對 Pulsar 集群的壓測與優化

前言
這段時間在做 MQ(Pulsar)相關的治理工作,其中一個部分內容關于消息隊列的升級,比如:
- 一鍵創建一個測試集群。
- 運行一批測試用例,覆蓋我們線上使用到的功能,并輸出測試報告。
- 模擬壓測,輸出測試結果。
本質目的就是想直到新版本升級過程中和升級后對現有業務是否存在影響。
一鍵創建集群和執行測試用例比較簡單,利用了 helm 和 k8s client 的 SDK 把整個流程串起來即可。
壓測
其實稍微麻煩一點的是壓測,Pulsar 官方本身是有提供一個壓測工具;只是功能相對比較單一,只能對某批 topic 極限壓測,最后輸出測試報告。最后參考了官方的壓測流程,加入了一些實時監控數據,方便分析整個壓測過程中性能的變化。
客戶端 timeout
隨著壓測過程中的壓力增大,比如壓測時間和線程數的提高,客戶端會拋出發送消息 timeout 異常。
而這個異常在生產業務環境的高峰期偶爾也出現過,這會導致業務數據的丟失;所以正好這次被我復現出來后想著分析下產生的原因以及解決辦法。
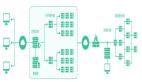
源碼分析客戶端
既然是客戶端拋出的異常所以就先看從異常點開始看起,其實整個過程和產生的原因并不復雜,如下圖:

客戶端流程:
- 客戶端 producer 發送消息時先將消息發往本地的一個 pending 隊列。
- 待 broker 處理完(寫入 bookkeeper) 返回 ACK 時刪除該 pending 隊列頭的消息。
- 后臺啟動一個定時任務,定期掃描隊列頭(頭部的消息是最后寫入的)的消息是否已經過期(過期時間可配置,默認30s)。
- 如果已經過期(頭部消息過期,說明所有消息都已過期)則遍歷隊列內的消息依次拋出PulsarClientException$TimeoutException 異常,最后清空該隊列。
服務端 broker 流程:
- 收到消息后調用 bookkeeper API 寫入消息。
- 寫入消息時同時寫入回調函數。
- 寫入成功后執行回調函數,這時會記錄一條消息的寫入延遲,并通知客戶端 ACK。
- 通過 broker metric 指標pulsar_broker_publish_latency 可以獲取寫入延遲。
從以上流程可以看出,如果客戶端不做兜底措施則在第四步會出現消息丟失,這類本質上不算是 broker 丟消息,而是客戶端認為當時 broker 的處理能力達到上限,考慮到消息的實時性從而丟棄了還未發送的消息。
性能分析
通過上述分析,特別是 broker 的寫入流程得知,整個寫入的主要操作便是寫入 bookkeeper,所以 bookkeeper 的寫入性能便關系到整個集群的寫入性能。
極端情況下,假設不考慮網絡的損耗,如果 bookkeeper 的寫入延遲是 0ms,那整個集群的寫入性能幾乎就是無上限;所以我們重點看看在壓測過程中 bookkeeper 的各項指標。
CPU
首先是 CPU:

從圖中可以看到壓測過程中 CPU 是有明顯增高的,所以我們需要找到壓測過程中 bookkeeper 的 CPU 大部分損耗在哪里?
這里不得不吹一波阿里的 arthas 工具,可以非常方便的幫我們生成火焰圖。

分析火焰圖最簡單的一個方法便是查看頂部最寬的函數是哪個,它大概率就是性能的瓶頸。
在這個圖中的頂部并沒有明顯很寬的函數,大家都差不多,所以并沒有明顯損耗 CPU 的函數。
此時在借助云廠商的監控得知并沒有得到 CPU 的上限(limit 限制為 8核)。

使用 arthas 過程中也有個小坑,在 k8s 環境中有可能應用啟動后沒有成功在磁盤寫入 pid ,導致查詢不到 Java 進程。
此時可以直接 ps 拿到進程 ID,然后在啟動的時候直接傳入 pid 即可。
通常情況下這個 pid 是 1。
磁盤
既然 CPU 沒有問題,那就再看看磁盤是不是瓶頸。

可以看到壓測時的 IO 等待時間明顯是比日常請求高許多,為了最終確認是否是磁盤的問題,再將磁盤類型換為 SSD 進行測試。

果然即便是壓測,SSD磁盤的 IO 也比普通硬盤的正常請求期間延遲更低。
既然磁盤 IO 延遲降低了,根據前文的分析理論上整個集群的性能應該會有明顯的上升,因此對比了升級前后的消息 TPS 寫入指標:

升級后每秒的寫入速率由 40k 漲到 80k 左右,幾乎是翻了一倍(果然用錢是最快解決問題的方式);
但即便是這樣,極限壓測后依然會出現客戶端 timeout,這是因為無論怎么提高服務端的處理性能,依然沒法做到沒有延遲的寫入,各個環節都會有損耗。
升級過程中的 timeout
還有一個關鍵的步驟必須要覆蓋:模擬生產現場有著大量的生產者和消費者接入收發消息時進行集群升級,對客戶端業務的影響。
根據官方推薦的升級步驟,流程如下:
- Upgrade Zookeeper.
- Disable autorecovery.
- Upgrade Bookkeeper.
- Upgrade Broker.
- Upgrade Proxy.
- Enable autorecovery.
其中最關鍵的是升級 Broker 和 Proxy,因為這兩個是客戶端直接交互的組件。
本質上升級的過程就是優雅停機,然后使用新版本的 docker 啟動;所以客戶端一定會感知到 Broker 下線后進行重連,如果能快速自動重連那對客戶端幾乎沒有影響。

在我的測試過程中,2000左右的 producer 以 1k 的發送速率進行消息發送,在 30min 內完成所有組件升級,整個過程客戶端會自動快速重連,并不會出現異常以及消息丟失。
而一旦發送頻率增加時,在重啟 Broker 的過程中便會出現上文提到的 timeout 異常;初步看起來是在默認的 30s 時間內沒有重連成功,導致積壓的消息已經超時。
經過分析源碼發現關鍵的步驟如下:

客戶端在與 Broker 的長連接狀態斷開后會自動重連,而重連到具體哪臺 Broker 節點是由 LookUpService 處理的,它會根據使用的 topic 獲取到它的元數據。
理論上這個過程如果足夠快,對客戶端就會越無感。
在元數據中包含有該 topic 所屬的 bundle 所綁定的 Broker 的具體 IP+端口,這樣才能重新連接然后發送消息。
bundle 是一批 topic 的抽象,用來將一批 topic 與 Broker 綁定。
而在一個 Broker 停機的時會自動卸載它所有的 bundle,并由負載均衡器自動劃分到在線的 Broker 中,交由他們處理。
這里會有兩種情況降低 LookUpSerive 獲取元數據的速度:
因為所有的 Broker 都是 stateful 有狀態節點,所以升級時是從新的節點開始升級,假設是broker-5,假設升級的那個節點的 bundle 切好被轉移 broker-4中,客戶端此時便會自動重連到 4 這個Broker 中。
此時客戶端正在講堆積的消息進行重發,而下一個升級的節點正好是 4,那客戶端又得等待 bundle 成功 unload 到新的節點,如果恰好是 3 的話那又得套娃了,這樣整個消息的重發流程就會被拉長,直到超過等待時間便會超時。
還有一種情況是 bundle 的數量比較多,導致上面講到的 unload 時更新元數據到 zookeeper 的時間也會增加。
所以我在考慮 Broker 在升級過程中時,是否可以將 unload 的 bundle 優先與 Broker-0進行綁定,最后全部升級成功后再做一次負載均衡,盡量減少客戶端重連的機會。
解決方案
如果我們想要解決這個 timeout 的異常,也有以下幾個方案:
- 將 bookkeeper 的磁盤換為寫入時延更低的 SSD,提高單節點性能。
- 增加 bookkeeper 節點,不過由于 bookkeeper 是有狀態的,水平擴容起來比較麻煩,而且一旦擴容再想縮容也比較困難。
- 增加客戶端寫入的超時時間,這個可以配置。
- 客戶端做好兜底措施,捕獲異常、記錄日志、或者入庫都可以,后續進行消息重發。
- 為 bookkeeper 的寫入延遲增加報警。
- Spring 官方剛出爐的 Pulsar-starter 已經內置了 producer 相關的 metrics,客戶端也可以對這個進行監控報警。
以上最好實現的就是第四步了,效果好成本低,推薦還沒有實現的都盡快 try catch 起來。
整個測試流程耗費了我一兩周的時間,也是第一次全方位的對一款中間件進行測試,其中也學到了不少東西;不管是源碼還是架構都對 Pulsar 有了更深入的理解。