













八種時間序列分類方法總結(jié)
對時間序列進行分類是應(yīng)用機器和深度學(xué)習(xí)模型的常見任務(wù)之一。本篇文章將涵蓋 8 種類型的時間序列分類方法。這包括從簡單的基于距離或間隔的方法到使用深度神經(jīng)網(wǎng)絡(luò)的方法。這篇文章旨在作為所有時間序列分類算法的參考文章。

時間序列定義
在涵蓋各種類型的時間序列 (TS) 分類方法之前,我們先統(tǒng)一時間序列的概念,TS 可以分為單變量或多變量 TS。
- 單變量 TS 是一組有序的(通常)實數(shù)值。
- 多變量 TS 是一組單變量 TS。每個時間戳都是一個向量或?qū)崝?shù)值數(shù)組。
單或多元TS的數(shù)據(jù)集通常包含一個單或多元TS的有序集。此外,數(shù)據(jù)集通常包含由一個單一編碼的標簽向量表示,其長度表示不同類的標簽。
TS分類的目標是通過在給定數(shù)據(jù)集上訓(xùn)練任何分類模型來定義的,這樣模型就可以學(xué)習(xí)所提供數(shù)據(jù)集的概率分布。也就是說當給定TS時,模型應(yīng)該學(xué)會正確地分配類標簽。
基于距離的方法
基于距離或最近鄰的 TS 分類方法使用各種基于距離的度量來對給定數(shù)據(jù)進行分類。它是一種監(jiān)督學(xué)習(xí)技術(shù),其中新 TS 的預(yù)測結(jié)果取決于與其最相似的已知時間序列的標簽信息。
距離度量是描述兩個或多個時間序列之間距離的函數(shù),它是決定性的。典型的距離度量是:
- p 范數(shù)(如曼哈頓距離、歐幾里德距離等)
- 動態(tài)時間規(guī)整 (DTW)
決定度量后,通常應(yīng)用 k 最近鄰 (KNN) 算法,該算法測量新 TS 與訓(xùn)練數(shù)據(jù)集中所有 TS 之間的距離。計算完所有距離后,選擇最近的 k 個。最后新的 TS 被分配到 k 個最近鄰居中的大多數(shù)所屬的類別。
雖然最流行的范數(shù)肯定是 p 范數(shù),尤其是歐幾里德距離,但它們有兩個主要缺點,使它們不太適合 TS 分類任務(wù)。因為范數(shù)僅針對相同長度的兩個 TS 定義,實際上并不總是能夠得到長度相等的序列。范數(shù)僅獨立比較每個時間點的兩個 TS 值,但是大多數(shù) TS 值相互關(guān)聯(lián)。
而DTW 可以解決 p 范數(shù)的兩個限制。經(jīng)典的 DTW 可以最小化時間戳可能不同的兩個時間序列點之間的距離。這意味著輕微偏移或扭曲的 TS 仍然被認為是相似的。下圖可視化了基于 p 范數(shù)的度量與 DTW 的工作方式之間的差異。

結(jié)合KNN,將DTW作為基準基準算法,用于TS分類的各種基準評估。
KNN也可以有決策樹的方法實現(xiàn)。例如,鄰近森林算法建模了一個決策樹森林,使用距離度量來劃分TS數(shù)據(jù)。
基于區(qū)間和頻率的方法
基于區(qū)間的方法通常將TS分割為多個不同的區(qū)間。然后使用每個子序列來訓(xùn)練一個單獨的機器學(xué)習(xí)(ML)分類器。會生成一個分類器集合,每個分類器都作用于自己的區(qū)間。在單獨分類的子序列中計算最常見的類將返回整個時間序列的最終標簽。
時間序列森林
基于區(qū)間的模型最著名的代表是時間序列森林(Time Series Forest)。TSF 是建立在初始 TS 的隨機子序列上的決策樹的集合。每棵樹負責將一個類分配給一個區(qū)間。
這是通過計算匯總特征(通常是均值、標準差和斜率)來為每個間隔創(chuàng)建特征向量來完成的。之后根據(jù)計算出的特征訓(xùn)練決策樹,并通過所有樹的多數(shù)投票獲得預(yù)測。投票過程是必需的,因為每棵樹只評估初始 TS 的某個子序列。
除了 TSF 之外,還有其他基于區(qū)間的模型。TSF 的變體使用附加特征,例如子序列的中值、四分位數(shù)間距、最小值和最大值。與經(jīng)典的 TSF 算法相比,還存在一種相當復(fù)雜的算法,稱為 Random Interval Spectral Ensemble (RISE)算法。
RISE
RISE 算法在兩個方面有別于經(jīng)典的 TS 森林。
- 每棵樹使用單個 TS 間隔
- 它是通過使用從 TS 中提取的光譜特征來訓(xùn)練的(而不是使用匯總統(tǒng)計數(shù)據(jù)作為均值、斜率等)
在 RISE 技術(shù)中,每個決策樹都建立在一組不同的傅里葉、自相關(guān)、自回歸和部分自相關(guān)特征之上。該算法按如下方式工作:
選擇 TS 的第一個隨機區(qū)間,并在這些區(qū)間上計算上述特征。然后通過組合提取的特征創(chuàng)建一個新的訓(xùn)練集。在這些基礎(chǔ)上,訓(xùn)練決策樹分類器。最后使用不同的配置重復(fù)這些步驟以創(chuàng)建集成模型,該模型是單個決策樹分類器的隨機森林。
基于字典的方法
基于字典的算法是另一類TS分類器,它基于字典的結(jié)構(gòu)。它們涵蓋了大量不同的分類器,有時可以與上述分類器結(jié)合使用。
這里是涵蓋的基于字典的方法列表:
- Bag-of-Patterns (BOP)
- Symbolic Fourier Approximation (SFA)
- Individual BOSS
- BOSS Ensemble
- BOSS in Vector Space
- contractable BOSS
- Randomized BOSS
- WEASEL
這類的方法通常首先將 TS 轉(zhuǎn)換為符號序列,通過滑動窗口從中提取“WORDS”。然后通過確定“WORDS”的分布來進行最終分類,這通常是通過對“WORDS”進行計數(shù)和排序來完成的。這種方法背后的理論是時間序列是相似的,這意味著如果它們包含相似的“WORDS”則屬于同一類。基于字典的分類器主要過程通常是相同的。
- 在 TS 上運行特定長度的滑動窗口
- 將每個子序列轉(zhuǎn)換為一個“WORDS”(具有特定長度和一組固定字母)
- 創(chuàng)建這些直方圖
下面是最流行的基于字典的分類器的列表:
Bag-of-Patterns算法
模式袋(Bag-of-Patterns, BOP)算法的工作原理類似于用于文本數(shù)據(jù)分類的詞袋算法。這個算法計算一個單詞出現(xiàn)的次數(shù)。
從數(shù)字(此處為原始 TS)創(chuàng)建單詞的最常見技術(shù)稱為符號聚合近似 (SAX)。首先將 TS 劃分為不同的塊,每個塊之后都會標準化,這意味著它的均值為 0,標準差為 1。
通常一個詞的長度比子序列中實數(shù)值的數(shù)量要長。因此,進一步對每個塊應(yīng)用分箱。然后計算每個分箱的平均實際值,然后將其映射到一個字母。例如,對于所有低于 -1 的平均值,分配字母“a”,所有大于 -1 和小于 1 的值“b”,所有高于 1 的值“c”。下圖形象化了這個過程。
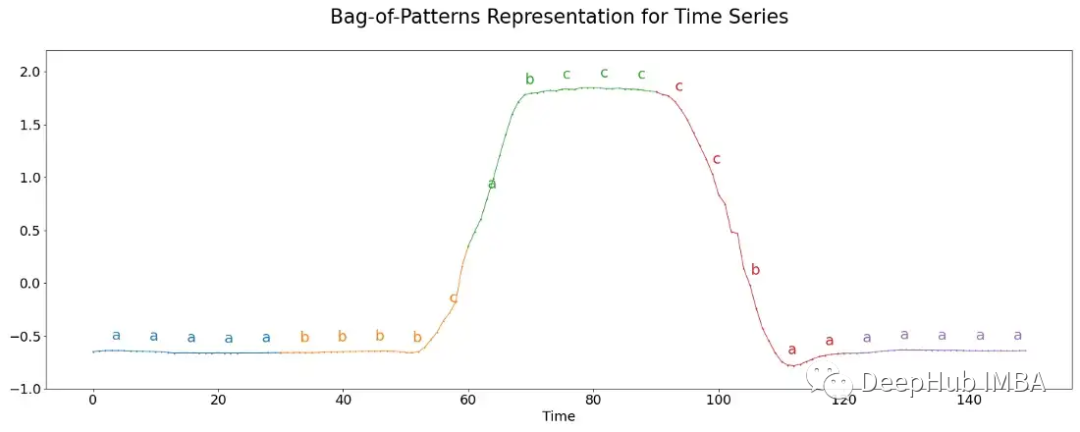
這里每個段包含 30 個值,這些值被分成 6 個一組,每個組被分配三個可能的字母,構(gòu)成一個五個字母的單詞。最后匯總每個詞的出現(xiàn)次數(shù),并通過將它們插入最近鄰算法來用于分類。
Symbolic Fourier Approximation
與上述 BOP 算法的思想相反,在 BOP 算法中,原始 TS 被離散化為字母然后是單詞,可以對 TS 的傅里葉系數(shù)應(yīng)用類似的方法。
最著名的算法是Symbolic Fourier Approximation (SFA),它又可以分為兩部分。
計算 TS 的離散傅立葉變換,同時保留計算系數(shù)的子集。
- 監(jiān)督:單變量特征選擇用于根據(jù)統(tǒng)計數(shù)據(jù)(如 F 統(tǒng)計量或 χ2 統(tǒng)計量)選擇排名較高的系數(shù)
- 無監(jiān)督:通常取第一個系數(shù)的子集,代表TS的趨勢
結(jié)果矩陣的每一列都被獨立離散化,將 TS 的 TS 子序列轉(zhuǎn)換為單個單詞。
- 監(jiān)督:計算分箱邊緣,使得實例熵的雜質(zhì)標準最小化。
- 無監(jiān)督:計算分箱邊緣,使其基于傅立葉系數(shù)的極值(分箱是統(tǒng)一的)或基于這些的分位數(shù)(每個分箱中的系數(shù)數(shù)量相同)
基于上面的預(yù)處理,可以使用各種不同算法,進一步處理信息以獲得 TS 的預(yù)測。
BOSS
Bag-of-SFA-Symbols (BOSS) 算法的工作原理如下:
- 通過滑動窗口機制提取 TS 的子序列
- 在每個片段上應(yīng)用 SFA 轉(zhuǎn)換,返回一組有序的單詞
- 計算每個單詞的頻率,這會產(chǎn)生 TS 單詞的直方圖
- 通過應(yīng)用 KNN 等算法結(jié)合自定義 BOSS 度量(歐氏距離的微小變化)進行分類。
BOSS算法的變體包含很多變體:
BOSS Ensemble
BOSS Ensemble算法經(jīng)常用于構(gòu)建多個單個 BOSS 模型,每個模型在參數(shù)方面各不相同:字長、字母表大小和窗口大小。通過這些配置捕捉各種不同長度的圖案。通過對參數(shù)進行網(wǎng)格搜索并僅保留最佳分類器來獲得大量模型。
BOSS in Vector Space
BOSS in Vector Space (BOSSVS) 算法是使用向量空間模型的個體 BOSS 方法的變體,該方法為每個類計算一個直方圖,并計算詞頻-逆文檔頻率 (TF-IDF) 矩陣。然后通過找到每個類的TF-IDF向量與TS本身的直方圖之間余弦相似度最高的類,得到分類。
Contractable BOSS
Contractable BOSS(cBOSS) 算法比經(jīng)典的 BOSS 方法在計算上快得多。
通過不對整個參數(shù)空間進行網(wǎng)格搜索而是對從中隨機選擇的樣本進行網(wǎng)格搜索來實現(xiàn)加速的。cBOSS 為每個基本分類器使用數(shù)據(jù)的子樣本。cBOSS 通過僅考慮固定數(shù)量的最佳基分類器而不是高于特定性能閾值的所有分類器來提高內(nèi)存效率。
Randomized BOSS
BOSS 算法的下一個變體是Randomized BOSS (RBOSS)。該方法在滑動窗口長度的選擇中添加了一個隨機過程,并巧妙地聚合各個 BOSS 分類器的預(yù)測。這類似于 cBOSS 變體,減少了計算時間,同時仍保持基準性能。
WEASE
通過在 SFA 轉(zhuǎn)換中使用不同長度的滑動窗口,TS 分類詞提取 (WEASEL) 算法可以提高標準 BOSS 方法的性能。與其他 BOSS 變體類似,它使用各種長度的窗口大小將 TS 轉(zhuǎn)換為特征向量,然后由 KNN 分類器對其進行評估。
WEASEL 使用特定的特征推導(dǎo)方法,通過僅使用應(yīng)用 χ2 檢驗的每個滑動窗口的非重疊子序列進行,過濾掉最相關(guān)的特征。
將 WEASEL 與Multivariate Unsupervised Symbols(WEASEL+MUSE)相結(jié)合,通過將上下文信息編碼到每個特征中從 TS 中提取和過濾多元特征。
基于 Shapelet 的方法
基于shapelets的方法使用初始時間序列的子序列(即shapelets)的思想。選擇shapelets是為了將它們用作類的代表,這意味著shapelets包含類的主要特征,這些特征可用于區(qū)分不同的類。在最優(yōu)的情況下,它們可以檢測到同一類內(nèi)TS之間的局部相似性。
下圖給出了一個shapelet的示例。它只是整個TS的子序列。

使用基于shapelets的算法需要確定使用哪個shapelets的問題。可以通過手工制作一組shapelets來選擇,但這可能非常困難。也可以使用各種算法自動選擇shapelets。
基于Shapelet提取的算法
Shapelet Transform是由Lines等人提出的一種基于Shapelet提取的算法,是目前最常用的算法之一。給定n個實值觀測值的TS, shapelet由長度為l的TS的子集定義。
shapelet和整個TS之間的最小距離可以使用歐幾里德距離-或任何其他距離度量- shapelet本身和從TS開始的所有長度為l的shapelets之間的距離。
然后算法選出k個長度屬于一定范圍的最佳shapelets。這一步可以被視為某種單變量特征提取,每個特征都由給定數(shù)據(jù)集中shapelet與所有TS之間的距離定義。然后根據(jù)一些統(tǒng)計數(shù)據(jù)對shapelets進行排名。這些通常是f統(tǒng)計量或χ2統(tǒng)計量,根據(jù)它們區(qū)分類的能力對shapelets進行排序。
完成上述步驟后,可以應(yīng)用任何類型的ML算法對新數(shù)據(jù)集進行分類。例如基于knn的分類器、支持向量機或隨機森林等等。
尋找理想的shapelets的另一個問題是可怕的時間復(fù)雜性,它會隨著訓(xùn)練樣本的數(shù)量成倍增加。
基于 Shapelet學(xué)習(xí)的算法
基于 Shapelet 學(xué)習(xí)的算法試圖解決基于 Shapelet 提取的算法的局限性。這個想法是學(xué)習(xí)一組能夠區(qū)分類的 shapelet,而不是直接從給定的數(shù)據(jù)集中提取它們。
這樣做有兩個主要優(yōu)點:
- 它可以獲得不包含在訓(xùn)練集中但對類別具有強烈辨別力的 shapelet。
- 不需要在整個數(shù)據(jù)集上運行算法,這可以顯著減少訓(xùn)練時間
但是這種方法也有一些使用可微分最小化函數(shù)和選擇的分類器引起的缺點。
要想代替歐幾里德距離,我們必須依賴可微分函數(shù),這樣可以通過梯度下降或反向傳播算法來學(xué)習(xí) shapelet。最常見的依賴于 LogSumExp 函數(shù),該函數(shù)通過取其參數(shù)的指數(shù)之和的對數(shù)來平滑地逼近最大值。由于 LogSumExp 函數(shù)不是嚴格凸函數(shù),因此優(yōu)化算法可能無法正確收斂,這意味著它可能導(dǎo)致糟糕的局部最小值。
并且由于優(yōu)化過程本身是算法的主要組成部分,所以還需要添加多個超參數(shù)進行調(diào)優(yōu)。
但是該方法在實踐中非常有用,可以對數(shù)據(jù)產(chǎn)生一些新的見解。
基于核的方法
基于 shapelet 的算法的一個細微變化是基于核的算法。學(xué)習(xí)和使用隨機卷積核(最常見的計算機視覺算法),它從給定的 TS 中提取特征。
隨機卷積核變換 (ROCKET) 算法是專門為此目的而設(shè)計的。。它使用了大量的內(nèi)核,這些內(nèi)核在長度、權(quán)重、偏置、膨脹和填充方面都不同,并且是從固定的分布中隨機創(chuàng)建的。
在選擇內(nèi)核后,還需要一個能夠選擇最相關(guān)的特征來區(qū)分類的分類器。原始論文中使用嶺回歸(線性回歸的 L2 正則化變體)來執(zhí)行預(yù)測。使用它有兩個好處,首先是它的計算效率,即使對于多類分類問題也是如此,其次是使用交叉驗證微調(diào)唯一的正則化超參數(shù)的非常的簡單。
使用基于核的算法或 ROCKET 算法的核心優(yōu)勢之一是使用它們的計算成本相當?shù)汀?/p>
基于特征的方法
基于特征的方法一般可以涵蓋大多數(shù)算法,這些算法對給定的時間序列使用某種特征提取,然后由分類算法執(zhí)行預(yù)測。
關(guān)于特征,從簡單的統(tǒng)計特征到更復(fù)雜的基于傅里葉的特征。在hctsa(https://github.com/benfulcher/hctsa)中可以找到大量這樣的特性,但是嘗試和比較每個特性可能是一項無法完成的任務(wù),特別是對于較大的數(shù)據(jù)集。所以提出了典型時間序列特征(catch22)算法被提出了。
catch22算法
該方法旨在推斷一個小的TS特征集,不僅需要強大的分類性能,而且還可以進一步最小化冗余。catch22從hctsa庫中總共選擇了22個特性(該庫提供了4000多個特性)。
該方法的開發(fā)人員通過在93個不同的數(shù)據(jù)集上訓(xùn)練不同的模型來獲得22個特征,并評估其上表現(xiàn)最好的TS特征,得到了一個仍然保持出色性能的小子集。其上的分類器可以自由選擇,這使得它成為另一個超參數(shù)來進行調(diào)優(yōu)。
Matrix Profile Classifier
另一種基于特征的方法是 Matrix Profile (MP) 分類器,它是一種基于 MP 的可解釋 TS 分類器,可以在保持基準性能的同時提供可解釋的結(jié)果。
設(shè)計人員從基于shapelet的分類器中提取了名為Matrix Profile模型的。該模型表示 TS 的子序列與其最近鄰居之間的所有距離。這樣,MP 就能夠有效地提取 TS 的特征,例如motif和discord,motif 是 TS 的彼此非常相似的子序列,而discords 描述彼此不同的序列。
作為理論上的分類模型,任何模型都可以使用。這種方法的開發(fā)者選擇了決策樹分類器。
除了這兩種提到的方法之外,sktime 還提供了一些更基于特征的 TS 分類器。
模型集成
模型集成本身不是一種獨立的算法,而是一種組合各種 TS 分類器以創(chuàng)建更好組合預(yù)測的技術(shù)。模型集成通過組合多個單獨的模型來減少方差,類似于使用大量決策樹的隨機森林。并且使用各種類型的不同學(xué)習(xí)算法會導(dǎo)致更廣泛和更多樣化的學(xué)習(xí)特征集,這反過來會獲得更好的類別辨別力。
最受歡迎的模型集成是 Hierarchical Vote Collective of Transformation-based Ensembles (HIVE-COTE)。它存在許多不同種類的相似版本,但它們的共同點是通過對每個分類器使用加權(quán)平均值來組合不同分類器的信息,即預(yù)測。
Sktime 使用兩種不同的 HIVE-COTE 算法,其中第一種結(jié)合了每個估計器的概率,其中包括一個 shapelet 變換分類器 (STC)、一個 TS 森林、一個 RISE 和一個 cBOSS。第二個由 STC、Diverse Canonical Interval Forest Classifier(DrCIF,TS 森林的變體)、Arsenal(ROCKET 模型的集合)和 TDE(BOSS 算法的變體)的組合定義。
最終的預(yù)測是由 CAWPE 算法獲得的,該算法為每個分類器分配權(quán)重,這些權(quán)重是通過在訓(xùn)練數(shù)據(jù)集上找到的分類器的相對估計質(zhì)量獲得的。
下圖是用于可視化 HIVE-COTE 算法工作結(jié)構(gòu)的常用圖示:

基于深度學(xué)習(xí)的方法
關(guān)于基于深度學(xué)習(xí)的算法,可以自己寫一篇很長的文章來解釋有關(guān)每種架構(gòu)的所有細節(jié)。但是本文只提供一些常用的 TS 分類基準模型和技術(shù)。
雖然基于深度學(xué)習(xí)的算法在計算機視覺和 NLP 等領(lǐng)域非常流行并得到廣泛研究,但它們在 TS 分類領(lǐng)域卻并不常見。Fawaz 等人。在他們關(guān)于 TS 分類的深度學(xué)習(xí)的論文中對當前現(xiàn)有方法的詳盡研究:總結(jié)研究了具有六種架構(gòu)的 60 多個神經(jīng)網(wǎng)絡(luò) (NN) 模型:
- Multi-Layer Perceptron
- Fully Convolutional NN (CNN)
- Echo-State Networks (based on Recurrent NNs)
- Encoder
- Multi-Scale Deep CNN
- Time CNN
上述大多數(shù)模型最初是為不同的用例開發(fā)的。所以需要根據(jù)不同的用例進行測試。
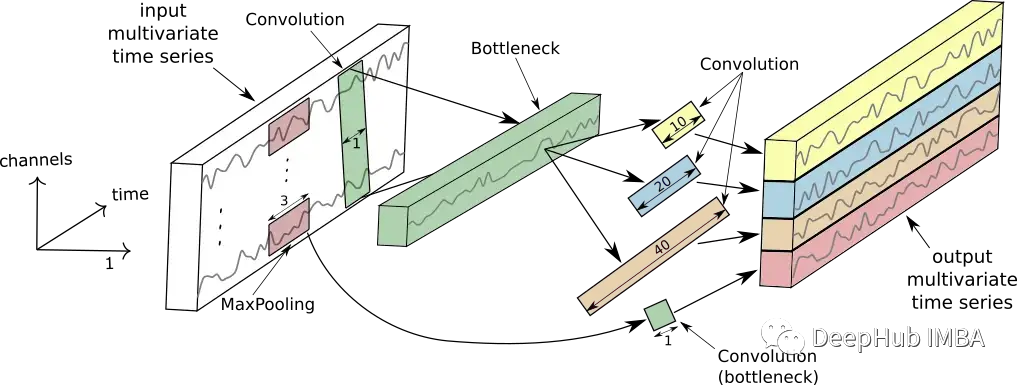
在2020 年還發(fā)布了 InceptionTime 網(wǎng)絡(luò)。InceptionTime 是五個深度學(xué)習(xí)模型進行的集成,其中每個模型都是由 Szegedy 等人首先提出的InceptionTime創(chuàng)建的。這些初始模塊同時將多個不同長度的過濾器應(yīng)用于 TS,同時從 TS 的較短和較長子序列中提取相關(guān)特征和信息。下圖顯示了 InceptionTime 模塊。

它由多個以前饋方式堆疊的初始模塊組成,并與殘差連接。最后是全局平均池化和全連接神經(jīng)網(wǎng)絡(luò)生成預(yù)測結(jié)果。
下圖顯示了單個初始模塊的工作情況。
總結(jié)
本文總結(jié)的大量的算法、模型和技術(shù)列表不僅能幫助理解時間序列分類方法的廣闊領(lǐng)域,希望對你有所幫助

























