網易云音樂數據全鏈路基線治理實踐

一、問題挑戰
基線治理前,我們的基線運維存在較多的問題,有兩個數字很能說明問題:
(1)月平均起夜天數達80%以上。為什么會這么多呢,有很多因素,例如運維范圍不清晰、基線掛載沒有約束、集群資源緊張等等。
(2)基線產出時間較遲,經常無法在上班前產出,月平均破線時長將近十小時。
要進行全鏈路基線治理,面臨的挑戰也很大,主要來自3方面:
- 任務多:千億級日志量,萬級任務數,如何收斂在可控的范圍,如何在出錯后,能較快的重跑完?
- 資源緊:凌晨資源水位95%以上,沒有任何的 buffer 預留,也沒有彈性資源可用;
- 要求高:顯微鏡下工作,以 MUSE 產品為例,上百 BD,每天上班就看數據,他們的 KPI 考核就以 MUSE 的數據為準。
二、目標衡量
全鏈路基線治理的價值,總結起來主要有4個方面:
- 服務于管理層,讓管理層第一時間能查看公司的經營數據。
- 面向 C 端的業務數據,能夠穩定、及時的讓用戶更友好的使用。
- 能夠建立數據開發團隊的研發口碑和影響力。
- 提升我們數據開發同學的運維幸福度,進而提升組織的穩定性。
那么我們用什么指標來衡量我們的目標呢?我們提出了兩個數字來牽引:
- 98%:全年可用天數達到98%以上,即服務不達標天數全年不超過7天。
- 基線時間:核心 SLA 基線產出時間需滿足業務要求。
三、行動方案
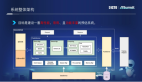
3.1 整體方案
基于上述問題挑戰的剖析,我們對該問題的解題思路拆成3個方面:
- 平臺基建:俗話說:“根基不牢,地動山搖”,首先要解決的就是平臺基建,例如如何衡量我們的集群資源是否飽和、我們的隊列如何管控、產品功能如何支持等等。
- 任務運維:全鏈路上,哪些任務是卡點?超長高耗資源任務是什么原因?哪些任務需要高保障?
- 組織流程:有沒有標準的運維 SOP ?跨團隊的協作機制如何建立?出問題后,如何有效的跟蹤以及避免再次發生?
用3個詞歸納,就是穩基建、優任務、定標準。

3.2 穩基建
基建這塊,我們梳理了存在的問題:(1)隊列使用不明確:總共拆分了幾十個隊列,沒有明確的使用規范;(2)資源監控靠經驗,無通用指標衡量;(3)集群 Namenode 壓力大,負載高;(4)資源管控弱,遇到突發情況無法保障高優任務優先獲取資源。
針對上述問題,我們實施了如下的解決方案:
- 集群穩定性建設:聯合杭研,對負載高的 Namenode 集群進行 DB 拆分,遷移上百張表;同時完善集群的監控,例如 nvme 盤夯住自動監控修復,dn/nn/hive 等節點監控優化快速發現問題。
- 集群資源數字化:實現了一個高可靠的資源使用模型,為集群資源管理員提供具體的數字化指標,以此可以快速判斷當前集群的資源使用情況,解決當前集群資源分配不合理的情況。
- 產品化:通過產品層面提升資源的使用效率,比如產品功能支持按任務優先級獲取隊列資源,產品層面實現自助分析&補數功能凌晨禁用或有限度使用。
- 隊列資源使用指導建議:制定隊列的資源使用規范,明確各個隊列的作用,管控隊列使用,規劃高中低級隊列。
3.3 優任務
針對云音樂體量大、業務多、團隊廣的數據任務特點,我們在這塊做的工作主要有:
- 核心 ETL 引入流式處理,按小時預聚合數據,這樣1小時內完成流量日任務批跑。
- 任務優化:如 hive、spark2 版本升級至 spark3 ,隊列調整、sql 改造等等。
- 打通表、任務、基線間的血緣關系,優化任務的調度時間,減少任務依賴錯漏配。
- 指標的異常監控,我們除了傳統的 dqc 外,還引入機器學習模型,解決云音樂 DAU 這類指標具有周期性、假日因素的監控難點。
其中,spark 升級得到了杭研同學的貼身服務,取得了比較好的成果,hive 升級到 spark3 完成大幾百個任務的改造,節省60%資源。spark2 升級 spark3,完成將近千個任務的改造,整體性能提升52%,文件數量減少69%。
指標的異常監控,引入的機器學習模型,我們主要融合了 Holtwinter、XGBoost 算法,相比 dqc 的監控,我們在 DAU 這個指標上,召回率提升74%,準確率提升40%,正確率提升20%;同時這里還有一個很大的作用是,它能感知業務的動態趨勢性變化,而且部署也很簡單,配置化接入。在產品層面,我們也正在聯合杭研產研同學,將該能力集成到數據質量中心。

3.4 定標準
在定標準方面,主要從兩方面出發:運維的范圍和運維規范。基于這兩點,我們展開了如下的工作:
- 以核心產品+核心報表為載體,劃定核心 SLA 運維基線+數倉中間基線,值班運維的范圍從原先的上萬個任務縮減到千級任務數。
- 明確任務責任人,解決之前事不關己高高掛起的問題,按照業務線劃分,工具+人肉并行的方式將無歸屬的任務歸屬到責任人。
- 制定基線掛載原則,明確約束條件、各角色職責等。
- 制定標準的運維 SOP ,嚴格運維軍規和獎懲機制;同時跟杭研建立數據運維交警隊,多舉措保證異常情況的及時處理。
- 建立官方運維消防群,第一時間通知問題和處理進展,解決信息傳遞不夠高效,業務體感差的問題。
- 與杭研、安全中臺、前端等達成統一意見,引入 QA 作為公正的第三方,統一牽頭處理問題的復盤和歸因,確保問題的收斂。
四、成果展示
項目成果這塊,主要分為業務成果、技術成果、產品成果三方面。
業務成果,目前我們的核心基線凌晨就能跑完,平均告警天數下降60%,核心基線破線次數0,完成全年可用天數98%以上的目標。
技術成果,我們的《機器學習模型在云音樂指標異動預測的應用實踐》榮獲了網易集團2022年度技術大會-開源引入獎。同時,我們的集群資源數字化,通過計算出合理的彈性資源,確保集群服務或者任務出現相關波動或異常的情況下,不會造成大量任務延遲、核心基線破線等現象;其次根據資源的安全水位,為擴縮容提供量化的數據指標;最后集群、隊列、任務資源透明化后,可以提高整體的資源利用率,降低成本。


產品層面,在杭研的鼎力支持下,實現了隊列資源的傾斜、自助取數自動查殺等功能,有效的提升了我們的資源利用率。
五、后續規劃
我們將從產品、系統、業務、機制四個方面繼續全鏈路基線治理的工作。
產品層面,我們將引入 DataOps,增強任務的代碼自動稽核能力,從開發、上線、審批全流程做管控。優化基線預警,通過檢測基線上任務調度時間、依賴設置等,判斷是否有優化空間或者異常,并做提示或告警。
系統層面,優化資源監控,支持基于 Label 級別展示分配的物理 CPU、虛擬 CPU、內存等系統資源總量以及指定時段的實際 CPU、虛擬 CPU、內存使用量。同時在任務級的資源使用上,對配置的資源做合理性評估,進而提供優化建議。
業務層面,提升內容級監控覆蓋率、準確度;打通線上服務的血緣,覆蓋線上服務的任務。
機制完善,聯合分析師、數據產品等團隊,確定報表、數據產品的下線以及對應歷史任務下線流程。
寫在最后,治理是一件久久為功的事情,上述更多的是從方法論的角度在講這件事,但是治理其實更考驗執行,需要不斷修煉內功,把事情做細,把細事做透。