畫(huà)像又分為長(zhǎng)期離線畫(huà)像、中期離線畫(huà)像、短期離線畫(huà)像。
3. 內(nèi)容結(jié)構(gòu)化
根據(jù)內(nèi)容信息的不同,內(nèi)容結(jié)構(gòu)化方式不同,比如電商領(lǐng)域,內(nèi)容為商品,商品的結(jié)構(gòu)化信息包括分類、品牌、價(jià)格、規(guī)格等。
個(gè)人****觀點(diǎn):
多模態(tài)要是應(yīng)用到推薦系統(tǒng)來(lái),是個(gè)難點(diǎn)。
- 耗費(fèi)資源:圖片轉(zhuǎn)化為向量,信息量太大,計(jì)算起來(lái)太耗資源。
- 現(xiàn)有的電商算法大多基于行為做描述,而多模態(tài)從內(nèi)容上對(duì)商品做描述,怎么結(jié)合到一起,需要考慮。
所以目前多模態(tài)性價(jià)比不高,討論較多,但是用的較少。
3、特征
特征工程,將結(jié)構(gòu)化的信息轉(zhuǎn)換成模型支持的數(shù)據(jù)格式。
特征選取的優(yōu)劣,會(huì)最終影響到用戶體驗(yàn)。所以特征工程及特征組合的自動(dòng)化,一直是推動(dòng)實(shí)用化推薦系統(tǒng)技術(shù)演進(jìn)最主要的方向之一。
1. 特征內(nèi)容
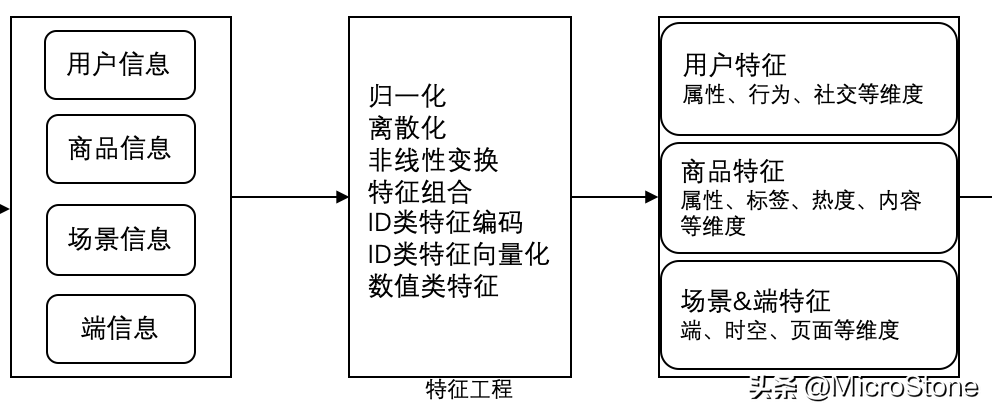
2. 特征生成
個(gè)人觀點(diǎn):
(1)特征生成過(guò)程有什么難點(diǎn)?
- 樣本拼接:在特征生成過(guò)程中,樣本拼接也比較難。
- 一些臟數(shù)據(jù)的識(shí)別。如2.1埋點(diǎn)所說(shuō),埋點(diǎn)的數(shù)據(jù)很容易出問(wèn)題,數(shù)據(jù)清洗和處理非常耗精力。
(2)有什么熱門(mén)的特征提取方式?
用Embedding(可以理解為稠密向量)進(jìn)行特征交叉。
(3)特征工程的趨勢(shì):
- 序列特征:用戶歷史的行為、瀏覽行為、點(diǎn)擊行為,過(guò)去看的直播間、視頻,前提就是比較基礎(chǔ)的特征做好了
- 上下文特征
- Embedding
(4)用在召回的特征提取,和用在排序的特征提取,有什么不同?
① 特征有差別:
- 召回模型大多是雙塔模型,用戶、商品用雙塔模型召回,沒(méi)有交叉特征
- 精排需要交叉特征,比如用戶和物品的交叉、屬性的交叉等
② 樣本有差異:
- 召回面向全量
- 精排面對(duì)的是召回后的候選集
③ 做召回的時(shí)候,要考慮精準(zhǔn)性和效率,精排要用到所有考慮到的特征。所以召回特征是精排特征的子集。
(5)特征抽取:
- 特征需要結(jié)合業(yè)務(wù)場(chǎng)景去抽取特征,每個(gè)場(chǎng)景涉及的都不一樣。要涉及到對(duì)推薦場(chǎng)景有一個(gè)很深的認(rèn)知,才能抽到好的特征。因?yàn)槊總€(gè)場(chǎng)景輸入的維度不同。
- 推薦涉及人貨場(chǎng)三個(gè)方面的特征。有了基礎(chǔ)特征之后,就做特征交叉,人貨場(chǎng)中任意兩三者去做交叉。
- 目前專家所在的大廠某業(yè)務(wù),是一個(gè)大模型,所有的行業(yè)的輸入都是同源的。專家認(rèn)為這是不合理的,所以他認(rèn)為趨勢(shì)是,分行業(yè)去挖掘特征,每個(gè)行業(yè)做小的特征,而不是所有行業(yè)用一套特征。
4、召回
從全量信息集合中觸發(fā)盡可能多的正確結(jié)果,并將結(jié)果返回給排序模塊。
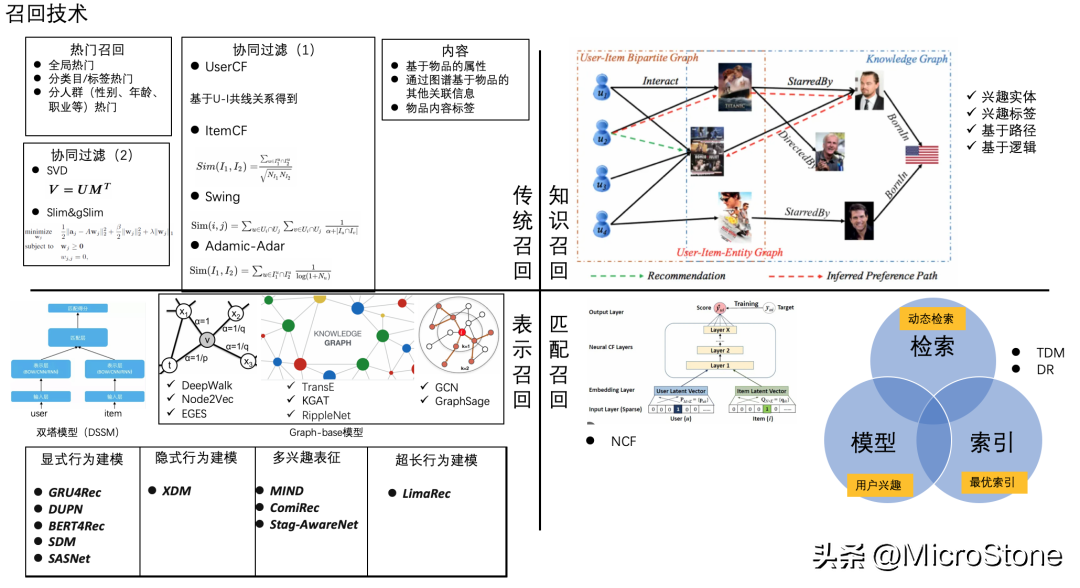
個(gè)人觀點(diǎn):
數(shù)據(jù)決定模型的上限。召回決定了推薦的上限,因?yàn)榫诺暮蜻x集是召回出來(lái)的。
1. 召回的要點(diǎn)
- 處理數(shù)據(jù)量大
- 速度要夠快
- 模型不能太復(fù)雜
- 使用較少特征
2. 召回的難點(diǎn)
- 召回怎么樣和后鏈路做一個(gè)耦合的學(xué)習(xí)。會(huì)有一種情況,排序很適合之前召回算法的商品,排序的非常好,換了召回算法,出一批新的商品,排序算法就不一定排的很好。
- 評(píng)估離線指標(biāo)和線上指標(biāo)的一致性:這是基礎(chǔ)工作,因?yàn)殡x線評(píng)估指標(biāo)漲了,線上不一定也漲了。指標(biāo)主要看Hit rate。
注:Hit rate,在top-K推薦中,HR是一種常用的衡量召回率的指標(biāo).分母是所有的測(cè)試集合,分子是每個(gè)用戶top-K推薦列表中屬于測(cè)試集合的個(gè)數(shù)的總和。
舉例:三個(gè)用戶在測(cè)試集中的商品個(gè)數(shù)分別是10,12,8,模型得到的top-10推薦列表中,分別有6個(gè),5個(gè),4個(gè)在測(cè)試集中,那么此時(shí)HR的值是 (6+5+4)/(10+12+8) = 0.5。
3. 哪一種召回方式用的多?
- 召回的方式特別多,而且每種類型不一樣,差異特別大,不同的召回方式數(shù)據(jù)集差異也比較大。
- 雙塔用的最多,雙塔包含很多種雙塔模型,是成熟期了。
- 圖神經(jīng)網(wǎng)絡(luò)不能用雙塔模型。
- 一般有幾十種召回算法同時(shí)在用,多路一起召回,包括雙塔、ebadding、專家策略、知識(shí)圖譜召回(用的少,其他廠用的多)、圖上的傳統(tǒng)召回、知識(shí)召回、表示召回、匹配召回幾種都用。
- 專家策略效果也可以,只是可能沒(méi)有那么多,而且每一步都有策略,不像雙塔訓(xùn)練好就行。
4. 召回的趨勢(shì)和新算法有哪些?
- 圖神經(jīng)網(wǎng)絡(luò)召回;很有前景的值得探索的方向,信息在圖中的傳播性,所以對(duì)于推薦的冷啟動(dòng)以及數(shù)據(jù)稀疏場(chǎng)景應(yīng)該特別有用。
- 知識(shí)圖譜召回:知識(shí)圖譜有一個(gè)獨(dú)有的優(yōu)勢(shì)和價(jià)值,那就是對(duì)于推薦結(jié)果的可解釋性。
- 因果推斷。
5. 因果推斷算不算召回的新算法?召回是怎么用因果推斷的。
- 因果推斷實(shí)現(xiàn)方式:在深度學(xué)習(xí)加一些embedding,對(duì)因果關(guān)系做一些建模。
- 因果推斷是一個(gè)理念,在召回中容易給熱門(mén)內(nèi)容打高分,形成馬太效應(yīng),因果推斷的理念指排除掉因?yàn)轳R太效應(yīng)出現(xiàn),而是因?yàn)橄嚓P(guān)性被召回。這是一個(gè)比較大的領(lǐng)域,最近研究的人比較多,是一個(gè)熱點(diǎn)。
- 在精排里試效果一般。
6. 在做召回時(shí),主要考慮的因素和性能指標(biāo)有哪些?
- 每一路召回算法,在后面精排曝光的占比。
- 快、相應(yīng)速度快,能在全量物品庫(kù)找用戶喜歡的東西。
- 每一路召回算法的點(diǎn)擊率也是看的。畢竟所有的優(yōu)化都是為了線上提效,所以一般看線上的指標(biāo)。點(diǎn)擊率是最明顯指標(biāo)的指標(biāo)。
- 有時(shí)候也看用戶轉(zhuǎn)化(是否電話聯(lián)系)。
- 算法是否上線,也要結(jié)合線上的指標(biāo)看。
5、排序
根據(jù)提前設(shè)定的目標(biāo),對(duì)信息進(jìn)行打分,使評(píng)分高的信息優(yōu)先展示給用戶。排序環(huán)節(jié)是推薦系統(tǒng)最關(guān)鍵,也是最具有技術(shù)含量的部分,目前大多數(shù)推薦技術(shù)其實(shí)都聚焦在這塊。
1. 排序算法
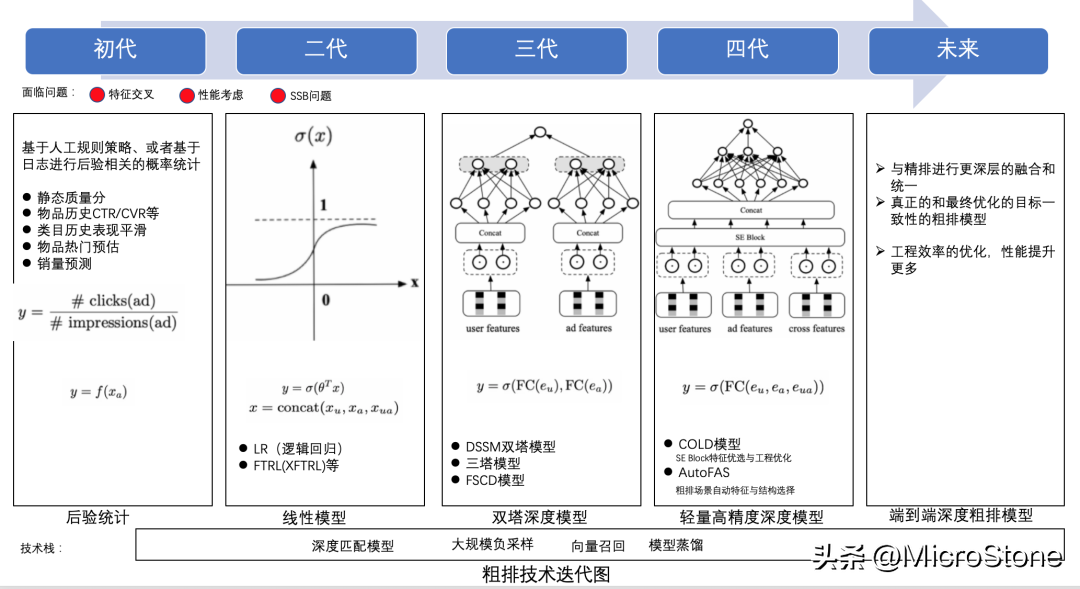
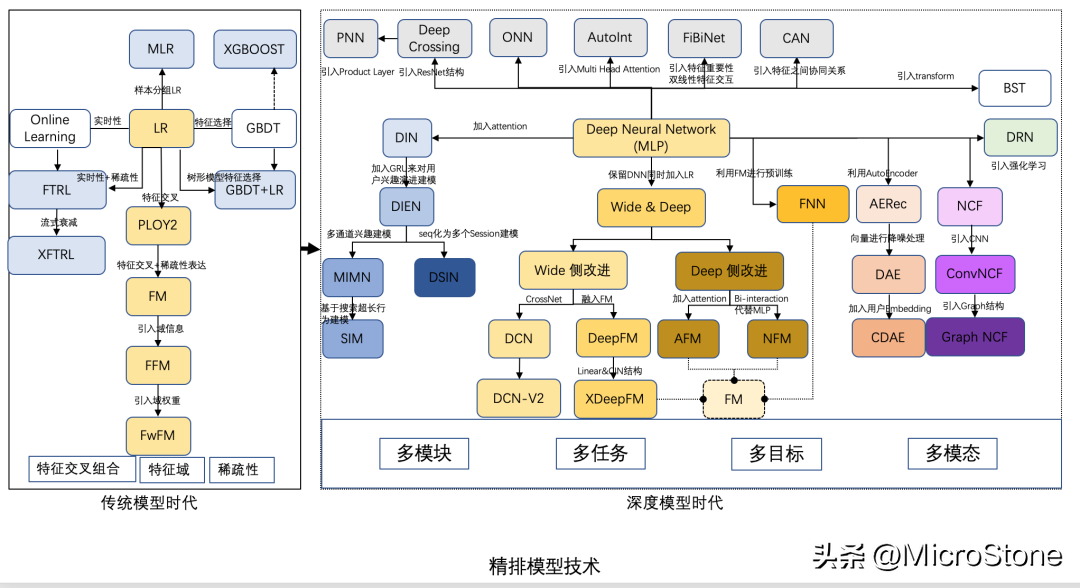
個(gè)人觀點(diǎn):
(1)粗排
- 粗排輸出的結(jié)果要給精排用,粗排的打分商品多,比如粗排打兩萬(wàn)個(gè),精排打top5k個(gè),粗排打分空間更大。
- 粗排的樣本選取和精排不能用同樣的樣本。粗排是所有商品,精排是在粗排的結(jié)果中選擇樣本。
- 粗排的要求是高效輸出,一般也是雙塔,因?yàn)橐欤荒苡锰珡?fù)雜的模型,都是基于一些簡(jiǎn)單的策略,截?cái)鄑opN,給到精排。
(2)精排
- 精排更集中于top商品,用有曝光的樣本去訓(xùn)練。優(yōu)中選優(yōu)。
- 難點(diǎn)是在特征工程做的很好的情況下,設(shè)計(jì)模型結(jié)構(gòu),得到更好的結(jié)果。
- 大部分公司用的阿里巴巴提供的din,一個(gè)開(kāi)源的算法包。
2. 多目標(biāo)優(yōu)化
多目標(biāo)優(yōu)化最關(guān)鍵的有兩個(gè)問(wèn)題。第一個(gè)問(wèn)題是多個(gè)優(yōu)化目標(biāo)的模型結(jié)構(gòu)問(wèn)題;第二個(gè)問(wèn)題是不同優(yōu)化目標(biāo)的重要性如何界定的問(wèn)題。
如何設(shè)定不同目標(biāo)權(quán)重,能夠盡量減少相互之間的負(fù)面影響,就非常重要。這塊貌似目前并沒(méi)有特別簡(jiǎn)單實(shí)用的方案,很多實(shí)際做法做起來(lái)還是根據(jù)經(jīng)驗(yàn)拍一些權(quán)重參數(shù)上線AB測(cè)試,費(fèi)時(shí)費(fèi)力。
而如何用模型自動(dòng)尋找最優(yōu)權(quán)重參數(shù)組合就是一個(gè)非常有價(jià)值的方向,目前最常用的方式是采用帕累托最優(yōu)的方案來(lái)進(jìn)行權(quán)重組合尋優(yōu)。
個(gè)人觀點(diǎn):
(1)精排的多目標(biāo)優(yōu)化用的比較多,比如總的目標(biāo)是成交gmv,就會(huì)分成點(diǎn)擊率和轉(zhuǎn)化率兩個(gè)目標(biāo)。
(2)多目標(biāo)訓(xùn)練的好處:
- 點(diǎn)擊率和轉(zhuǎn)化率如果分開(kāi)訓(xùn)練,打分就會(huì)有延時(shí),消耗的計(jì)算資源也會(huì)更大。
- 還有一個(gè)好處,多個(gè)目標(biāo)可以相互借鑒,特別是數(shù)據(jù)量稀疏的情況下。
(3)至于多目標(biāo)優(yōu)化,也有一些自動(dòng)化的方式調(diào)權(quán)重,但是一般是人工拍。拍很多組權(quán)重,不同組權(quán)重的模型,在同一份測(cè)試集上出效果。
(4)多目標(biāo)優(yōu)化一般用PLE(Progressive Layered Extraction),騰訊CGC出的模型,一直沒(méi)有被超越。新出的目標(biāo)關(guān)系之間的建模,db-mtl,esmm等,都不如PLE。
(5)經(jīng)典的還有Mmoe。
3. 多模態(tài)融合
在對(duì)專家的訪談中,發(fā)現(xiàn)業(yè)界對(duì)多模態(tài)的定義有兩種:
- 推薦的內(nèi)容同時(shí)有多種形式,比如文字、圖片、視頻等。
- 推薦的內(nèi)容同時(shí)有多種業(yè)務(wù)線,比如新房、二手房、租房等。
個(gè)人觀點(diǎn):
多模態(tài),比較讓人頭疼。
比如首頁(yè)推薦,內(nèi)容包括帖子、視頻,排序的時(shí)候怎么排,很難用統(tǒng)一的模型,因?yàn)樘印⒁曨l分屬于不同的業(yè)務(wù)線,很多特征在這條業(yè)務(wù)線上有,其他業(yè)務(wù)線上沒(méi)有。所以沒(méi)有好的統(tǒng)一的召回模型和統(tǒng)一的精排模型,只能偏人工策略。
某大廠采用的方法是,先算首頁(yè)有多少個(gè)坑位,基于流量?jī)r(jià)值和用戶喜歡哪條業(yè)務(wù)線,人工給權(quán)重,分給每個(gè)業(yè)務(wù)線多少個(gè)坑位,再將業(yè)務(wù)線中的商品按照推薦算出來(lái)的排序填充坑位。
4. 重排序
根據(jù)用戶最終的使用體驗(yàn)及運(yùn)營(yíng)需求,進(jìn)行排序結(jié)果的重新排序。
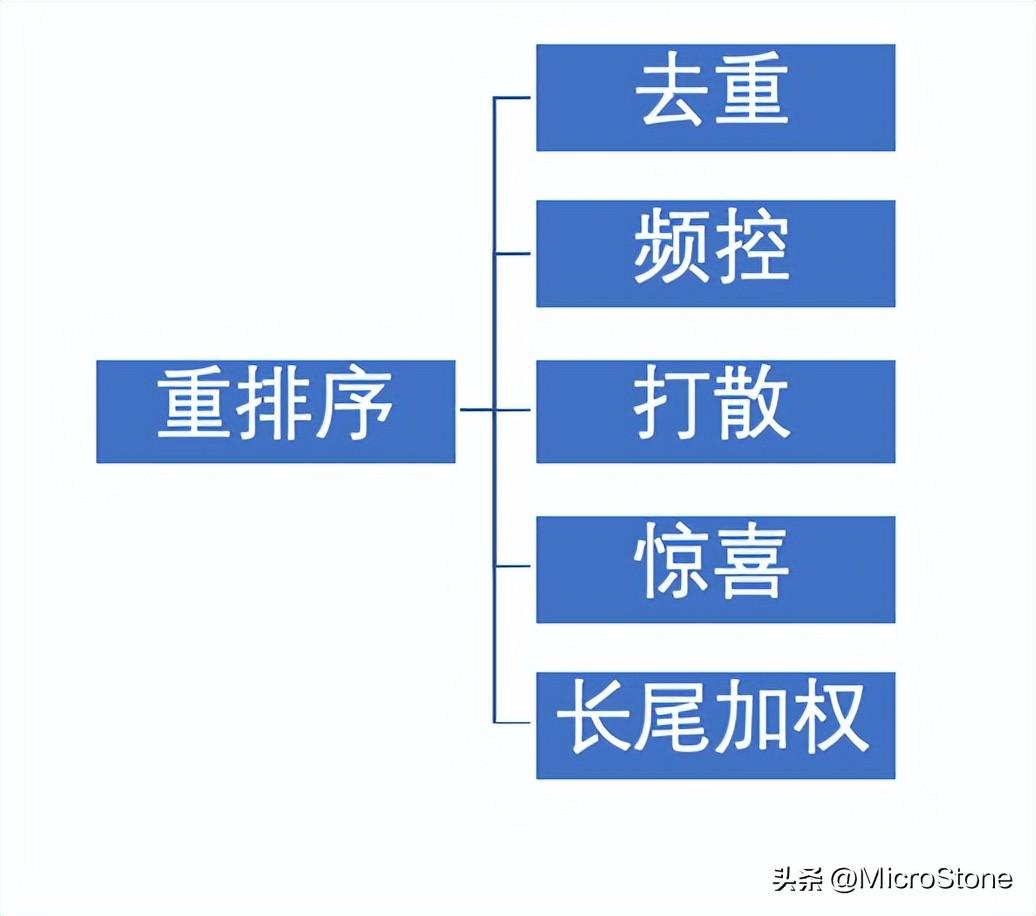
個(gè)人觀點(diǎn):
(1)難點(diǎn)
① 如何保證用戶滿意度最高的同時(shí),也保證創(chuàng)造者能夠得到流量。
- 對(duì)創(chuàng)造者進(jìn)行新手扶持,冷啟動(dòng)階段會(huì)給高一些的權(quán)重。
- 但是更加考慮用戶的滿意度。所以如果創(chuàng)造者內(nèi)容質(zhì)量低,也有可能不給流量。
② 用戶產(chǎn)品和商業(yè)產(chǎn)品的平衡:
- 有商業(yè)的產(chǎn)品,要保證收入。所以用戶產(chǎn)品排完序之后,要把商業(yè)產(chǎn)品排到前面去。
- 具體商業(yè)產(chǎn)品的排序,要多種權(quán)重,不斷權(quán)衡,嘗試商業(yè)產(chǎn)品排序掉一點(diǎn),商業(yè)價(jià)值不掉。
- 如果商業(yè)價(jià)值不變,但是整個(gè)模型數(shù)據(jù)提高,就可以上線。
6、其他步驟和需要注意的
1. 推薦系統(tǒng)的冷啟動(dòng)
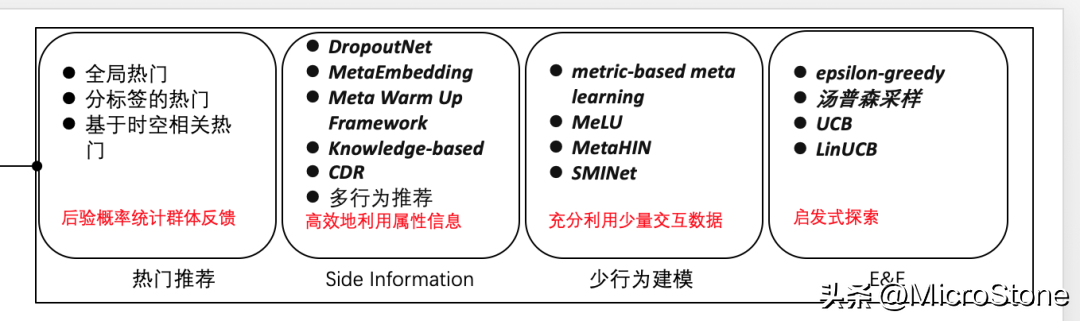
個(gè)人觀點(diǎn):
冷啟動(dòng)的解決辦法太多了。
① 類協(xié)同過(guò)濾的,找和新用戶基礎(chǔ)屬性相似,又行為豐富的人,推薦這樣的人喜歡的商品給新用戶。
② 通過(guò)ml的方法,因?yàn)槔鋯?dòng)行為少,先利用之前的數(shù)據(jù),訓(xùn)練好一個(gè)模型,直接賦給冷啟動(dòng)的用戶,這樣用少量數(shù)據(jù),模型也可以快速收斂。
③ 通過(guò)業(yè)務(wù)的規(guī)則去做。什么場(chǎng)景下,給用戶推薦什么內(nèi)容。
④ 圖神經(jīng)網(wǎng)絡(luò)。對(duì)物品冷啟動(dòng)有很好效果。
⑤ 用戶的冷啟動(dòng),可以收集跨域信息,比如去其他業(yè)務(wù)線包括二手房、商業(yè)地產(chǎn)收集用戶信息。
⑥ 還可以通過(guò)提示是否喜歡一些標(biāo)簽,來(lái)獲取用戶數(shù)據(jù)。
⑦ 冷啟動(dòng)的基本原則是老物品給新用戶,新物品給老用戶。
- 老物品給新用戶,指基于流行度,選擇熱門(mén)商品,給新用戶,做新用戶興趣的探索。
- 老用戶給新物品,老用戶已經(jīng)有行為,新物品與老用戶行為過(guò)的已有物品有關(guān)系,就推給老用戶,度過(guò)新物品的冷啟動(dòng)周期。
2. 推薦系統(tǒng)的評(píng)估指標(biāo)
個(gè)人觀點(diǎn):
離線評(píng)估指標(biāo):不同環(huán)節(jié),不同指標(biāo)。
- 召回和粗排中,使用hitrate。
- 精排中:是auc,NDCG。
業(yè)務(wù)場(chǎng)景中:
① 推薦系統(tǒng)評(píng)估使用工具:ab測(cè)試平臺(tái)。
② 使用指標(biāo):CTR、CVR、人均使用時(shí)長(zhǎng)、信息相關(guān)性等;
③ 也會(huì)關(guān)注留電率,但是這種線下數(shù)據(jù)太稀疏了,所以還是主要看CTR、CVR。
④ 平臺(tái)在不同階段關(guān)注的不同:
- 平臺(tái)在前期追求點(diǎn)擊率;
- 相對(duì)長(zhǎng)的時(shí)間段,關(guān)注用戶觀看時(shí)長(zhǎng);
- 更長(zhǎng)期:關(guān)注用戶的留存率。
7、推薦系統(tǒng)的應(yīng)用
個(gè)人觀點(diǎn):
推薦系統(tǒng)在不同的界面(比如首頁(yè)、購(gòu)買(mǎi)成功頁(yè)、商品詳情頁(yè))等,推薦系統(tǒng)的算法邏輯差異比較大。
- 在商品列表頁(yè)的推薦,主要是根據(jù)歷史行為推薦;
- 在商品詳情頁(yè)的推薦,主要是根據(jù)當(dāng)前商品推薦。
8、個(gè)人對(duì)整體推薦系統(tǒng)的觀點(diǎn)
1. 推薦系統(tǒng)在業(yè)務(wù)上的難點(diǎn)
不同的公司目標(biāo)不一樣,選用什么樣的數(shù)據(jù)模型來(lái)完成公司的戰(zhàn)略意圖。比如公司現(xiàn)在想要用戶的真實(shí)互動(dòng)和分享,推薦系統(tǒng)應(yīng)該把分享多的內(nèi)容推薦給用戶,但是這樣會(huì)導(dǎo)致誘導(dǎo)分享的內(nèi)容更容易被推薦。
如何判斷優(yōu)質(zhì)內(nèi)容,從而更好地把優(yōu)質(zhì)內(nèi)容推薦給用戶,是推薦系統(tǒng)在業(yè)務(wù)上的難點(diǎn)。
2. 精準(zhǔn)性和驚喜性的平衡
推薦系統(tǒng)的精準(zhǔn)性現(xiàn)在很容易做,基于上述全鏈路的算法,再配合好的特征,那么能得到一些好的商品。但是會(huì)面臨問(wèn)題:推薦商品很單一。比如點(diǎn)了很多連衣裙相關(guān)的,會(huì)不斷推連衣裙。推薦系統(tǒng)具有滯后性,只會(huì)推用戶已經(jīng)行為過(guò)這些東西。雖然用戶可能也會(huì)點(diǎn)擊,但是這樣對(duì)于一個(gè)推薦系統(tǒng),是不夠優(yōu)秀的。
如果用戶有多種興趣:連衣裙、小吃等,會(huì)有打散策略,給她推多種興趣的商品,這樣問(wèn)題還小一點(diǎn)。
如果用戶興趣單一,推薦系統(tǒng)就會(huì)只推她喜歡的那個(gè)興趣,就是推薦系統(tǒng)不夠好。
好的推薦系統(tǒng),要為用戶提供驚喜性、發(fā)現(xiàn)性,要推薦用戶恰好想要的。精準(zhǔn)性和發(fā)現(xiàn)性需要兼顧,做一個(gè)平衡。
3. 沒(méi)有數(shù)據(jù)是最難的。不斷會(huì)有新的場(chǎng)景出來(lái),新場(chǎng)景的數(shù)據(jù)不足。
**4. 推薦系統(tǒng)給新的內(nèi)容生產(chǎn)者的流量:**沒(méi)有看到一些很好的保量的算法。現(xiàn)在用的多的是pid,比例微分積分。投放速度快,就限制一些,投放速度慢,就減慢一些。
**5. 推薦對(duì)業(yè)務(wù)的價(jià)值:**怎么讓推薦對(duì)整個(gè)業(yè)務(wù)起到作用,讓整體業(yè)務(wù)增長(zhǎng)。
**6. 推薦所需的環(huán)境和條件:**數(shù)據(jù)、abtest、線上工程,都能具有非常好的魯棒性。















