Kafka的替代者Redpanda的架構及部署

介紹
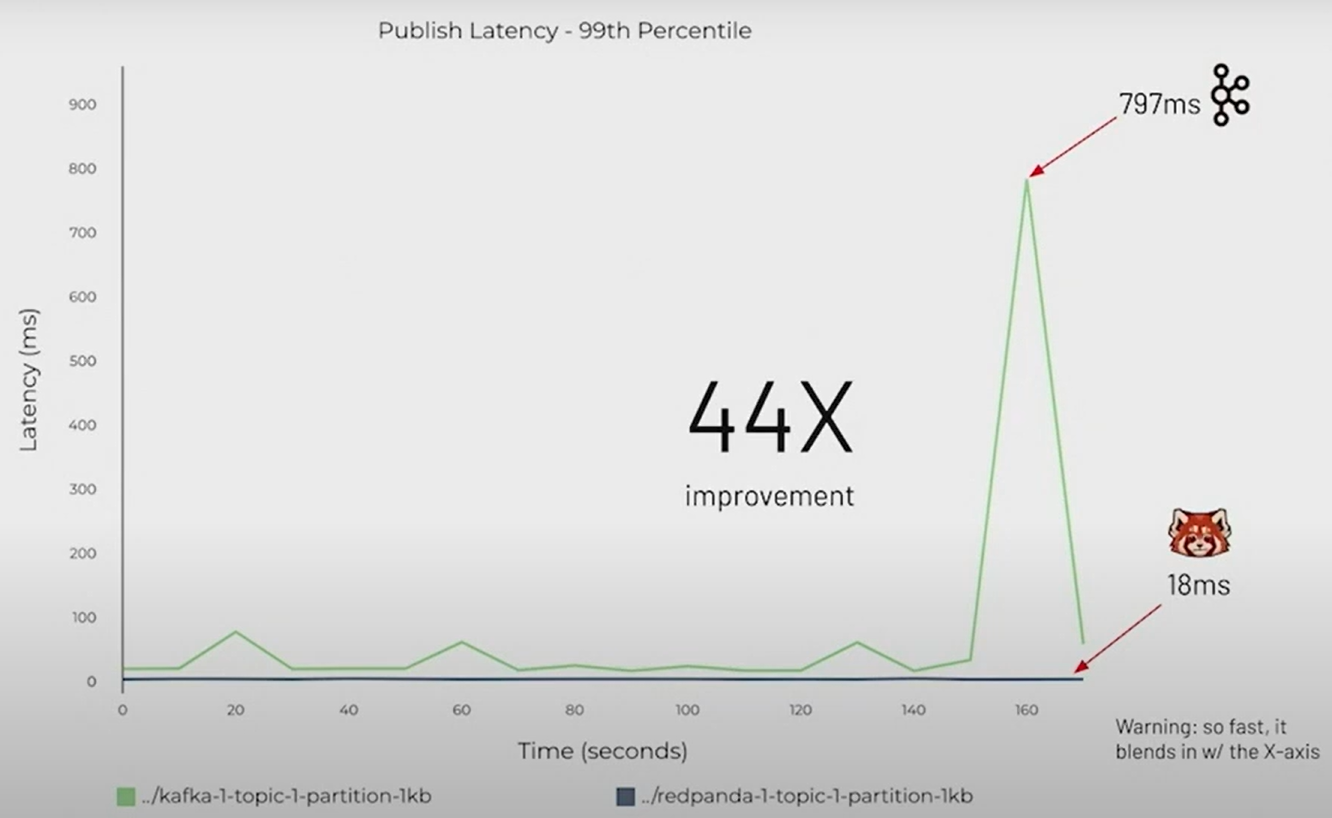
Redpanda 使用C++編寫,是一個與 Kafka兼容的流數據平臺,事實證明它的速度提高了10 倍。它還不含 JVM、不含 ZooKeeper、經過 Jepsen 測試且源代碼可用。
Redpanda完全兼容KafkaAPI,也就是說,開發項目中不需要修改kafka客戶端相關的代碼,可以直接替換掉kafka。
因為是C++編寫,所以無需使用JVM,分布式協調使用raft協議,所以也無需使用zookeeper。只有一個可執行二進制文件,部署非常方便。
架構
最近十年計算機硬件發生了不少變化:

硬盤由于NVMe協議的SSD,快了1000倍;網絡快了100倍;云計算更加便宜;但是CPU速度增長不多,所以通過多核的辦法來解決。從這個趨勢來看,CPU似乎成了新的瓶頸。
在這種背景下,Redpanda為了適應現代計算機硬件的發展,設計了自己的架構:
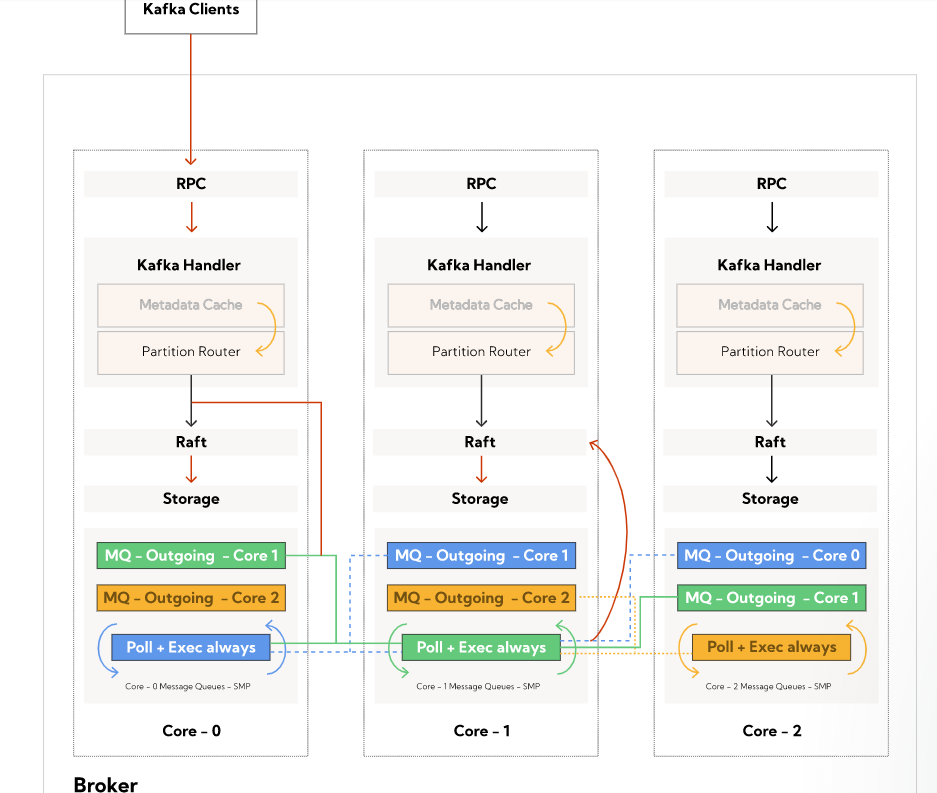
這種架構稱為Thread-Per-Core。上面提到,現代計算機有很多個核心。為了充分利用多核,就需要用到線程。但是線程會遇到兩個主要的問題:1、在一些需要同步的時候必須用到lock,2、Context Switch成本較高。
而Thread-Per-Core架構就是為了解決這兩個主要的問題,有幾個core就建幾個thread,而且將thread綁定到特定的core上,因為不會有更多的thread,所以盡可能的減少了context switch。另外,Redpanda的每一個thread只負責處理各自的partition,所以也不需要用到lock。你可能會想,那I/O怎么處理?阻塞了thread怎么辦?在linux 5.1版本內核以后,增加了一個完全異步的io模型——io_uring
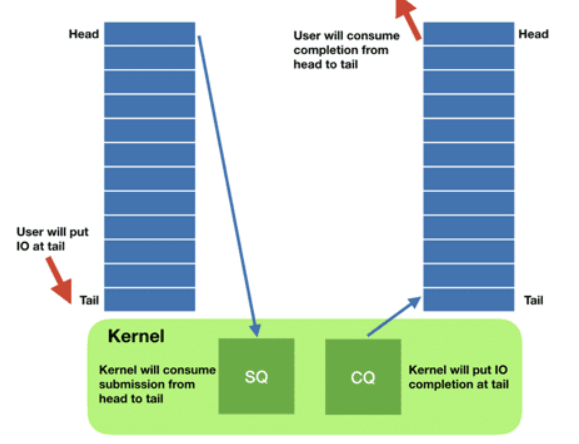
io_uring使用用戶空間建立的兩個queue:sq(submit queue)和cq(complete queue)來完成io操作。read和write操作放入sq,這一步是異步的,然后應用程序可以去做別的事情,待kernel完成工作后,就將結果放入cq,應用程序需要檢查io結果的時候就去cq中查即可。在這種模式下,因為有sq的存在,所以相當于系統調用是批量的,也就是內核處理io是批量的。這樣也就充分利用了現代硬件的優勢,比如NVMe的SSD硬盤,可以并行處理很多IO操作。
Redpanda的kafka client發送消息到Redpanda,其實是發送到了某一core上,當這個core不負責某個partition時,就會通過rpc通知到其他core上的thread進行處理。在這里Redpanda并不使用grpc或者thrift,而是使用自己實現的輕量級rpc來達到完美的速度。當有多個Redpanda節點時,使用raft協議進行數據共識。
綜上,Redpanda達到了3個目的:
- 操作簡單。只有一個二進制可執行文件,部署簡單,無需jvm、zk。
- 盡可能的零數據丟失。使用raft協議保障數據安全。
- 實測比kafka快10倍。Thread-Per-Core架構和io_uring的加持,使得其比kafka更快。
部署
Redpanda可以部署到docker、linux、win、macOS、kubernetes上。當直接安裝到docker、linux、win、macOS上的時候,在安裝完,如果需要非本機訪問的話,需要在參數中配置advertising地址和端口,這樣才能在外部訪問
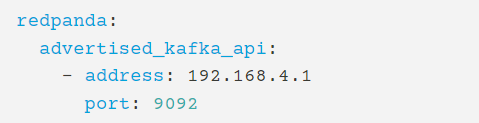
下面說下kubernetes部署。
https://github.com/redpanda-data/helm-charts
在這個地址下載helm chart,然后進去找到values.yaml,主要需要修改的是storage這個地方:
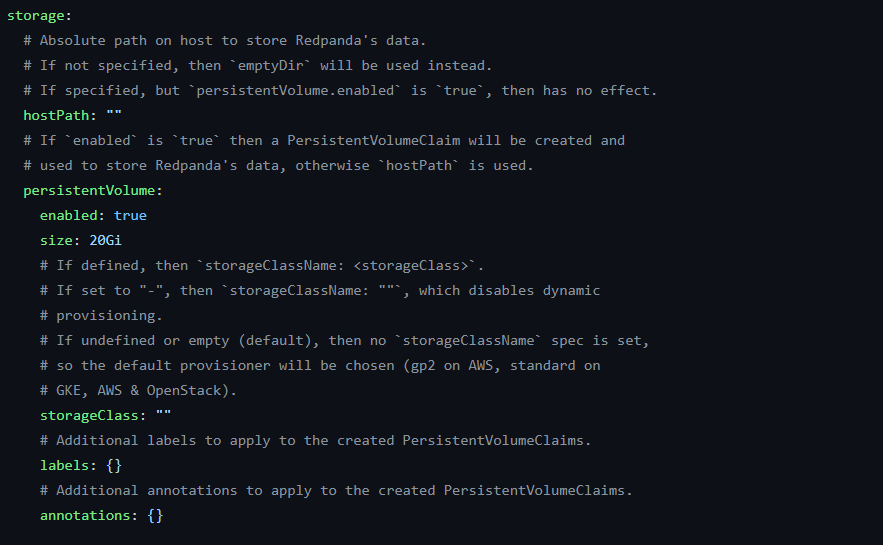
修改成合適的storageClass,選擇好空間大小,然后執行:
即可安裝成功。