如何解決混合精度訓練大模型的局限性問題
混合精度已經成為訓練大型深度學習模型的必要條件,但也帶來了許多挑戰。將模型參數和梯度轉換為較低精度數據類型(如FP16)可以加快訓練速度,但也會帶來數值穩定性的問題。使用進行FP16 訓練梯度更容易溢出或不足,導致優化器計算不精確,以及產生累加器超出數據類型范圍的等問題。

在這篇文章中,我們將討論混合精確訓練的數值穩定性問題。為了處理數值上的不穩定性,大型訓練工作經常會被擱置數天,會導致項目的延期。所以我們可以引入Tensor Collection Hook來監控訓練期間的梯度條件,這樣可以更好地理解模型的內部狀態,更快地識別數值不穩定性。
在早期訓練階段了解模型的內部狀態可以判斷模型在后期訓練中是否容易出現不穩定是非常好的辦法,如果能夠在訓練的頭幾個小時就能識別出梯度不穩定性,可以幫助我們提升很大的效率。所以本文提供了一系列值得關注的警告,以及數值不穩定性的補救措施。
混合精度訓練
隨著深度學習繼續向更大的基礎模型發展。像GPT和T5這樣的大型語言模型現在主導著NLP,在CV中對比模型(如CLIP)的泛化效果優于傳統的監督模型。特別是CLIP的學習文本嵌入意味著它可以執行超過過去CV模型能力的零樣本和少樣本推理,訓練這些模型都是一個挑戰。
這些大型的模型通常涉及深度transformers網絡,包括視覺和文本,并且包含數十億個參數。GPT3有1750億個參數,CLIP則是在數百tb的圖像上進行訓練的。模型和數據的大小意味著模型需要在大型GPU集群上進行數周甚至數月的訓練。為了加速訓練減少所需gpu的數量,模型通常以混合精度進行訓練。
混合精確訓練將一些訓練操作放在FP16中,而不是FP32。在FP16中進行的操作需要更少的內存,并且在現代gpu上可以比FP32的處理速度快8倍。盡管在FP16中訓練的大多數模型精度較低,但由于過度的參數化它們沒有顯示出任何的性能下降。
隨著英偉達在Volta架構中引入Tensor Cores,低精度浮點加速訓練更加快速。因為深度學習模型有很多參數,任何一個參數的確切值通常都不重要。通過用16位而不是32位來表示數字,可以一次性在Tensor Core寄存器中擬合更多參數,增加每個操作的并行性。

但FP16的訓練是存在挑戰性的。因為FP16不能表示絕對值大于65,504或小于5.96e-8的數字。深度學習框架例如如PyTorch帶有內置工具來處理FP16的限制(梯度縮放和自動混合精度)。但即使進行了這些安全檢查,由于參數或梯度超出可用范圍而導致大型訓練工作失敗的情況也很常見。深度學習的一些組件在FP32中發揮得很好,但是例如BN通常需要非常細粒度的調整,在FP16的限制下會導致數值不穩定,或者不能產生足夠的精度使模型正確收斂。這意味著模型并不能盲目地轉換為FP16。
所以深度學習框架使用自動混合精度(AMP),它通過一個預先定義的FP16訓練安全操作列表。AMP只轉換模型中被認為安全的部分,同時將需要更高精度的操作保留在FP32中。另外在混合精度訓練中模型中通過給一些接近于零梯度(低于FP16的最小范圍)的損失乘以一定數值來獲得更大的梯度,然后在應用優化器更新模型權重時將按比例向下調整來解決梯度過小的問題,這種方法被稱為梯度縮放。
下面是PyTorch中一個典型的AMP訓練循環示例。

梯度縮放器scaler會將損失乘以一個可變的量。如果在梯度中觀察到nan,則將倍數降低一半,直到nan消失,然后在沒有出現nan的情況下,默認每2000步逐漸增加倍數。這樣會保持梯度在FP16范圍內,同時也防止梯度變為零。
訓練不穩定的案例
盡管框架都盡了最大的努力,但PyTorch和TensorFlow中內置的工具都不能阻止在FP16中出現的數值不穩定情況。
在HuggingFace的T5實現中,即使在訓練之后模型變體也會產生INF值。在非常深的T5模型中,注意力值會在層上累積,最終達到FP16范圍之外,這會導致值無窮大,比如在BN層中出現nan。他們是通過將INF值改為在FP16的最大值解決了這個問題,并且發現這對推斷的影響可以忽略不計。
另一個常見問題是ADAM優化器的限制。作為一個小更新,ADAM使用梯度的第一和第二矩的移動平均來適應模型中每個參數的學習率。
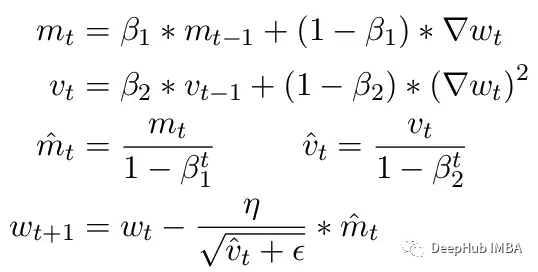
這里Beta1 和 Beta2 是每個時刻的移動平均參數,通常分別設置為 .9 和 .999。用 beta 參數除以步數的冪消除了更新中的初始偏差。在更新步驟中,向二階矩參數添加一個小的 epsilon 以避免被零除產生錯誤。epsilon 的典型默認值是 1e-8。但 FP16 的最小值為 5.96e-8。這意味著如果二階矩太小,更新將除以零。所以在 PyTorch 中為了訓練不會發散,更新將跳過該步驟的更改。但問題仍然存在尤其是在 Beta2=.999 的情況下,任何小于 5.96e-8 的梯度都可能會在較長時間內停止參數的權重更新,優化器會進入不穩定狀態。
ADAM的優點是通過使用這兩個矩,可以調整每個參數的學習率。對于較慢的學習參數,可以加快學習速度,而對于快速學習參數,可以減慢學習速度。但如果對多個步驟的梯度計算為零,即使是很小的正值也會導致模型在學習率有時間向下調整之前發散。
另外PyTorch目前還一個問題,在使用混合精度時自動將epsilon更改為1e-7,這可以幫助防止梯度移回正值時發散。但是這樣做會帶來一個新的問題,當我們知道梯度在相同的范圍內時,增加ε會降低了優化器適應學習率的能力。所以盲目的增加epsilon也不能解決由于零梯度而導致訓練停滯的情況。
CLIP訓練中的梯度縮放
為了進一步證明訓練中可能出現的不穩定性,我們在CLIP圖像模型上構建了一系列實驗。CLIP是一種基于對比學習的模型,它通過視覺轉換器和描述這些圖像的文本嵌入同時學習圖像。對比組件試圖在每批數據中將圖像匹配回原始描述。由于損失是在批次中計算的,在較大批次上的訓練已被證明能提供更好的結果。
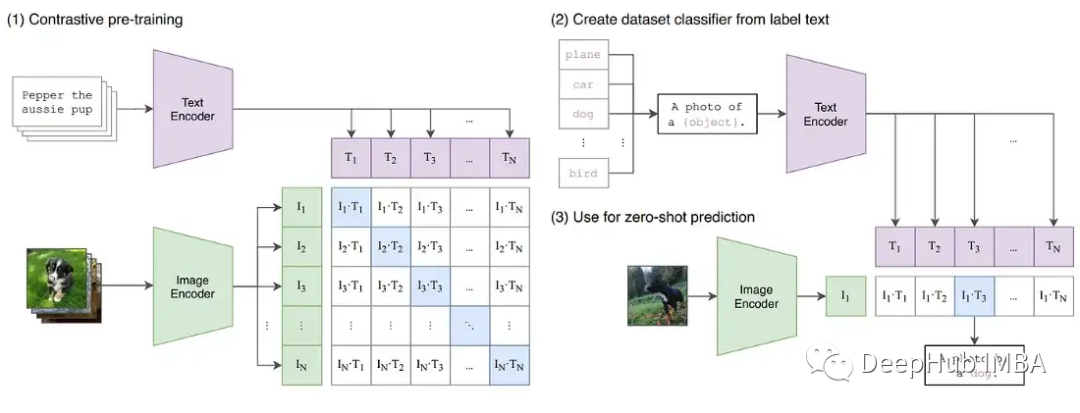
CLIP同時訓練兩個transformers模型,一個類似GPT的語言模型和一個ViT圖像模型。兩種模型的深度都為梯度增長創造了超越FP16限制的機會。OpenClip(arxiv 2212.07143)實現描述了使用FP16時的訓練不穩定性。
Tensor Collection Hook
為了更好地理解訓練期間的內部模型狀態,我們開發了一個Tensor Collection Hook (TCH)。TCH可以包裝一個模型,并定期收集關于權重、梯度、損失、輸入、輸出和優化器狀態的摘要信息。
例如,在這個實驗中,我們要找到和記錄訓練過程中的梯度條件。比如可能想每隔10步從每一層收集梯度范數、最小值、最大值、絕對值、平均值和標準差,并在 TensorBoard 中可視化結果。

然后可以用out_dir作為--logdir輸入啟動TensorBoard。

實驗
為了重現CLIP中的訓練不穩定性,用于OpenCLIP訓練Laion 50億圖像數據集的一個子集。我們用TCH包裝模型,定期保存模型梯度、權重和優化器時刻的狀態,這樣就可以觀察到不穩定發生時模型內部發生了什么。
從vvi - h -14變體開始,OpenCLIP作者描述了在訓練期間存在穩定性問題。從預訓練的檢查點開始,將學習率提高到1-e4,與CLIP訓練后半段的學習率相似。在訓練進行到300步時,有意連續引入10個難度較大的訓練批次。
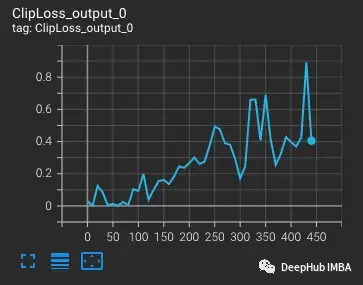
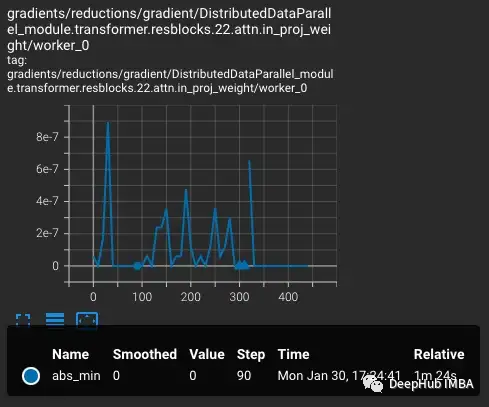
損失會隨著學習率的增加而增加,這是可預期的。當在第300步引入難度較大的情況時,損失會有一個小的,但不是很大的增加。該模型發現難度較大的情況,但沒有更新這些步驟中的大部分權重,因為nan出現在梯度中(在第二個圖中顯示為三角形)。通過這組難度較大的情況后,梯度降為零。
PyTorch梯度縮放
這里發生了什么?為什么梯度是零?問題就出在PyTorch的梯度縮放。梯度縮放是混合精度訓練中的一個重要工具。因為在具有數百萬或數十億個參數的模型中,任何一個參數的梯度都很小,并且通常低于FP16的最小范圍。
當混合精確訓練剛剛提出時,深度學習的科學家發現他們的模型在訓練早期通常會按照預期進行訓練,但最終會出現分歧。隨著訓練的進行梯度趨于變小,一些下溢的 FP16 變為零,使訓練變得不穩定。

為了解決梯度下溢,早期的技術只是簡單地將損失乘以一個固定的量,計算更大的梯度,然后將權重更新調整為相同的固定量(在混合精確訓練期間,權重仍然存儲在FP32中)。但有時這個固定的量仍然不夠。而較新的技術,如PyTorch的梯度縮放,從一個較大的乘數開始,通常是65536。但是由于這可能很高,導致大的梯度會溢出FP16值,所以梯度縮放器監視將溢出的nan梯度。如果觀察到nan,則在這一步跳過權重更新將乘數減半,然后繼續下一步。這一直持續到在梯度中沒有觀察到nan。如果在2000步中梯度縮放器沒有檢測到nan,它將嘗試使乘數加倍。
在上面的例子中,梯度縮放器完全按照預期工作。我們向它傳遞一組比預期損失更大的情況,這會產生更大的梯度導致溢出。但問題是現在的乘數很低,較小的梯度正在下降到零,梯度縮放器不監視零梯度只監視nan。
上面的例子最初看起來可能有些故意的成分,因為我們有意將困難的例子分組。但是經過數天的訓練,在大批量的情況下,產生nan的異常情況的概率肯定會增加。所以遇到足夠多的nan將梯度推至零的幾率是非常大。其實即使不引入困難的樣本,也經常會發現在幾千個訓練步驟后,梯度始終為零。
產生梯度下溢的模型
為了進一步探索問題何時發生,何時不發生,將CLIP與通常在混合精度下訓練的較小CV模型YOLOV5進行了比較。在這兩種情況下的訓練過程中跟蹤了每一層中零梯度的頻率。

在前9000步的訓練中,CLIP中5-20%的層顯示梯度下溢,而Yolo中的層僅顯示偶爾下溢。CLIP中的下溢率也隨著時間的推移而增加,使得訓練不太穩定。
使用梯度縮放并不能解決這個問題,因為CLIP范圍內的梯度幅度遠遠大于YOLO范圍內的梯度幅度。在CLIP的情況下,當梯度縮放器將較大的梯度移到FP16的最大值附近時,最小的梯度仍然低于最小值。
如何解決解CLIP中的梯度不穩定性
在某些情況下,調整梯度縮放器的參數可以幫助防止下溢。在CLIP的情況下,可以嘗試修改以一個更大的乘數開始,并縮短增加間隔。

但是我們發現乘數會立即下降以防止溢出,并迫使小梯度回到零。

改進縮放比例的一種解決方案是使其更適應參數范圍。比如論文 Adaptive Loss Scaling for Mixed Precision Training 建議按層而不是整個模型執行損失縮放,這樣可以防止下溢。而我們的實驗表明需要一種更具適應性的方法。由于 CLIP 層內的梯度仍然覆蓋整個 FP16 范圍,縮放需要適應每個單獨的參數以確保訓練穩定性。但是這種詳細的縮放需要大量內存會減少了訓練的批大小。
較新的硬件提供了更有效的解決方案。比如BFloat16 (BF16) 是另一種 16 位數據類型,它以精度換取更大的范圍。FP16 處理 5.96e-8 到 65,504,而BF16 可以處理 1.17e-38 到 3.39e38,與 FP32 的范圍相同。但是 BF16 的精度低于 FP16,會導致某些模型不收斂。但對于大型的transformers模型,BF16 并未顯示會降低收斂性。
我們運行相同的測試,插入一批困難的觀察結果,在 BF16 中,當引入困難的情況時,梯度會出現尖峰,然后返回到常規訓練,因為梯度縮放由于范圍增加而從未在梯度中觀察到 NaN。

對比FP16和BF16的CLIP,我們發現BF16中只有偶爾的梯度下溢。

在PyTorch 1.12及更高版本中,可以通過對AMP的一個小更改來啟動BF16。

如果需要更高的精度,可以試試Tensorfloat32 (TF32)數據類型。TF32由英偉達在安培GPU中引入,是一個19位浮點數,增加了BF16的額外范圍位,同時保留了FP16的精度。與FP16和BF16不同,它被設計成直接取代FP32,而不是在混合精度下啟用。要在PyTorch中啟用TF32,在訓練開始時添加兩行。

這里需要注意的是:在PyTorch 1.11之前,TF32在支持該數據類型的gpu上默認啟用。從PyTorch 1.11開始,它必須手動啟用。TF32的訓練速度比BF16和FP16慢,理論FLOPS只有FP16的一半,但仍然比FP32的訓練速度快得多。
如果你用亞馬遜的AWS:BF16和TF32在P4d、P4de、G5、Trn1和DL1實例上是可用的。
在問題發生之前解決問題
上面的例子說明了如何識別和修復FP16范圍內的限制。但這些問題往往在訓練后期才會出現。在訓練早期,模型會產生更高的損失并對異常值不太敏感,就像在OpenCLIP訓練中發生的那樣,在問題出現之前可能需要幾天的時間,這回浪費了昂貴的計算時間。
FP16和BF16都有優點和缺點。FP16的限制會導致不穩定和失速訓練。但BF16提供的精度較低,收斂性也可能較差。所以我們肯定希望在訓練早期識別易受FP16不穩定性影響的模型,這樣我們就可以在不穩定性發生之前做出明智的決定。所以再次對比那些表現出和沒有表現出后續訓練不穩定性的模型,可以發現兩個趨勢。

在FP16中訓練的YOLO模型和在BF16中訓練的CLIP模型都顯示出梯度下溢率一般小于1%,并且隨著時間的推移是穩定的。

在FP16中訓練的CLIP模型在訓練的前1000步中下溢率為5-10%,并隨著時間的推移呈現上升趨勢。
所以通過使用TCH來跟蹤梯度下溢率,能夠在訓練的前4-6小時內識別出更高梯度不穩定性的趨勢。當觀察到這種趨勢時可以切換到BF16。
總結
混合精確訓練是訓練現有大型基礎模型的重要組成部分,但需要特別注意數值穩定性。了解模型的內部狀態對于診斷模型何時遇到混合精度數據類型的限制非常重要。通過用一個TCH包裝模型,可以跟蹤參數或梯度是否接近數值極限,并在不穩定發生之前執行訓練更改,從而可能減少不成功的訓練運行天數。