Linux 中的負載高低和 CPU 開銷并不完全對應
大家好,我是飛哥!
負載是查看 Linux 服務器運行狀態時很常用的一個性能指標。在觀察線上服務器運行狀況的時候,我們也是經常把負載找出來看一看。在線上請求壓力過大的時候,經常是也伴隨著負載的飆高。
但是負載的原理你真的理解了嗎?我來列舉幾個問題,看看你對負載的理解是否足夠的深刻。
- 負載是如何計算出來的?
- 負載高低和 CPU 消耗正相關嗎?
- 內核是如何暴露負載數據給應用層的?
如果你對以上問題的理解還拿捏不是很準,那么飛哥今天就帶你來深入地了解一下 Linux 中的負載!
一、理解負載查看過程
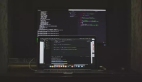
我們經常用 top 命令查看 Linux 系統的負載情況。一個典型的 top 命令輸出的負載如下所示。
輸出中的 Load Avg 就是我們常說的負載,也叫系統平均負載。因為單純某一個瞬時的負載值并沒有太大意義。所以 Linux 是計算了過去一段時間內的平均值,這三個數分別代表的是過去 1 分鐘、過去 5 分鐘和過去 15 分鐘的平均負載值。
那么 top 命令展示的數據數是如何來的呢?事實上,top 命令里的負載值是從 /proc/loadavg 這個偽文件里來的。通過 strace 命令跟蹤 top 命令的系統調用可以看的到這個過程。
內核中定義了 loadavg 這個偽文件的 open 函數。當用戶態訪問 /proc/loadavg 會觸發內核定義的函數,在這里會讀取內核中的平均負載變量,簡單計算后便可展示出來。整體流程如下圖所示。

我們根據上述流程圖再展開了看下。偽文件 /proc/loadavg 在 kernel 中定義是在 /fs/proc/loadavg.c 中。在該文件中會創建 /proc/loadavg,并為其指定操作方法 loadavg_proc_fops。
在 loadavg_proc_fops 中包含了打開該文件時對應的操作方法。
當在用戶態打開 /proc/loadavg 文件時,都會調用 loadavg_proc_fops 中的 open 函數指針 - loadavg_proc_open。loadavg_proc_open 接下來會調用 loadavg_proc_show 進行處理,核心的計算是在這里完成的。
在 loadavg_proc_show 函數中做了兩件事。
- 調用 get_avenrun 讀取當前負載值
- 將平均負載值按照一定的格式打印輸出
在上面的源碼中,大家看到了 FIXED_1/200、LOAD_INT、LOAD_FRAC 等奇奇怪怪的定義,代碼寫的這么猥瑣是因為內核中并沒有 float、double 等浮點數類型,而是用整數來模擬的。這些代碼都是為了在整數和小數之間轉化使的。知道這個背景就行了,不用過度展開剖析。
這樣用戶通過訪問 /proc/loadavg 文件就可以讀取到內核計算的負載數據了。其中獲取 get_avenrun 只是在訪問 avenrun 這個全局數組而已。
現在可以總結一下我們開篇中的一個問題: 內核是如何暴露負載數據給應用層的?
內核定義了一個偽文件 /proc/loadavg,每當用戶打開這個文件的時候,內核中的 loadavg_proc_show 函數就會被調用到,接著訪問 avenrun 全局數組變量 并將平均負載從整數轉化為小數,并打印出來。
好了,另外一個新問題又來了,avenrun 全局數組變量中存儲的數據是何時,又是被如何計算出來的呢?
二、內核中負載的計算過程
接上小節,我們繼續查看 avenrun 全局數組變量的數據來源。這個數組的計算過程分為如下兩步:
1.PerCPU 定期匯總瞬時負載:定時刷新每個 CPU 當前任務數到 calc_load_tasks,將每個 CPU 的負載數據匯總起來,得到系統當前的瞬時負載。
2.定時計算系統平均負載:定時器根據當前系統整體瞬時負載,使用指數加權移動平均法(一種高效計算平均數的算法)計算過去 1 分鐘、過去 5 分鐘、過去 15 分鐘的平均負載。
接下來我們分成兩個小節來分別介紹。
2.1 PerCPU 定期匯總負載
在 Linux 內核中,有一個子系統叫做時間子系統。在時間子系統里,初始化了一個叫高分辨率的定時器。在該定時器中會定時將每個 CPU 上的負載數據(running 進程數 + uninterruptible 進程數)匯總到系統全局的瞬時負載變量 calc_load_tasks 中。整體流程如下圖所示。

我們把上述流程圖展開看一下,我們找到了高分辨率定時器的源碼如下:
在高分辨率初始化的時候,將到期函數設置成了 tick_sched_timer。通過這個函數讓每個 CPU 都會周期性地執行一些任務。其中刷新當前系統負載就是在這個時機進行的。這里有一點要注意一個前提是每個 CPU 都有自己獨立的運行隊列,。
我們根據 tick_sched_timer 的源碼進行追蹤,它依次通過調用 tick_sched_handle => update_process_times => scheduler_tick。最終在 scheduler_tick 中會刷新當前 CPU 上的負載值到 calc_load_tasks 上。因為每個 CPU 都在定時刷,所以 calc_load_tasks 上記錄的就是整個系統的瞬時負載值。
我們來看下負責刷新的 scheduler_tick 這個核心函數:
在這個函數中,獲取當前 cpu 以及其對應的運行隊列 rq(run queue),調用 update_cpu_load_active 刷新當前 CPU 的負載數據到全局數組中。
在 calc_load_account_active 中看到,通過 calc_load_fold_active 獲取當前運行隊列的負載相對值,并把它加到全局瞬時負載值 calc_load_tasks 上。至此,calc_load_tasks 上就有了當前系統當前時間下的整體瞬時負載總數了。
我們再展開看看是如何根據運行隊列計算負載值的:
哦,原來是同時計算了 nr_running 和 nr_uninterruptible 兩種狀態的進程的數量。對應于用戶空間中的 R 和 D 兩種狀態的 task 數(進程 OR 線程)。
由于 calc_load_tasks 是一個長期存在的數據。所以在刷新 rq 里的進程數到其上的時候,只需要刷變化的量就行,不用全部重算。因此上述函數返回的是一個 delta。
2.2 定時計算系統平均負載
上一小節中我們找到了系統當前瞬時負載 calc_load_tasks 變量的更新過程。現在我們還缺一個計算過去 1 分鐘、過去 5 分鐘、過去 15 分鐘平均負載的機制。
傳統意義上,我們在計算平均數的時候采取的方法都是把過去一段時間的數字都加起來然后平均一下。把過去 N 個時間點的所有瞬時負載都加起來取一個平均數不完事了。這其實是我們傳統意義上理解的平均數,假如有 n 個數字,分別是 x1, x2, ..., xn。那么這個數據集合的平均數就是 (x1 + x2 + ... + xn) / N。
但是如果用這種簡單的算法來計算平均負載的話,存在以下幾個問題:
1.需要存儲過去每一個采樣周期的數據
假設我們每 10 毫秒都采集一次,那么就需要使用一個比較大的數組將每一次采樣的數據全部都存起來,那么統計過去 15 分鐘的平均數就得存 1500 個數據(15 分鐘 * 每分鐘 100 次) 。而且每出現一個新的觀察值,就要從移動平均中減去一個最早的觀察值,再加上一個最新的觀察值,內存數組會頻繁地修改和更新。
2.計算過程較為復雜
計算的時候再把整個數組全加起來,再除以樣本總數。雖然加法很簡單,但是成百上千個數字的累加仍然很是繁瑣。
3.不能準確表示當前變化趨勢傳統的平均數計算過程中,所有數字的權重是一樣的。但對于平均負載這種實時應用來說,其實越靠近當前時刻的數值權重應該越要大一些才好。因為這樣能更好反應近期變化的趨勢。
所以,在 Linux 里使用的并不是我們所以為的傳統的平均數的計算方法,而是采用的一種指數加權移動平均(Exponential Weighted Moving Average,EMWA)的平均數計算法。
這種指數加權移動平均數計算法在深度學習中有很廣泛的應用。另外股票市場里的 EMA 均線也是使用的是類似的方法求均值的方法。該算法的數學表達式是:a1 = a0 * factor + a * (1 - factor)。這個算法想理解起來有點小復雜,感興趣的同學可以 Google 自行搜索。
我們只需要知道這種方法在實際計算的時候只需要上一個時間的平均數即可,不需要保存所有瞬時負載值。另外就是越靠近現在的時間點權重越高,能夠很好地表示近期變化趨勢。
這其實也是在時間子系統中定時完成的,通過一種叫做指數加權移動平均計算的方法,計算這三個平均數。

我們來詳細看下上圖中的執行過程。時間子系統將在時鐘中斷中會注冊時鐘中斷的處理函數為 timer_interrupt 。
當每次時鐘節拍到來時會調用到 timer_interrupt,依次會調用到 do_timer 函數。
其中 calc_global_load 是平均負載計算的核心。它會獲取系統當前瞬時負載值 calc_load_tasks,然后來計算過去 1 分鐘、過去 5 分鐘、過去 15 分鐘的平均負載,并保存到 avenrun 中,供用戶進程讀取。
獲取瞬時負載比較簡單,就是讀取一個內存變量而已。在 calc_load 中就是采用了我們前面說的指數加權移動平均法來計算過去 1 分鐘、過去 5 分鐘、過去 15 分鐘的平均負載的。具體實現的代碼如下:
雖然這個算法理解起來挺復雜,但是代碼看起來確實要簡單不少,計算量看起來很少。而且看不懂也沒有關系,只需要知道內核并不是采用的原始的平均數計算方法,而是采用了一種計算快,且能更好表達變化趨勢的算法就行。
至此,我們開篇提到的“負載是如何計算出來的?”這個問題也有結論了。
Linux 定時將每個 CPU 上的運行隊列中 running 和 uninterruptible 的狀態的進程數量匯總到一個全局系統瞬時負載值中,然后再定時使用指數加權移動平均法來統計過去 1 分鐘、過去 5 分鐘、過去 15 分鐘的平均負載。
三、平均負載和 CPU 消耗的關系
現在很多同學都將平均負載和 CPU 給聯系到了一起。認為負載高、CPU 消耗就會高,負載低,CPU 消耗就會低。
在很老的 Linux 的版本里,統計負載的時候確實是只計算了 runnable 的任務數量,這些進程只對 CPU 有需求。在那個年代里,負載和 CPU 消耗量確實是正相關的。負載越高就表示正在 CPU 上運行,或等待 CPU 執行的進程越多,CPU 消耗量也會越高。
但是前面我們看到了,本文使用的 3.10 版本的 Linux 負載平均數不僅跟蹤 runnable 的任務,而且還跟蹤處于 uninterruptible sleep 狀態的任務。而 uninterruptible 狀態的進程其實是不占 CPU 的。

?所以說,負載高并一定是 CPU 處理不過來,也有可能會是因為磁盤等其他資源調度不過來而使得進程進入 uninterruptible 狀態的進程導致的!
為什么要這么修改。我從網上搜到了遠在 1993 年的一封郵件里找到了原因,以下是郵件原文。
可見這個修改是在 1993 年就引入了。在這封郵件所示的 Linux 源碼變化中可以看到,負載正式把 TASK_UNINTERRUPTIBLE 和 TASK_SWAPPING 狀態(交換狀態后來從 Linux 中刪除)的進程也給添加了進來。在這封郵件中的正文中,作者也清楚地表達了為什么要把 TASK_UNINTERRUPTIBLE 狀態的進程添加進來的原因。我把他的說明翻譯一下,如下:
“內核在計算平均負載時只計算“可運行”進程。我不喜歡那樣;問題是正在“快速”交換或等待的進程,即不可中斷的 I/O,也會消耗資源。當您用慢速交換磁盤替換快速交換磁盤時,平均負載下降似乎有點不直觀...... 無論如何,下面的補丁似乎使負載平均值更加一致 WRT 系統的主觀速度。而且,最重要的是,當沒有人做任何事情時,負載仍然為零。;-)”
這一補丁提交者的主要思想是平均負載應該表現對系統所有資源的需求情況,而不應該只表現對 CPU 資源的需求。
假設某個 TASK_UNINTERRUPTIBLE 狀態的進程因為等待磁盤 IO 而排隊的話,此時它并不消耗 CPU,但是正在等磁盤等硬件資源。那么它是應該體現在平均負載的計算里的。所以作者把 TASK_UNINTERRUPTIBLE 狀態的進程都表現到平均負載里了。
所以,負載高低表明的是當前系統上對系統資源整體需求更情況。如果負載變高,可能是 CPU 資源不夠了,也可能是磁盤 IO 資源不夠了,所以還需要配合其它觀測命令具體分情況分析。
四、總結
今天我帶大家深入地學習了一下 Linux 中的負載。我們根據一幅圖來總結一下今天學到的內容。

我把負載工作原理分成了如下三步。
- 1.內核定時匯總每 CPU 負載到系統瞬時負載
- 2.內核使用指數加權移動平均快速計算過去1、5、15分鐘的平均數
- 3.用戶進程通過打開 loadavg 讀取內核中的平均負載
我們再回頭來總結一下開篇提到的幾個問題。
1.負載是如何計算出來的?
是定時將每個 CPU 上的運行隊列中 running 和 uninterruptible 的狀態的進程數量匯總到一個全局系統瞬時負載值中,然后再定時使用指數加權移動平均法來統計過去 1 分鐘、過去 5 分鐘、過去 15 分鐘的平均負載。
2.負載高低和 CPU 消耗正相關嗎?
負載高低表明的是當前系統上對系統資源整體需求更情況。如果負載變高,可能是 CPU 資源不夠了,也可能是磁盤 IO 資源不夠了。所以不能說看著負載變高,就覺得是 CPU 資源不夠用了。
3.內核是如何暴露負載數據給應用層的?
內核定義了一個偽文件 /proc/loadavg,每當用戶打開這個文件的時候,內核中的 loadavg_proc_show 函數就會被調用到,該函數中訪問 avenrun 全局數組變量,并將平均負載從整數轉化為小數,然后打印出來。