1、背景
最近在學習hadoop,本文記錄一下,怎樣在Centos7系統上搭建一個3個節點的hadoop集群。
2、集群規劃
hadoop集群是由2個集群構成的,分別是hdfs集群和yarn集群。2個集群都是主從結構。
2.1 hdfs集群規劃
ip地址 | 主機名 | 部署服務 |
192.168.121.140 | hadoop01 | NameNode,DataNode,JobHistoryServer |
192.168.121.141 | hadoop02 | DataNode |
192.168.121.142 | hadoop03 | DataNode,SecondaryNameNode |
2.2 yarn集群規劃
ip地址 | 主機名 | 部署服務 |
192.168.121.140 | hadoop01 | NodeManager |
192.168.121.141 | hadoop02 | ResourceManager,NodeManager |
192.168.121.142 | hadoop03 | NodeManager |
3、集群搭建步驟
3.1 安裝JDK
安裝jdk步驟較為簡單,此處省略。需要注意的是hadoop需要的jdk版本。 https://cwiki.apache.org/confluence/display/HADOOP/Hadoop+Java+Versions
3.2 修改主機名和host映射
ip地址 | 主機名 |
192.168.121.140 | hadoop01 |
192.168.121.141 | hadoop02 |
192.168.121.142 | hadoop03 |
3臺機器上同時執行如下命令
# 此處修改主機名,3臺機器的主機名需要都不同
[root@hadoop01 ~]# vim /etc/hostname
[root@hadoop01 ~]# cat /etc/hostname
hadoop01
[root@hadoop01 ~]# vim /etc/hosts
[root@hadoop01 ~]# cat /etc/hosts | grep hadoop*
192.168.121.140 hadoop01
192.168.121.141 hadoop02
192.168.121.142 hadoop03
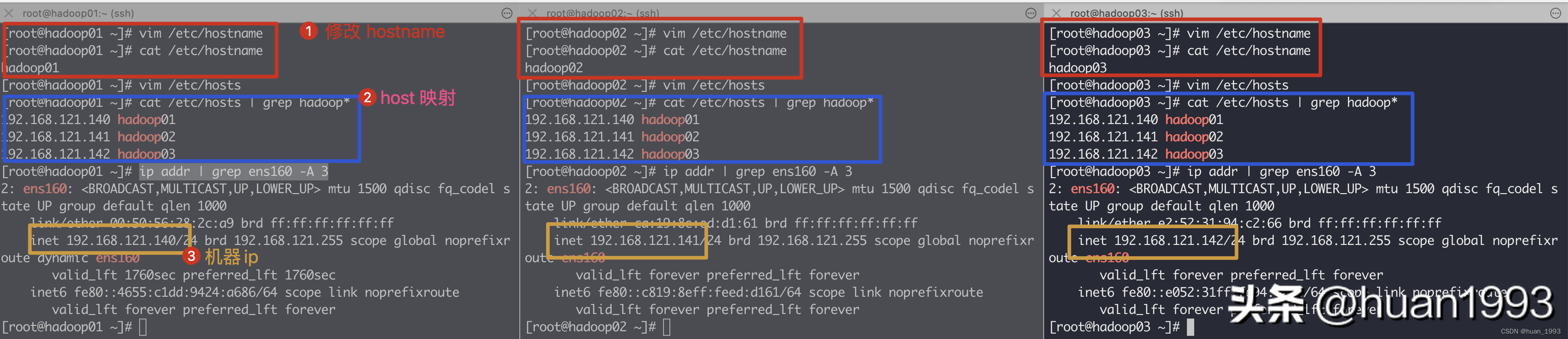
修改主機名和host映射
3.3 配置時間同步
集群中的時間最好保持一致,否則可能會有問題。此處我本地搭建,虛擬機是可以鏈接外網,直接配置和外網時間同步。如果不能鏈接外網,則集群中的3臺服務器,讓另外的2臺和其中的一臺保持時間同步。
3臺機器同時執行如下命令
# 將centos7的時區設置成上海
[root@hadoop01 ~]# ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
# 安裝ntp
[root@hadoop01 ~]# yum install ntp
已加載插件:fastestmirror
Loading mirror speeds from cached hostfile
base | 3.6 kB 00:00
extras | 2.9 kB 00:00
updates | 2.9 kB 00:00
軟件包 ntp-4.2.6p5-29.el7.centos.2.aarch64 已安裝并且是最新版本
無須任何處理
# 將ntp設置成缺省啟動
[root@hadoop01 ~]# systemctl enable ntpd
# 重啟ntp服務
[root@hadoop01 ~]# service ntpd restart
Redirecting to /bin/systemctl restart ntpd.service
# 對準時間
[root@hadoop01 ~]# ntpdate asia.pool.ntp.org
19 Feb 12:36:22 ntpdate[1904]: the NTP socket is in use, exiting
# 對準硬件時間和系統時間
[root@hadoop01 ~]# /sbin/hwclock --systohc
# 查看時間
[root@hadoop01 ~]# timedatectl
Local time: 日 2023-02-19 12:36:35 CST
Universal time: 日 2023-02-19 04:36:35 UTC
RTC time: 日 2023-02-19 04:36:35
Time zone: Asia/Shanghai (CST, +0800)
NTP enabled: yes
NTP synchronized: no
RTC in local TZ: no
DST active: n/a
# 開始自動時間和遠程ntp時間進行同步
[root@hadoop01 ~]# timedatectl set-ntp true
3.4 關閉防火墻
3臺機器上同時關閉防火墻,如果不關閉的話,則需要放行hadoop可能用到的所有端口等。
# 關閉防火墻
[root@hadoop01 ~]# systemctl stop firewalld
systemctl stop firewalld
# 關閉防火墻開機自啟
[root@hadoop01 ~]# systemctl disable firewalld.service
Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service.
Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.
[root@hadoop01 ~]#
3.5 配置ssh免密登錄
3.5.1 新建hadoop部署用戶
[root@hadoop01 ~]# useradd hadoopdeploy
[root@hadoop01 ~]# passwd hadoopdeploy
更改用戶 hadoopdeploy 的密碼 。
新的 密碼:
無效的密碼: 密碼包含用戶名在某些地方
重新輸入新的 密碼:
passwd:所有的身份驗證令牌已經成功更新。
[root@hadoop01 ~]# vim /etc/sudoers
[root@hadoop01 ~]# cat /etc/sudoers | grep hadoopdeploy
hadoopdeploy ALL=(ALL) NOPASSWD: ALL
[root@hadoop01 ~]#

新建hadoop部署用戶
3.5.2 配置hadoopdeploy用戶到任意一臺機器都免密登錄
配置3臺機器,從任意一臺到自身和另外2臺都進行免密登錄。
當前機器當前用戶免密登錄的機器免密登錄的用戶hadoop01hadoopdeployhadoop01,hadoop02,hadoop03hadoopdeployhadoop02hadoopdeployhadoop01,hadoop02,hadoop03hadoopdeployhadoop03hadoopdeployhadoop01,hadoop02,hadoop03hadoopdeploy
此處演示從 hadoop01到hadoop01,hadoop02,hadoop03免密登錄的shell
# 切換到 hadoopdeploy 用戶
[root@hadoop01 ~]# su - hadoopdeploy
Last login: Sun Feb 19 13:05:43 CST 2023 on pts/0
# 生成公私鑰對,下方的提示直接3個回車即可
[hadoopdeploy@hadoop01 ~]$ ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hadoopdeploy/.ssh/id_rsa):
Created directory '/home/hadoopdeploy/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/hadoopdeploy/.ssh/id_rsa.
Your public key has been saved in /home/hadoopdeploy/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:PFvgTUirtNLwzDIDs+SD0RIzMPt0y1km5B7rY16h1/E hadoopdeploy@hadoop01
The key's randomart image is:
+---[RSA 2048]----+
|B . . |
| B o . o |
|+ * * + + . |
| O B / = + |
|. = @ O S o |
| o * o * |
| = o o E |
| o + |
| . |
+----[SHA256]-----+
[hadoopdeploy@hadoop01 ~]$ ssh-copy-id hadoop01
...
[hadoopdeploy@hadoop01 ~]$ ssh-copy-id hadoop02
...
[hadoopdeploy@hadoop01 ~]$ ssh-copy-id hadoop03
3.7 配置hadoop
此處如無特殊說明,都是使用的hadoopdeploy用戶來操作。
3.7.1 創建目錄(3臺機器都執行)
# 創建 /opt/bigdata 目錄
[hadoopdeploy@hadoop01 ~]$ sudo mkdir /opt/bigdata
# 將 /opt/bigdata/ 目錄及它下方所有的子目錄的所屬者和所屬組都給 hadoopdeploy
[hadoopdeploy@hadoop01 ~]$ sudo chown -R hadoopdeploy:hadoopdeploy /opt/bigdata/
[hadoopdeploy@hadoop01 ~]$ ll /opt
total 0
drwxr-xr-x. 2 hadoopdeploy hadoopdeploy 6 Feb 19 13:15 bigdata
3.7.2 下載hadoop并解壓(hadoop01操作)
# 進入目錄
[hadoopdeploy@hadoop01 ~]$ cd /opt/bigdata/
# 下載
[hadoopdeploy@hadoop01 ~]$ https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz
# 解壓并壓縮
[hadoopdeploy@hadoop01 bigdata]$ tar -zxvf hadoop-3.3.4.tar.gz && rm -rvf hadoop-3.3.4.tar.gz
3.7.3 配置hadoop環境變量(hadoop01操作)
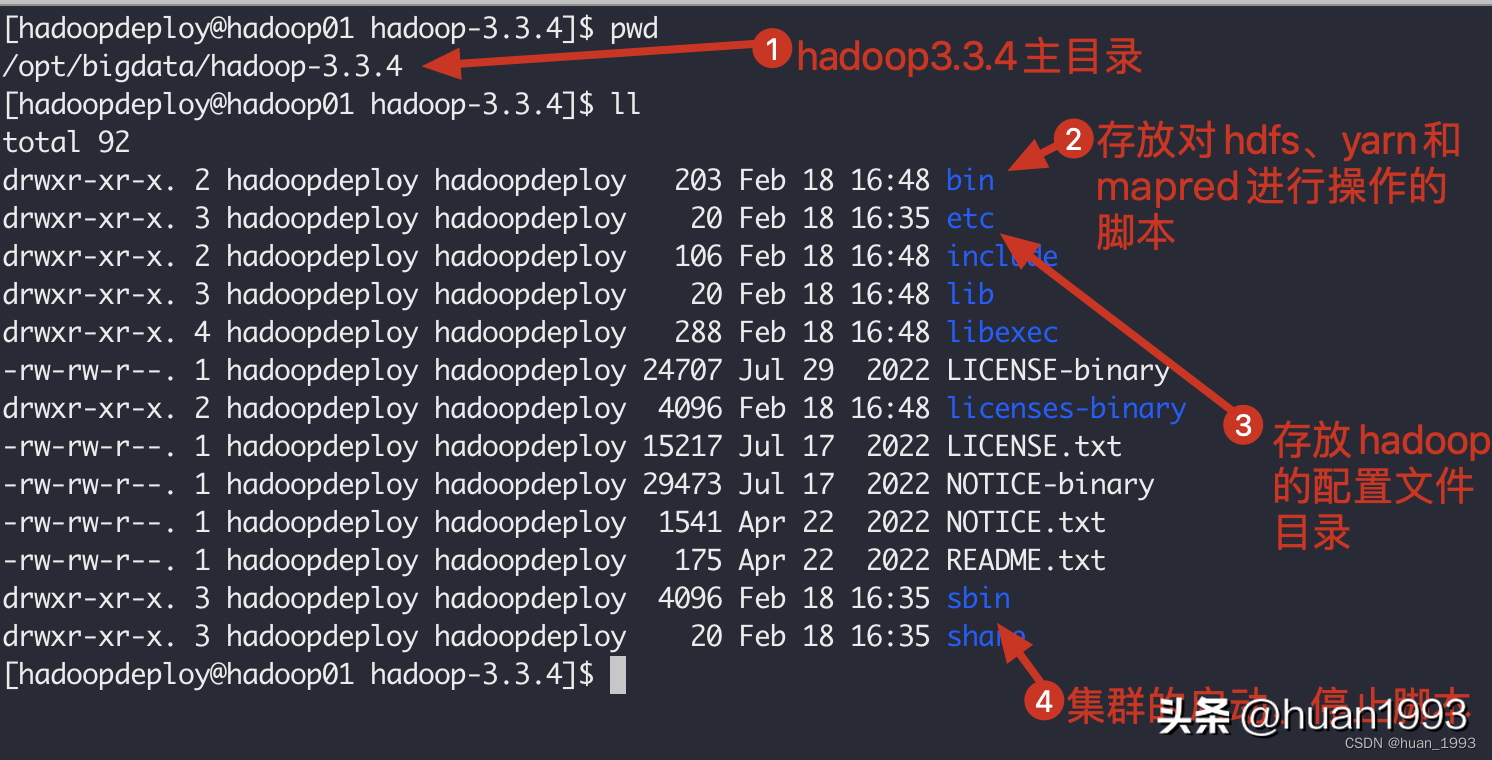
hadoop的目錄結構
# 進入hadoop目錄
[hadoopdeploy@hadoop01 hadoop-3.3.4]$ cd /opt/bigdata/hadoop-3.3.4/
# 切換到root用戶
[hadoopdeploy@hadoop01 hadoop-3.3.4]$ su - root
Password:
Last login: Sun Feb 19 13:06:41 CST 2023 on pts/0
[root@hadoop01 ~]# vim /etc/profile
# 查看hadoop環境變量配置
[root@hadoop01 ~]# tail -n 3 /etc/profile
# 配置HADOOP
export HADOOP_HOME=/opt/bigdata/hadoop-3.3.4/
export PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH
# 讓環境變量生效
[root@hadoop01 ~]# source /etc/profile
3.7.4 hadoop的配置文件分類(hadoop01操作)
在hadoop中配置文件大概有這么3大類。
- 默認的只讀配置文件: core-default.xml, hdfs-default.xml, yarn-default.xml and mapred-default.xml.
- 自定義配置文件: etc/hadoop/core-site.xml, etc/hadoop/hdfs-site.xml, etc/hadoop/yarn-site.xml and etc/hadoop/mapred-site.xml 會覆蓋默認的配置。
- 環境配置文件: etc/hadoop/hadoop-env.sh and optionally the etc/hadoop/mapred-env.sh and etc/hadoop/yarn-env.sh 比如配置NameNode的啟動參數HDFS_NAMENODE_OPTS等。

hadoop的配置文件
3.7.5 配置 hadoop-env.sh(hadoop01操作)
# 切換到hadoopdeploy用戶
[root@hadoop01 ~]# su - hadoopdeploy
Last login: Sun Feb 19 14:22:50 CST 2023 on pts/0
# 進入到hadoop的配置目錄
[hadoopdeploy@hadoop01 ~]$ cd /opt/bigdata/hadoop-3.3.4/etc/hadoop/
[hadoopdeploy@hadoop01 hadoop]$ vim hadoop-env.sh
# 增加如下內容
export JAVA_HOME=/usr/local/jdk8
export HDFS_NAMENODE_USER=hadoopdeploy
export HDFS_DATANODE_USER=hadoopdeploy
export HDFS_SECONDARYNAMENODE_USER=hadoopdeploy
export YARN_RESOURCEMANAGER_USER=hadoopdeploy
export YARN_NODEMANAGER_USER=hadoopdeploy
3.7.6 配置core-site.xml文件(hadoop01操作)(核心配置文件)
默認配置文件路徑:https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/core-default.xml
vim /opt/bigdata/hadoop-3.3.4/etc/hadoop/core-site.xml
<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:8020</value>
</property>
<!-- 指定hadoop數據的存儲目錄 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/bigdata/hadoop-3.3.4/data</value>
</property>
<!-- 配置HDFS網頁登錄使用的靜態用戶為hadoopdeploy,如果不配置的話,當在hdfs頁面點擊刪除時>看看結果 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoopdeploy</value>
</property>
<!-- 文件垃圾桶保存時間 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
</configuration>
3.7.7 配置hdfs-site.xml文件(hadoop01操作)(hdfs配置文件)
默認配置文件路徑:https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
vim /opt/bigdata/hadoop-3.3.4/etc/hadoop/hdfs-site.xml
<configuration>
<!-- 配置2個副本 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- nn web端訪問地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop01:9870</value>
</property>
<!-- snn web端訪問地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop03:9868</value>
</property>
</configuration>
3.7.8 配置yarn-site.xml文件(hadoop01操作)(yarn配置文件)
默認配置文件路徑:https://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
vim /opt/bigdata/hadoop-3.3.4/etc/hadoop/yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 指定ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop02</value>
</property>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 是否對容器實施物理內存限制 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 是否對容器實施虛擬內存限制 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 設置 yarn 歷史服務器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop02:19888/jobhistory/logs</value>
</property>
<!-- 開啟日志聚集-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 聚集日志保留的時間7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
3.7.9 配置mapred-site.xml文件(hadoop01操作)(mapreduce配置文件)
默認配置文件路徑:https://hadoop.apache.org/docs/current/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml
vim /opt/bigdata/hadoop-3.3.4/etc/hadoop/yarn-site.xml
<configuration>
<!-- 設置 MR 程序默認運行模式:yarn 集群模式,local 本地模式-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- MR 程序歷史服務地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop01:10020</value>
</property>
<!-- MR 程序歷史服務器 web 端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop01:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
</configuration>
3.7.10 配置workers文件(hadoop01操作)
vim /opt/bigdata/hadoop-3.3.4/etc/hadoop/workers
workers配置文件中不要有多余的空格或換行。
3.7.11 3臺機器hadoop配置同步(hadoop01操作)
# 同步 hadoop 文件
[hadoopdeploy@hadoop01 hadoop]$ scp -r /opt/bigdata/hadoop-3.3.4/ hadoopdeploy@hadoop02:/opt/bigdata/hadoop-3.3.4
[hadoopdeploy@hadoop01 hadoop]$ scp -r /opt/bigdata/hadoop-3.3.4/ hadoopdeploy@hadoop03:/opt/bigdata/hadoop-3.3.4
- hadoop02和hadoop03設置hadoop的環境變量
[hadoopdeploy@hadoop03 bigdata]$ su - root
Password:
Last login: Sun Feb 19 13:07:40 CST 2023 on pts/0
[root@hadoop03 ~]# vim /etc/profile
[root@hadoop03 ~]# tail -n 4 /etc/profile
# 配置HADOOP
export HADOOP_HOME=/opt/bigdata/hadoop-3.3.4/
export PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH
[root@hadoop03 ~]# source /etc/profile
4啟動集群
4.1 集群格式化
當是第一次啟動集群時,需要對hdfs進行格式化,在NameNode節點操作。
[hadoopdeploy@hadoop01 hadoop]$ hdfs namenode -format
4.2 集群啟動
啟動集群有2種方式
- ? 方式一: 每臺機器逐個啟動進程,比如:啟動NameNode,啟動DataNode,可以做到精確控制每個進程的啟動。
- ? 方式二: 配置好各個機器之間的免密登錄并且配置好 workers 文件,通過腳本一鍵啟動。
4.2.1 逐個啟動進程
# HDFS 集群
[hadoopdeploy@hadoop01 hadoop]$ hdfs --daemon start namenode | datanode | secondarynamenode
# YARN 集群
[hadoopdeploy@hadoop01 hadoop]$ hdfs yarn --daemon start resourcemanager | nodemanager | proxyserver
4.2.2 腳本一鍵啟動
- ? start-dfs.sh 一鍵啟動hdfs集群的所有進程
- ? start-yarn.sh 一鍵啟動yarn集群的所有進程
- ? start-all.sh 一鍵啟動hdfs和yarn集群的所有進程
4.3 啟動集群
4.3.1 啟動hdfs集群
需要在NameNode這臺機器上啟動
# 改腳本啟動集群中的 NameNode、DataNode和SecondaryNameNode
[hadoopdeploy@hadoop01 hadoop]$ start-dfs.sh
4.3.2 啟動yarn集群
需要在ResourceManager這臺機器上啟動
# 該腳本啟動集群中的 ResourceManager 和 NodeManager 進程
[hadoopdeploy@hadoop02 hadoop]$ start-yarn.sh
4.3.3 啟動JobHistoryServer
[hadoopdeploy@hadoop01 hadoop]$ mapred --daemon start historyserver
4.4 查看各個機器上啟動的服務是否和我們規劃的一致

查看各個機器上啟動的服務是否和我們規劃的一致 查看各個機器上啟動的服務是否和我們規劃的一致
可以看到是一致的。
4.5 訪問頁面
4.5.1 訪問NameNode ui (hdfs集群)
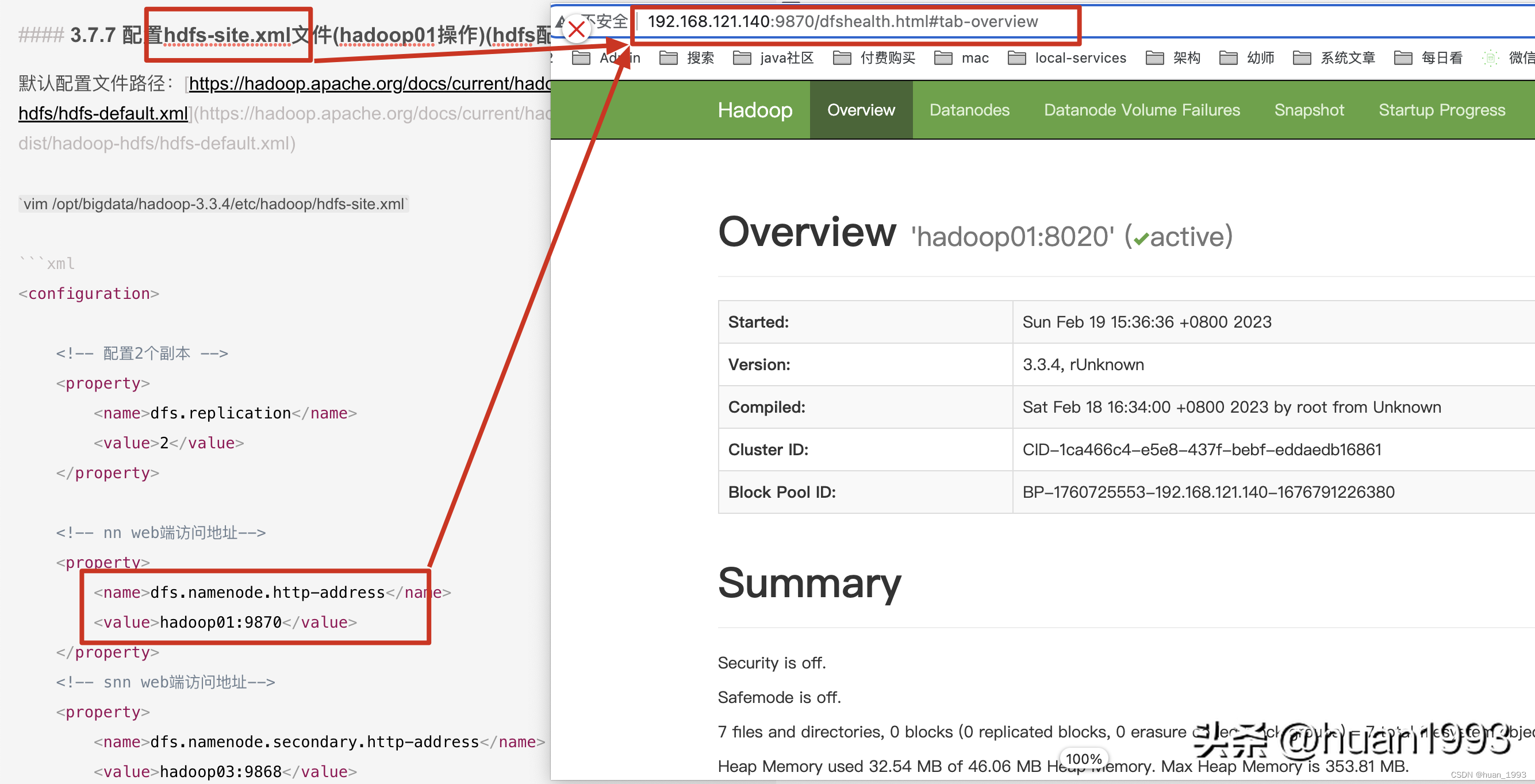
訪問NameNode ui
如果這個時候通過 hadoop fs 命令可以上傳文件,但是在這個web界面上可以創建文件夾,但是上傳文件報錯,此處就需要在訪問ui界面的這個電腦的hosts文件中,將部署hadoop的那幾臺的電腦的ip 和hostname 在本機上進行映射。
4.5.2 訪問SecondaryNameNode ui
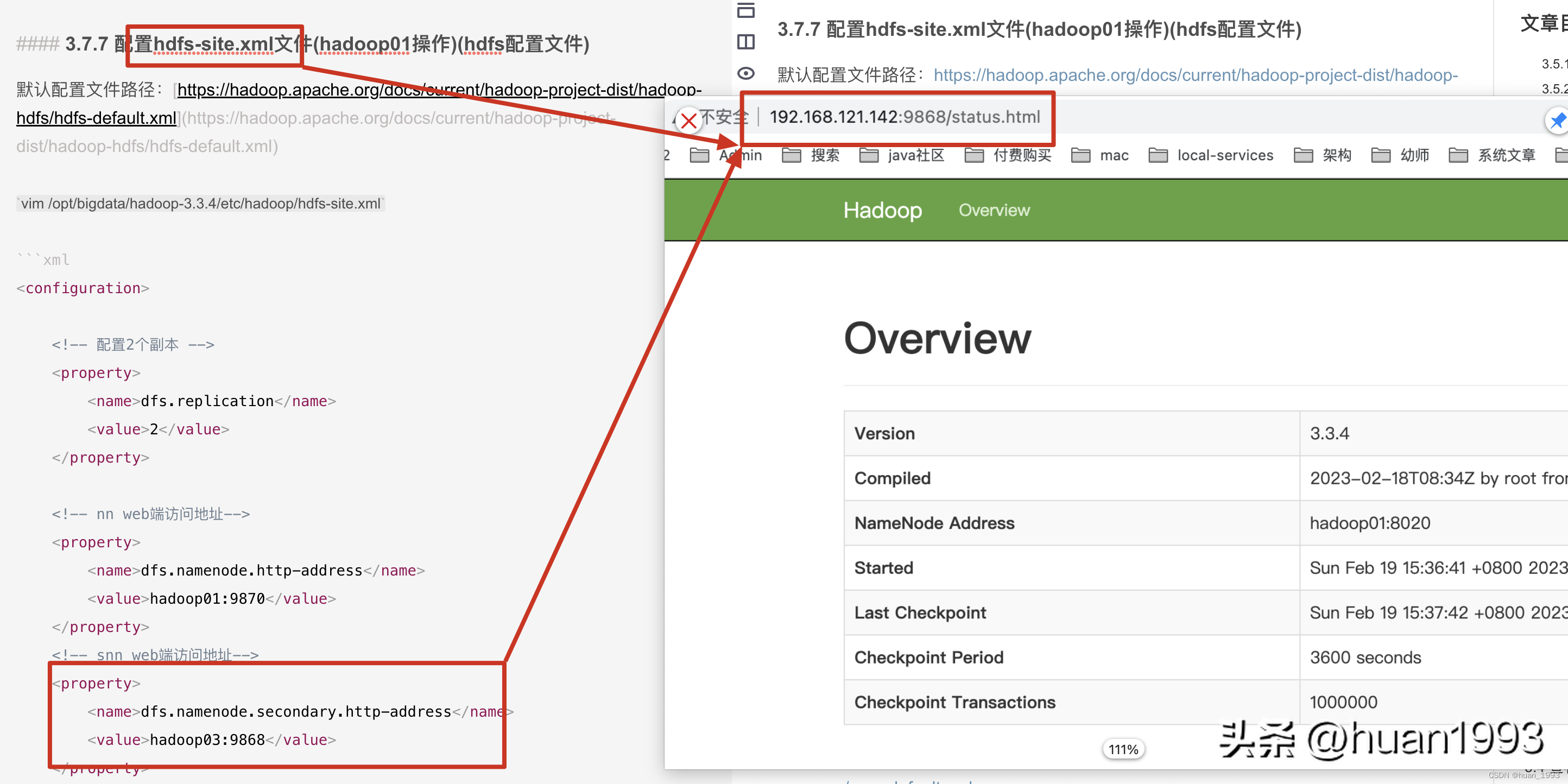
訪問SecondaryNameNode ui
4.5.3 查看ResourceManager ui(yarn集群)
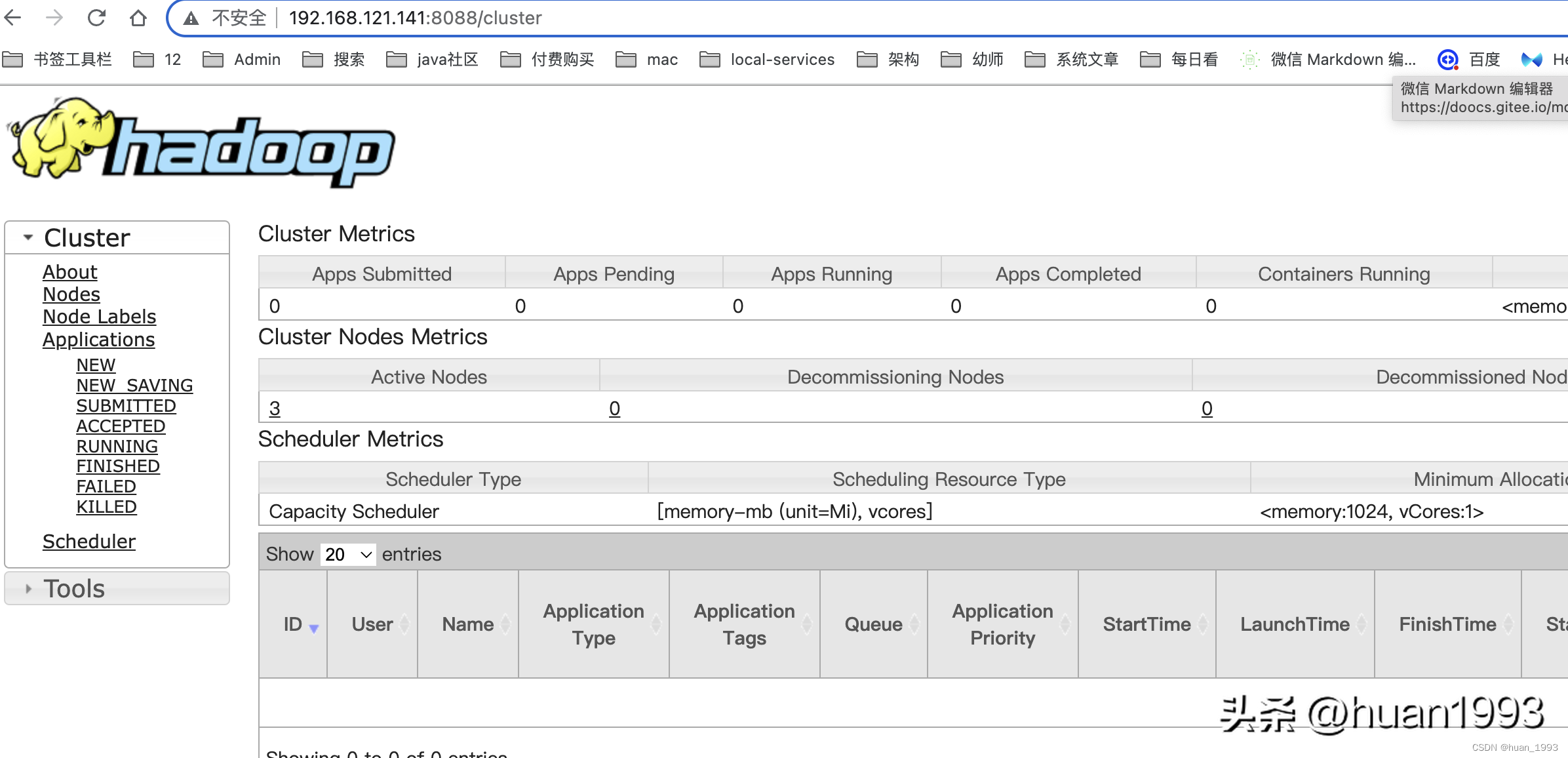
查看ResourceManager ui
4.5.4 訪問jobhistory
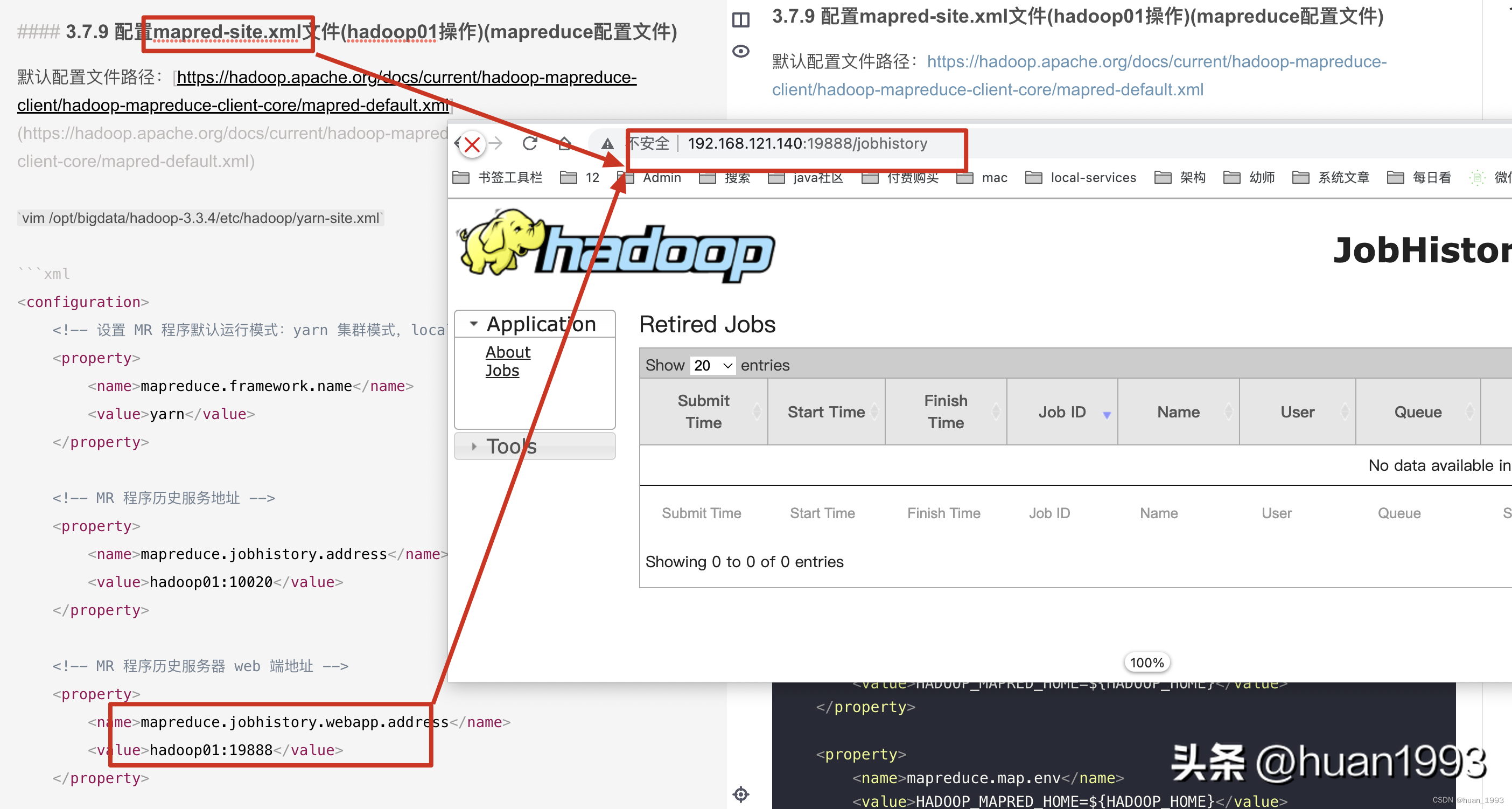
訪問jobhistory
5、參考鏈接
1、https://cwiki.apache.org/confluence/display/HADOOP/Hadoop+Java+Versions
2、https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/ClusterSetup.html










































