圖數(shù)據(jù)庫的發(fā)展脈絡與技術演進

導讀:本文由香港中文大學James Cheng教授團隊貢獻,James Cheng教授長期從事分布式系統(tǒng)、分布式計算、圖計算與圖數(shù)據(jù)管理等方向的研究工作。曾與阿里巴巴、華為、騰訊、字節(jié)跳動等多家公司在大數(shù)據(jù)計算系統(tǒng)、存儲系統(tǒng)、調度系統(tǒng)、深度學習系統(tǒng)等方向上展開項目合作,曾獲得香港青年科學家稱號,ATC'21最佳論文獎。
接下來,大家一起來了解下圖數(shù)據(jù)庫技術發(fā)展的前世今生吧:
一、背景介紹
圖(Graph)是一種由點(Vertex)和邊(Edge)及其屬性(Property)構成的通用數(shù)據(jù)結構,以表達自然世界中實體間的關聯(lián)關系,被廣泛應用于知識圖譜、社交網(wǎng)絡、金融網(wǎng)絡、生物蛋白質分析等各種垂直領域。隨著各行各業(yè)生產(chǎn)的數(shù)據(jù)規(guī)模增長,大規(guī)模圖數(shù)據(jù)管理在近十年來受到了越來越多的重視,圖數(shù)據(jù)庫系統(tǒng)也正在被廣泛的開發(fā)和研究,以實現(xiàn)高效的圖狀數(shù)據(jù)存儲和查詢。為了存儲圖數(shù)據(jù),一些圖數(shù)據(jù)庫利用傳統(tǒng)的數(shù)據(jù)庫模型(如關系型數(shù)據(jù)庫,文檔數(shù)據(jù)庫,列存數(shù)據(jù)庫)來轉換圖數(shù)據(jù);而還有一些圖原生的數(shù)據(jù)庫(比如Neo4j、TigerGraph等),則專門為圖數(shù)據(jù)結構設計了高效的存儲格式。
與傳統(tǒng)數(shù)據(jù)庫相比,圖數(shù)據(jù)庫的本質區(qū)別在于可以更高效的存儲和查詢圖數(shù)據(jù)。不同的存儲模型導致了不同的查詢執(zhí)行策略和對圖的具體操作行為,這將最終導致各種性能。例如,在原生的圖數(shù)據(jù)庫中,可以通過掃描無索引的鄰接列表來執(zhí)行遍歷操作,在基于關系型表而設計的圖數(shù)據(jù)庫中,則需要通過對多個表的Join操作來執(zhí)行。隨著遍歷跳數(shù)的增加,對于冪律分布的圖數(shù)據(jù)來說,用于Join的表的大小可能呈指數(shù)級增長,這將導致嚴重的性能瓶頸。而另一方面,關聯(lián)型的數(shù)據(jù)以Table的形式存儲在關系型數(shù)據(jù)庫中,可以實現(xiàn)更好的數(shù)據(jù)平衡和定位。對于一些原生的圖數(shù)據(jù)庫來說,由于圖結構的不規(guī)則性,不規(guī)則的數(shù)據(jù)模式導致了較差的數(shù)據(jù)局部性,并為數(shù)據(jù)檢索帶來了額外的開銷。
本文將梳理圖數(shù)據(jù)庫發(fā)展的歷史脈絡與技術演進,并簡單討論筆者認為圖數(shù)據(jù)庫今后的發(fā)展方向。
二、圖數(shù)據(jù)庫的發(fā)展歷史
從Google分別于2003、2004、2006年在SOSP'03、OSDI'04、OSDI'06發(fā)表經(jīng)典三駕馬車(GFS,MapReduce,BigTable)論文開始,以Hadoop開源生態(tài)為中心的大數(shù)據(jù)體系得到了蓬勃的發(fā)展,數(shù)據(jù)模型逐步由以表(Table)的主流形式來存儲和查詢關系型數(shù)據(jù)慢慢發(fā)展到以鍵值、寬列、文檔、圖等各種形式來存儲和查詢海量數(shù)據(jù)的NoSQL體系。
日益膨脹和快速發(fā)展的各類應用所產(chǎn)生的數(shù)據(jù)使得NoSQL體系對數(shù)據(jù)存儲與查詢的要求變得多種多樣:高吞吐、高可用、低時延、強一致等等。因此在大數(shù)據(jù)時代下,各類組件百花齊放,迭代升級也非常迅速。圖數(shù)據(jù)存儲作為NoSQL體系中的一種數(shù)據(jù)建模方式,主要用以表達現(xiàn)實世界中實體間的關聯(lián)關系;圖數(shù)據(jù)庫則是與之對應的存儲系統(tǒng),用以存儲和管理(增刪改查)圖狀數(shù)據(jù)。
圖數(shù)據(jù)庫是一種非關系型數(shù)據(jù)庫,以解決現(xiàn)有關系數(shù)據(jù)庫的局限性。圖模型明確地列出了數(shù)據(jù)節(jié)點之間的依賴關系,而關系模型和其他NoSQL數(shù)據(jù)庫模型則通過隱式連接來鏈接數(shù)據(jù)。圖數(shù)據(jù)庫從設計上,就是可以簡單快速地檢索難以在關系系統(tǒng)中建模的復雜層次結構的。圖數(shù)據(jù)庫的底層存儲機制可能各有不同。有些依賴于關系引擎并將圖數(shù)據(jù)“存儲”到表中(雖然表是一個邏輯元素,但是這種方法在圖數(shù)據(jù)庫、圖數(shù)據(jù)庫管理系統(tǒng)和實際存儲數(shù)據(jù)的物理設備之間施加了另一層抽象)。另一些則使用鍵值存儲或文件導向的數(shù)據(jù)庫進行存儲,使它們具有固有的NoSQL結構。大多數(shù)基于非關系存儲引擎的圖數(shù)據(jù)庫還添加了標記或屬性的概念,這些標記或屬性本質上是具有指向另一個文檔的指針的關系。這樣就可以對數(shù)據(jù)元素進行分類,以便于集中檢索。

圖片來源自:https://k21academy.com/dba-to-cloud-dba/nosql-database-service-in-oracle-cloud/
從大約2010年開始,各種構建于NoSQL體系或者關系型數(shù)據(jù)庫之上的圖數(shù)據(jù)庫便涌現(xiàn)而出,比如:Titan, JanusGraph, RedisGraph, Sparksee, AgensGraph, OrientDB 等等, 當然同一時間也出現(xiàn)了Neo4j這種為圖數(shù)據(jù)而專門設計的圖原生存儲數(shù)據(jù)庫,其現(xiàn)今已經(jīng)發(fā)展成為了圖數(shù)據(jù)庫領域商業(yè)化的領頭羊。我們下面將根據(jù)存儲模型的不同對這些圖數(shù)據(jù)庫做一個簡單的歸類和討論。但由于篇幅有限,詳細的分析和性能對比不會在本文展開,我們今后將會在arXiv上提交一篇Experimental Track的學術論文來系統(tǒng)性地分析這些圖數(shù)據(jù)庫的設計方案和性能測試報告。
1、圖數(shù)據(jù)庫的存儲設計?
如何存儲圖數(shù)據(jù)以實現(xiàn)高效查詢和更新是圖數(shù)據(jù)庫的一個重要問題。對于一個圖模型G,應該考慮的存儲數(shù)據(jù)包括點(V)、邊(E)、頂點屬性(VP)和邊屬性(EP)。一個圖通常又可以用三種常見的方法來表示:鄰接表、鄰接矩陣和邊列表。鄰接表通常將一個頂點的所有鄰居作為一個數(shù)組來存儲。因此,一條邊從兩個方向上會出現(xiàn)在兩個不同頂點的鄰接表中。鄰接矩陣選擇用一個矩陣來表示兩個頂點之間是否有一條邊,而邊表會獨立存儲所有的邊集合,并使用指針讓每個頂點記錄它與自己鄰居的關系。
2、圖原生數(shù)據(jù)庫
(1)Neo4j
Neo4j定制化的分別將四種對象(即點、邊、點屬性和邊屬性)作為記錄來存儲,并利用指針將它們連接起來。圖1展示了Neo4j如何在物理存儲上組織所有對象。一個頂點/邊的所有屬性都以鏈表的形式連接起來,其頭部由相關頂點/邊的實例的指針指向。與屬性類似,一個頂點所有相鄰的邊也被連接在一起,但用雙鏈接列表來呈現(xiàn)。每個邊的實例將只存儲一次,但由兩個鄰接表連接。因此,要找到邊的實例,唯一的方法就是遍歷頂點上的雙向鏈表,這就會產(chǎn)生對邊集的掃描開銷。然而,Neo4j中的遍歷可以通過雙鏈表的形式來加速。具體來說,考慮到?jīng)]有頂點屬性訪問的兩跳遍歷,Neo4j需要:1)從起始頂點開始遍歷雙向鏈表,找到第一條邊;2)迭代步驟(1)中找到的所有邊上連接的其他雙向鏈表,完成下一跳。這種兩跳遍歷可以擺脫在兩個步驟之間加載頂點記錄,以減少磁盤I/O。

圖1 - Neo4j的存儲模型
圖2說明了Neo4j如何將所有記錄存儲在磁盤上。我們可以看到,每條記錄都有自己固定大小的塊,相同類型的記錄被連續(xù)地存儲在一起,形成一張表。因此,表中的每條記錄都可以根據(jù)其偏移量進行有效定位,其中偏移量是根據(jù)記錄的ID計算的。對于屬性值,如果它的長度大于一個記錄塊的默認長度,那么Neo4j將把這個屬性值的超出部分存儲在另一個由若干固定大小的槽組成的分離數(shù)據(jù)塊中。

圖2 - Neo4j不同類型的數(shù)據(jù)記錄在磁盤上的組織形式
(2)RedisGraph
RedisGraph是一個基于Redis的圖存儲,Redis是一個基于內存的鍵值存儲系統(tǒng)。然而,RedisGraph沒有將圖數(shù)據(jù)建模為適合Redis存儲模型的鍵值存儲,而是利用鄰接矩陣設計了自己的存儲模型,只利用了Redis的內存分配和索引管理。這就是我們將RedisGraph列為圖原生存儲數(shù)據(jù)庫的原因。
圖2展示了RedisGraph是如何建模和存儲圖的。點和邊的屬性被存儲到一個頂點/邊緣容器的數(shù)組中。每個頂點/邊容器都有一個header來記錄當前容器的元數(shù)據(jù),包括存儲的頂點/邊的數(shù)量,容器的容量,以及使用的內存大小。對于每個頂點/邊,其屬性被存儲在一個鏈表中,鏈表里的每個節(jié)點是一個具有固定大小的數(shù)據(jù)塊。屬性的鍵值對被按順序存儲在數(shù)據(jù)塊中。當前一個數(shù)據(jù)塊滿了之后,一個新的數(shù)據(jù)塊將被追加到鏈表的尾部。此外,RedisGraph將具有相同標簽的頂點/邊放到同一個容器中,以獲得更好的數(shù)據(jù)局部性。由于RedisGraph需要為每個頂點/邊和數(shù)據(jù)塊從Redis存儲層調用內存分配,它根據(jù)容器的容量預先分配了容器所需的所有內存,以避免頻繁且昂貴的內存分配調用。
RedisGraph中的所有邊都以鄰接矩陣的格式存儲。如果兩個頂點之間存在一條邊,就會在鄰接矩陣的對應位置上存儲一個指向該邊實例的指針,否則就不存儲。由于圖的性質,鄰接矩陣大多是一個稀疏矩陣。因此,RedisGraph選擇使用了壓縮稀疏行(CSR)的格式來實現(xiàn)對矩陣的存儲。而多跳遍歷可以通過RedisGraph中的矩陣乘法來計算。然而,在CSR格式下,圖拓撲結構的變化對CSR的更新是很昂貴的,而且會給遍歷操作帶來嚴重的開銷。

圖3 - RedisGraph的存儲Layout設計
(3)Sparksee
Sparksee以前被稱作DEX,也是一個圖數(shù)據(jù)庫。它利用基于位圖的索引bitmap來減少存儲開銷,并通過基于位(bit)的邏輯操作來加速與圖相關的工作負載。
為了存儲一個圖,Sparksee首先將所有的數(shù)據(jù)分為不同的值集(value set)。具體來說,一個值集是由以下一種鍵值對組成的:1.(頂點/邊ID,Label);2.(邊ID, 頭/尾頂點ID); 3.(頂點/邊ID, 屬性鍵的屬性值)。對于每個值集,Sparksee用兩個map來存儲所有的對:一個map記錄每個對象(即頂點/邊)到一個值(即Label、頭/尾頂點或屬性值),而另一個map則是將不同的值映射到一個位圖(如圖4所示)。因此,圖的拓撲信息是以邊列表和鄰接表(即位圖)的形式存儲在值集中的。
位圖結構是一個具有可變長度的bits序列,它由第一個和最后一個非零元素定義。位圖中的每個位都與一個對象的標識符oid相關(即頂點/邊ID)。如果該對象有相關的值,相應的位置就被設置為1,否則為0。通過使用位圖結構,Sparksee可以將一些基于圖的操作轉化為位運算操作。由于位圖的長度是由第一個和最后一個非零元素定義的,所以位圖不可避免地會變得很大,這就造成了數(shù)據(jù)檢索的開銷。為了壓縮位圖,Sparksee將一個位圖分割成多個長度為32位的子序列。每個子序列都與一個給定的ID配對,并存儲在一個排序的樹中。為了減少空間的使用,只有非零的子序列會被存儲并被排序樹索引。由于bits是以連續(xù)的方式分割的,Sparksee可以在數(shù)據(jù)檢索時快速定位到某個bits的子序列ID。

圖4:Sparksee中的值集與位圖
3、基于RDBMS構建的圖數(shù)據(jù)庫?
由于關系型數(shù)據(jù)庫有相對成熟的技術和性能優(yōu)化,許多圖數(shù)據(jù)庫都是建立在RDBMS或關系型數(shù)據(jù)模型之上的(比如SQLGraph, AgensGraph, etc.)。AgensGraph就是一個構建于PostgreSQL之上的圖數(shù)據(jù)庫,Oracle Spatial and Graph則是Oracle中支持圖數(shù)據(jù)存儲的一個組件。為了在關系數(shù)據(jù)庫中建立圖數(shù)據(jù)模型,頂點和邊通常被存儲為表中的記錄,其中的每一列代表一種屬性。除屬性外,邊記錄還將其源點和目標點作為兩個外鍵存儲,以支持遍歷操作,這可以通過表的Join來完成。而連續(xù)的Join會嚴重損害多跳遍歷的性能,特別是當表內有大量頂點時。
(1)AgensGraph
我們以AgensGraph為例來介紹在關系型數(shù)據(jù)庫中存儲圖數(shù)據(jù)的方案。由于頂點/邊的屬性在圖中并不總是有固定的Schema,AgensGraph用基于JSON的表來存儲屬性,所有的屬性都以JSON格式存儲在一列。具體來說,AgensGraph表中的一行記錄,對于頂點是按照(VertexID, Label, Properties in JSON)的格式來存儲的,對于邊則是按照(EdgeID, Source VertexID, Destination VertexID, Properties in JSON)的格式存儲的。圖5顯示了AgensGraph是如何管理磁盤上的表數(shù)據(jù)的。表文件首先被切成具有固定大小的多個頁。每頁的頁頭存儲了本頁的元數(shù)據(jù),包括存儲的記錄數(shù)和這一頁的使用空間。為了更好地在頁中進行順序掃描,每條記錄都有一個固定大小的指針塊,包含相關記錄數(shù)據(jù)的偏移量和長度。指針塊以正向方式從頁頭開始存儲,而記錄數(shù)據(jù)則以反向方式從頁尾開始存儲。

圖5 - AgensGraph中圖數(shù)據(jù)在Table中以頁的方式的存儲格式
4、基于文檔構建的圖數(shù)據(jù)庫?
文檔存儲的基本單元是一個以某種標準格式(如JSON、XML或BSON等二進制格式)編碼的文檔。通過這些半結構化的格式,文檔可以靈活地以鍵值對的形式存儲頂點/邊的屬性,且沒有固定的Schema。因此,在基于文檔的圖數(shù)據(jù)庫中,一組頂點/邊被存儲為一個文檔。為了連接頂點和與之關聯(lián)的鄰接邊,頂點文檔會包含該點的鄰接表,其以一組嵌套的鍵值來表示,對應的值是一個List或者是一組記錄了label的鍵值對。
(1)OrientDB
OrientDB是一個典型的基于文檔的圖數(shù)據(jù)庫。圖6展示了OrientDB是如何存儲頂點和邊文件的。頂點和邊首先被它們的標簽分離成類。一個類可以為存儲的文檔定義一個屬性集。雖然一個文檔不一定包含所有定義的屬性,但類仍然可以幫助在訪問實際數(shù)據(jù)前對不存在的屬性進行預過濾。每個類可以進一步分割成多個cluster,以便根據(jù)CPU核數(shù)實現(xiàn)并行數(shù)據(jù)訪問。每個頂點/邊分配了一個唯一的RID,以便快速定位,RID由類ID、Cluster ID和在Cluster中的位置構成。
除了RID和屬性,頂點文件還存儲了兩種不同格式的鄰接表(即regular Edgelist和lightweight Edgelist)。Regular Edgelist存儲了相鄰邊的RID,而Lightweight Edgelist包含了入向頂點的RID。因此在遍歷時,如果查詢不需要訪問邊屬性,OrientDB可以使用Lightweight Edgelist來直接獲得目標頂點。否則,OrientDB將通過RID找到邊文檔來訪問邊屬性,最后獲得存儲在邊文檔中的頂點RID(即源點和目標點)。

圖6 - OrientDB的數(shù)據(jù)存儲格式
5、基于寬列構建的圖數(shù)據(jù)庫?
寬列存儲是由表組成的,表是行的集合。與關系型數(shù)據(jù)庫不同,寬列存儲沒有要求固定的Schema。每一列的名稱因行而異,每一行的鍵值對都存儲在這一列中。因此,寬列存儲也可以被視為二維鍵值存儲。Google的BigTable和Hadoop生態(tài)體系下的HBase就是典型的寬列存儲。其表中的每一行都包含任意數(shù)量的單元格,每個單元格都存儲一個鍵值對。利用寬列模型來存儲圖數(shù)據(jù)的典型圖數(shù)據(jù)庫有Titan和JanusGraph。
(1)JanusGraph
JanusGraph的底層存儲就是HBase, 在HBase中每一行都是一個由ID唯一識別的頂點。如圖7(a)所示,JanusGraph將點的每個屬性和鄰接邊都存儲到行中的一個單元格中。為了快速檢索,屬性按屬性ID排序,邊按邊的標簽排序。圖7(b)顯示了JanusGraph中邊和屬性存儲的詳細格式。一條邊的key是由label和direction的復合ID、排序鍵、相鄰頂點ID和邊ID組成的。排序鍵可以由邊的label和其他邊的屬性來組成,以便加快遍歷。
由于JanusGraph沒有將邊組織成Row,所有的屬性都被序列化并存儲在表示邊的列單元中。為了避免在屬性過濾時對屬性列單元中的值進行頻繁的反序列化,JanusGraph存儲了signature key,其包括了所有的屬性ID,以便快速檢查屬性是否存在。屬性列單元的結構比邊列單元相對簡單,屬性單元的key字段只存儲一個由屬性key編碼的ID,而value字段包含一個為每個屬性鍵和屬性值分配的唯一ID。

圖7 - JanusGraph的圖數(shù)據(jù)存儲格式
三、圖數(shù)據(jù)庫的現(xiàn)狀
隨著大數(shù)據(jù)基礎設施的不斷發(fā)展與完善, 數(shù)據(jù)庫產(chǎn)品的研發(fā)方向也正在從不斷提升經(jīng)典存儲系統(tǒng)的性能與穩(wěn)定性逐步轉向為針對各種垂直類場景的特定性能要求而定制化設計。例如,隨著物聯(lián)網(wǎng)時代的到來,各類傳感器、汽車、基站等端設備產(chǎn)生的數(shù)據(jù)規(guī)模正不斷增大,該場景具有典型的存量數(shù)據(jù)大、新增數(shù)據(jù)多(采集頻率高、設備量多)的特點,對數(shù)據(jù)庫的實時性能要求也比較高,通常需支持千萬級QPS的寫入,以及毫秒級的查詢響應時間。傳統(tǒng)的數(shù)據(jù)庫架構很難再滿足這種特定場景下的讀寫需求,用戶已不再考慮一招能解決所有問題(one-size-fits-all)的方案,而逐漸轉向針對不同工作負載給出特定數(shù)據(jù)庫選型方案的思路。由此,各種垂直類型的數(shù)據(jù)庫不斷被提出,例如圖數(shù)據(jù)庫、時序數(shù)據(jù)庫、流式數(shù)據(jù)庫、向量數(shù)據(jù)庫等等。
圖數(shù)據(jù)庫的架構和性能需求也在不斷與時俱進,進入"2.0時代"。一方面圖數(shù)據(jù)的規(guī)模越來越大,一套成熟的分布式高可用方案已經(jīng)變成對圖數(shù)據(jù)庫的基本需求,另一方面對圖數(shù)據(jù)的查詢復雜度也在進一步提升,人們越來越想從高階的多跳查詢(>3跳)中挖掘出關聯(lián)關系數(shù)據(jù)的深層價值。而圖數(shù)據(jù)本來天生就具有數(shù)據(jù)傾斜的特點,出入度大的點往往占比很少,而與之相關聯(lián)的查詢卻需要訪問很大比例的全圖數(shù)據(jù)才能返回最終結果,因此需要更多的算力。然而,在圖上對度數(shù)大的點的訪問是很難預測的,如何在不影響吞吐的情況下,降低查詢的平均延時以保證服務的P99能滿足在線要求?單是這一點就是件挑戰(zhàn)力十足的事情。
而隨著圖數(shù)據(jù)的價值不斷被認可,越來越多的應用場景也開始使用圖模型來表達業(yè)務數(shù)據(jù)(例如,金融網(wǎng)絡中的反洗錢、反套現(xiàn),電商交易網(wǎng)絡中的商品推薦,短視頻中的點贊關注記錄等)。數(shù)據(jù)從產(chǎn)出之初,就被業(yè)務寫入到了圖數(shù)據(jù)庫中,并期望可以做到寫后的實時可見,因此在高可用的前提下,圖數(shù)據(jù)庫對數(shù)據(jù)的一致性、事務性也開始有了要求。新一代的圖數(shù)據(jù)庫架構在時間和業(yè)務需求的催化下,被自然衍生了出來。圖數(shù)據(jù)庫的熱度也一路水漲船高,如DB-Engines網(wǎng)站所示,從2013年開始至今,圖數(shù)據(jù)庫的流行趨勢變化是所有垂類數(shù)據(jù)庫中最高的,且看趨勢至少未來5年也依然會保持最高。2023年,圖數(shù)據(jù)庫的標準查詢語言GQL也會發(fā)布,各種類型的圖數(shù)據(jù)庫查詢語言(e.g., Gremlin, Cypher, GSQL, nGQL)相信終將迎來統(tǒng)一,這可以進一步促進圖數(shù)據(jù)庫生態(tài)的發(fā)展。

接下來,本文將盤點近幾年有代表性的若干個現(xiàn)代圖數(shù)據(jù)庫的架構設計,簡單講解下圖數(shù)據(jù)庫2.0時代對高可用性和高性能的業(yè)界實現(xiàn)方案。
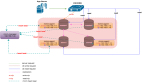
1、NebulaGraph
NebulaGraph是一款開源的高性能分布式圖數(shù)據(jù)庫,一個完整的 Nebula 部署集群包含三個服務,Query Service, Storage Service 和 Meta Service, 如圖8所示:

圖8 - NebulaGraph的系統(tǒng)架構
圖片來源自:https://www.nebula-graph.com.cn/posts/nebula-graph-architecture-overview
Meta Service集群基于raft協(xié)議保證了數(shù)據(jù)的一致性和高可用。Meta Service不僅負責存儲和提供圖數(shù)據(jù)的meta信息,如schema、partition信息等,還同時負責指揮數(shù)據(jù)遷移及 leader 的變更等運維操作。左側主要服務采用了存儲與計算分離的架構,虛線以上為計算,以下為存儲。計算層和存儲層可以根據(jù)各自的情況彈性擴容、縮容,也使水平擴展成為可能。此外,存儲計算分離使得 Storage Service 可以為多種類型的計算層或者計算引擎提供服務。
Nebula的每個計算節(jié)點都運行著一個無狀態(tài)的查詢計算引擎,而節(jié)點彼此間無任何通信關系。計算節(jié)點從Meta Service讀取meta信息然后將請求發(fā)送到對應的Storage Service實例上。這樣設計使得計算層更容易使用 K8s 管理或部署在云上。每個查詢計算引擎都能接收客戶端的請求,解析查詢語句,生成抽象語法樹(AST)并將 AST 傳遞給執(zhí)行計劃器和優(yōu)化器,最后再交由執(zhí)行器執(zhí)行。
Storage Service采用shared-nothing的分布式架構設計,每個存儲節(jié)點都有多個本地 KV 存儲實例作為物理存儲。Nebula同樣用Raft來保證這些 KV 存儲之間的一致性,并在KV語義之上封裝了一層圖語義層,用于將圖操作轉換為下層的KV操作。圖數(shù)據(jù)(點和邊)通過Hash的方式存儲在不同Partition中,這些Partition分布在所有的存儲節(jié)點上,分布信息則存儲在Meta Service中。
2、ByteGraph
ByteGraph是字節(jié)跳動基礎架構團隊自研的分布式圖數(shù)據(jù)庫產(chǎn)品,并在字節(jié)內部的近一百條業(yè)務線上得到了廣泛的落地,包括抖音上的好友關系,用戶-視頻點贊關系等。ByteGraph的架構(如圖9所示)整體上跟Nebula較為類似,也采用計算-存儲分離的架構,不同的地方在于ByteGraph的存儲層進一步劃分成了內存存儲層和磁盤存儲層。

圖9 - ByteGraph的系統(tǒng)架構
圖片來源自:https://zhuanlan.zhihu.com/p/109401046
ByteGraph的查詢層同樣沒有狀態(tài),可以水平擴容,主要工作是做讀寫請求的解析和處理(將數(shù)據(jù)請求基于一致性哈希規(guī)則分發(fā)給存儲層實例并收集返回的請求結果)。內存存儲層的實現(xiàn)和功能有點類似內存數(shù)據(jù)庫,提供高性能的數(shù)據(jù)讀寫功能,具體提供點邊的讀寫接口并支持算子下推:通過把計算(算子)移動到存儲層實例上執(zhí)行,以有效提升讀性能。內存存儲層整體上作為了磁盤存儲層的緩存,提供緩存管理的功能,支持緩存加載、換出、緩存和磁盤同步異步sync等功能。磁盤存儲層是一個單獨部署的分布式鍵值對存儲服務,將圖數(shù)據(jù)以KV pairs的形式持久化存儲在磁盤上。
ByteGraph針對熱點數(shù)據(jù)訪問做了自己的存儲優(yōu)化,從系統(tǒng)角度當然希望存儲在KVS中的KV pairs大小控制在KB量級且大小均勻。其將頂點的所有出度鄰居平均拆分成多個KV對,所有KV對形成一棵邏輯上的B-Tree,數(shù)據(jù)結構如下圖所示。值得一提的是,ByteGraph在今年的VLDB'22 Industrial Track上發(fā)表了一篇論文,對其設計動機和性能分析都做了比較詳細的描述,具體可參考論文地址:
https://vldb.org/pvldb/vol15/p3306-li.pdf

圖片來源自:https://zhuanlan.zhihu.com/p/109401046
3、EasyGraph
EasyGraph是騰訊TEG數(shù)據(jù)平臺部自研的分布式圖數(shù)據(jù)庫產(chǎn)品,目前已在騰訊內部如企業(yè)微信、微信支付、王者榮耀、和平精英、QQ、廣告等諸多關鍵產(chǎn)品線落地,并且作為騰訊云KonisGraph圖數(shù)據(jù)庫對外輸出。

圖片來源自:https://zhuanlan.zhihu.com/p/450584880
EasyGraph整體上采用存儲計算分離架構,在KV存儲組件上適配了開源的TiKV及內部分布式KV;TiKV基于rocksdb實現(xiàn)了分區(qū)和副本管理,并在TiDB上有成熟的解決方案,適配TiKV可以實現(xiàn)存儲層的可擴展性,TiKV基于Raft算法實現(xiàn)了數(shù)據(jù)多副本之間的一致性。EasyGraph也自研了圖可視化分析引擎,在可視化效果及規(guī)模上都有明顯的提升,支持幾十萬級點邊渲染分析,以及用戶級靈活的布局展示和可視化分析。
EasyGraph也支持AngelGraph圖計算引擎,其包括幾十種傳統(tǒng)圖算法、Embedding及GNN算法,如社區(qū)發(fā)現(xiàn)、標簽傳播、隨機游走等算法,這些算法進一步提升對圖數(shù)據(jù)的挖掘分析能力。
4、Neo4j latest?
最新版本的Neo4j已經(jīng)支持了分布式模式以完善對高可用性和可擴展性的支持,其通過多副本的方式來防止數(shù)據(jù)丟失,如下圖所示:

圖片來源自:https://neo4j.com/docs/operations-manual/current/clustering/introduction/
Neo4j通過Primary Mode將一份數(shù)據(jù)備份到多個servers上并通過raft協(xié)議來保證一致性。與之相對應地,一次寫入需要保證至少在(N/2+1)個副本上寫成功才可以返回成功,因此在primary mode下服務實例數(shù)量越多,寫性能就越差。而為了實現(xiàn)可擴展性,Neo4j也支持了Secondary mode,即支持對多個只讀副本的部署以提高集群整體的讀能力,只讀副本是功能齊全的Neo4j數(shù)據(jù)庫,能夠完成任意(只讀)圖數(shù)據(jù)查詢和過程。只讀副本是通過事務日志shipping來完成對主副本的數(shù)據(jù)異步同步的。
Neo4j也支持了數(shù)據(jù)科學(Graph Data Science)庫,其包含了許多圖分析算法,比如社區(qū)發(fā)現(xiàn),路徑搜索等,甚至也支持了少量的圖神經(jīng)網(wǎng)絡算法(比如GraphSage, Node2Vec)。這些算法統(tǒng)一集成在了Neo4j的Cypher語言體系下,以提供給用戶統(tǒng)一的圖查詢/圖分析體驗。
5、TigerGraph?
TigerGraph如今已經(jīng)發(fā)展成為了一個商業(yè)化程度僅次于Neo4j的圖數(shù)據(jù)庫產(chǎn)品,但由于其是一個閉源產(chǎn)品,很多技術實現(xiàn)我們無從知曉。從TigerGraph網(wǎng)站上的官方技術博客描述來看,TigerGraph 是一款分布式MPP圖數(shù)據(jù)庫,同時支持在線事務處理(OLTP)和在線分析查詢(OLAP),也集成了基于PyG的圖神經(jīng)網(wǎng)絡訓練功能。
從架構上看,TigerGraph集成了較為完善的數(shù)據(jù)導入功能,可以在系統(tǒng)在線的情況下,將關系型數(shù)據(jù)或其他格式的半結構化數(shù)據(jù)導入到TigerGraph系統(tǒng)中。TigerGraph的Graph Storage Engine(GSE)負責了對數(shù)據(jù)的壓縮和存儲,其將數(shù)據(jù)編碼、轉換成一種對MPP處理友好的圖原生存儲格式后加載至Graph Processing Engine(GPE),而GPE則是具體負責響應查詢請求和圖計算分析的執(zhí)行引擎。TigerGraph還包含一個可視化的客戶端以及 REST API,并集成了很多企業(yè)數(shù)據(jù)基礎設施服務。TigerGraph使用Apache Kafka讓GSE與GPE進行數(shù)據(jù)同步,邏輯上GPE可以理解為一個內存存儲層,而GSE是一個圖原生的持久化存儲層;數(shù)據(jù)的更新將先反應到GPE層,然后通過Kafka將Transaction Log交給GSE消費并完成持久化更新。

圖片來源自:https://docs.tigergraph.com/tigergraph-server/current/intro/internal-architecture
在OLTP功能上,TigerGraph支持完整的ACID特性,支持最高的serializability事務隔離級別。TigerGraph支持垂直擴展和水平擴展,且可以對集群中的圖數(shù)據(jù)自動分區(qū)。從這點來看,TigerGraph對大規(guī)模圖數(shù)據(jù)的存儲支持得比Neo4j要友好很多。TigerGraph使用自定義的GSQL語言來表達查詢邏輯,GSQL將SQL風格的查詢語法與Cypher風格的圖遍歷語法結合在了一起,并支持用戶自定義函數(shù)。
四、圖數(shù)據(jù)庫的未來
圖數(shù)據(jù)庫在經(jīng)歷了最近幾年的蓬勃發(fā)展之后,無論是系統(tǒng)性能還是穩(wěn)定性都得到了大幅提升,那接下來Graph Database Community再會往哪些方向發(fā)展呢?
筆者認為,一方面統(tǒng)一圖數(shù)據(jù)庫的查詢語言標準(GQL)是一件迫在眉睫的事情,標準的制定將有利于降低用戶的學習門檻,并使得圖數(shù)據(jù)庫的查詢優(yōu)化技術可以得到更充分的發(fā)展,比如根據(jù)圖數(shù)據(jù)分布往往不均勻的特點提出定制化的基于規(guī)則和基于代價的優(yōu)化策略,還比如可以將如今在OLAP領域大紅大紫的向量化執(zhí)行技術和代碼生成技術引入到圖查詢引擎中,以提升Graph OLAP的執(zhí)行效率。而另一方面,筆者認為圖數(shù)據(jù)庫之所以能在最近幾年大火的另一個原因是源于圖計算技術和圖AI技術的崛起。而這些技術能夠同時引起各界學者和工程師的關注也是因為圖狀數(shù)據(jù)的獨特之處 -- 特別是在這個數(shù)據(jù)互聯(lián)的時代,需要盡可能在低成本、短時間的前提下從海量數(shù)據(jù)中挖掘出關聯(lián)最深,價值最大的信息,圖就是非常理想的解決方案。除此以外,我們很難從其他種類的NoSQL模型、大數(shù)據(jù)框架或關系型數(shù)據(jù)庫中找到隱式數(shù)據(jù)關聯(lián)的解決辦法。
隨著算力的提升和大數(shù)據(jù)生態(tài)的日漸成熟,我們的目標正在從存儲系統(tǒng)的效率轉變?yōu)閺拇鎯ο到y(tǒng)包含的數(shù)據(jù)中提取價值。圖數(shù)據(jù)庫需要與圖計算系統(tǒng)、圖AI系統(tǒng),乃至流圖系統(tǒng)緊密地聯(lián)動起來,才能讓圖數(shù)據(jù)的價值在用戶手中得到充分的釋放。而如何打造一套可以讓不同目標的圖系統(tǒng)都集成到一起,提供統(tǒng)一DDL并簡單易用的graph infrastructure呢?我們能看到各個廠商和初創(chuàng)公司正在給出自己的答案...