列數據庫是什么東東?何時應該使用它?
譯文?譯者 | 布加迪
審校 | 孫淑娟
說到為具體應用選擇數據庫,有很多不同的選項。經常討論的話題似乎是選擇SQL數據庫還是選擇NoSQL數據庫,即數據應該存儲在關系數據庫中,還是存儲在鍵值、文檔或圖形數據庫之類的NoSQL數據庫中。

另一種選擇是索性使用列數據庫。本文介紹為什么有必要做出這種選擇,以及列數據庫的一些優缺點。
列數據庫的定義
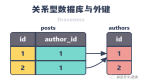
顧名思義,列(或列式)數據庫將按列組織而不是按行組織的數據存儲在磁盤上。以物聯網傳感器為例,基于行的數據庫會如圖所示將數據存儲在磁盤上:

而列數據庫將組織相同的數據,以便每個列值按順序存儲在磁盤上:
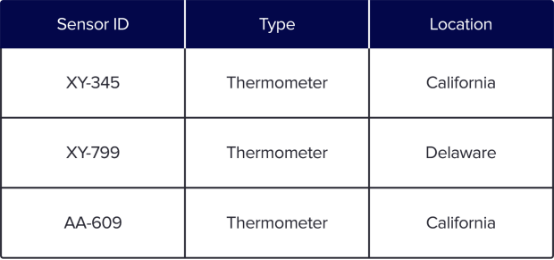
列數據庫的主要優點是,由于壓縮比提高,它可以大大縮減存儲數據所需的磁盤空間。此外,列數據庫在處理分析型查詢時比基于行的傳統數據庫要快得多。
為什么列數據庫適合分析型工作負載?
那么,改變數據的存儲格式究竟如何提升性能的呢?與傳統數據庫相比,有幾個因素導致列數據庫能夠為聯機分析處理(LAP)工作負載提供高得多的性能。
第一個原因是壓縮比提高。這是由于列數據庫能夠為每種類型的數據使用最佳壓縮算法,因為每列都是相同類型的數據,而不是一行混合類型的數據。這不僅降低了磁盤上的存儲成本,還提高了性能,因為需要的磁盤尋道更少,內存可以容納更多的數據。
列數據庫提升性能的另一種方法是實際上在底層存儲同一列的多個不同版本,這些版本按不同的順序進行排序,以便為某些查詢加快過濾和選擇的速度。
列數據庫還可以通過許多其他方法來提升性能。下面是幾個例子:
- 查詢數據時進行自適應索引
- 矢量化處理
- 列的連接經過優化,變得更有效
- 列的后期物化
這篇??論文??分析了列數據庫的性能,作為論文一部分進行的測試的示意圖顯示了上述優化的結果。基于TPC-H數據倉庫基準數據集,列數據庫的運行速度比傳統的行結構數據庫快10倍左右。
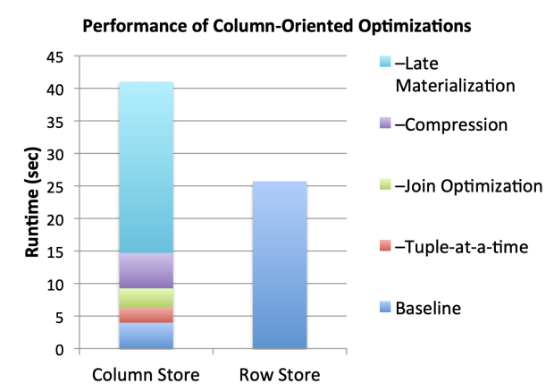
該圖顯示了哪些優化對列數據庫的性能影響最大,在此處,后期物化帶來的性能提升最大。
列數據庫性能方面的取舍
與計算機科學界的幾乎所有事情一樣,列數據庫性能方面也進行了一番取舍。它們針對分析型工作負載進行了優化,本身不適合傳統的聯機事務處理(OLTP)工作負載,而關系數據庫為這種工作負載而設計。
最大的性能犧牲將出現在試圖更新特定數據點或寫入單個數據點的情況下。就列數據庫而言,您希望盡可能批量插入數據。
列數據庫還會對讀查詢有影響,您獲取一行中的所有數據,就像使用關系數據庫一樣。由于必須重新構造每一列才能創建整行,因此性能會受到影響。
列數據庫的用例
列數據庫非常適合您想要分析大量數據的任何情況。不妨看一下幾個常見的用例。
商業智能
列數據庫非常適合分析銷售數據,因為它們讓您可以以各種方式劃分信息。這可以幫助您確定可能無法看到的趨勢和模式。比如說,可以使用列數據庫按位置、品牌或產品類別來比較一段時間不同產品的銷售數據。
應用程序性能監控
應用程序性能監控是使用列數據庫幫助提高軟件可靠性和性能的另一種常見情況。通過跟蹤和分析有關應用程序運行狀況的數據,您可以在問題導致應用程序崩潰或變慢之前發現問題。這有助于避免停運時間,并確保用戶獲得最佳體驗。如果使用列數據庫,您可以存儲粒度更細的數據以獲得更深入的洞察力,同時因出色的數據壓縮而降低成本。
物聯網
組織在部署越來越多的聯網設備,其中許多設備收集用于分析工作負載的數據。列數據庫可用于存儲這些數據,以實現實時警報,還可用于生成預測,在許多不同行業提高效率。
專門化列數據庫的示例
到目前為止,我們已經大體了解了列數據庫及其優點。雖然所有列數據庫有相同的特征,可以有效地用作通用數據倉庫或數據湖,不過下面介紹如何針對更具體的性能特征對它們進行調優和優化。
InfluxDB IOx
InfluxDB IOx是一款面向InfluxDB的開源列存儲引擎,為處理時間序列數據進行了優化。時間序列數據在性能方面帶來了獨特的挑戰:
- 分析類型的查詢,只需要幾列數據,比如從傳感器獲得過去一周的平均溫度。
- 關系類型的查詢,用戶需要過去5分鐘內來自許多不同傳感器的所有可用信息。
時間序列數據還往往大批量到達,這需要快速獲取能力,以便能夠快速索引和查詢數據,用于實時監控和警報。此外,許多用戶希望能夠長期存儲這些數據,用于歷史分析和預測,又不必擔心成本過高。
InfluxDB讓用戶可以集兩者之所長,其辦法是管理數據的生命周期,并在熱存儲和冷存儲之間移動數據,歷史數據方面獲得快速性能,同時通過對未頻繁查詢的數據使用更便宜的對象存儲來降低存儲成本。
實現這一目標的關鍵手段就是構建和貢獻Apache Arrow、DataFusion和Parquet之類的項目。Arrow允許數據在內存中以列格式壓縮,并在數據庫的不同部分之間移動。Parquet用于高效的持久性存儲,DataFusion提供高性能查詢和SQL支持。其他許多主要項目和廠商也在夯實Parquet和Arrow項目,這些項目還能夠與更廣泛的大數據生態系統實現集成和兼容。
ApacheDruid
Apache Druid是一款擁有底層列數據結構的實時數據庫。Druid適用于典型的數據倉庫類型工作負載,比如您期望從列數據庫獲得的工作負載,但它也優先考慮低延遲響應時間,常常用于交互式用戶界面之類的對象。
DuckDB
DuckDB是為OLAP工作負載設計的進程內數據庫,實際上旨在成為面向分析的SQLite。DuckDB使用列式矢量化處理,以出色的性能運行SQL查詢,可以輕松嵌入到應用程序中。DuckDB的主要賣點是,在大多數OLAP數據庫要么云托管要么需要復雜安裝過程的環境下,它很容易在本地設置和運行。
選擇適合具體任務的工具
說到底,技術決策歸結為什么技術對您的用例有意義。說到長期構建應用程序,選擇數據庫可能是最重要的選擇之一,因此有必要了解所有可用的選項,選擇最適合的那一種。
如果您在處理主要用于分析的大量數據,那么列數據庫可能是個不錯的選擇。
原文標題:??What Is a Column Database and When Should You Use One???,作者:Charles Mahler?