電子之路:從C語言到視覺識別
?模擬電路是可以利用三極管的導通 / 截止的狀態切換,來實現數字邏輯的。
最簡單的數字邏輯有3種:與、或、非。
這種簡單的數字電路叫門電路。
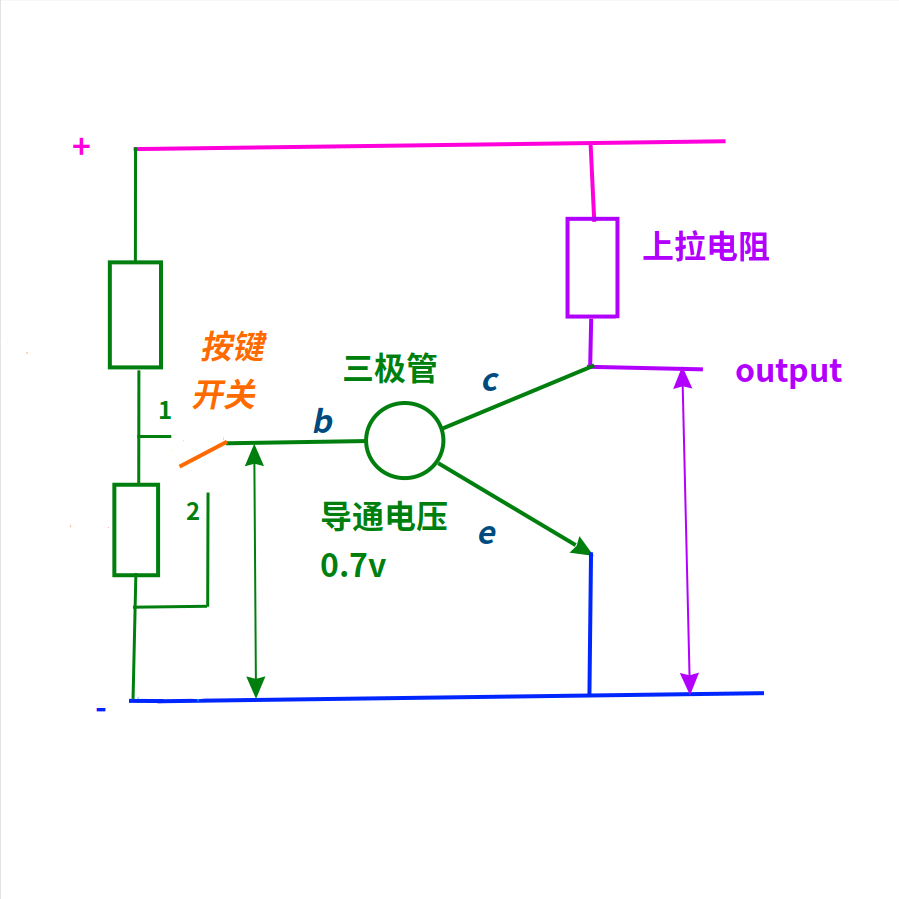
非門
最簡單的非門,就是使用一個三極管和一個電阻。
最簡單的與門,是使用兩個二極管和一個電阻。
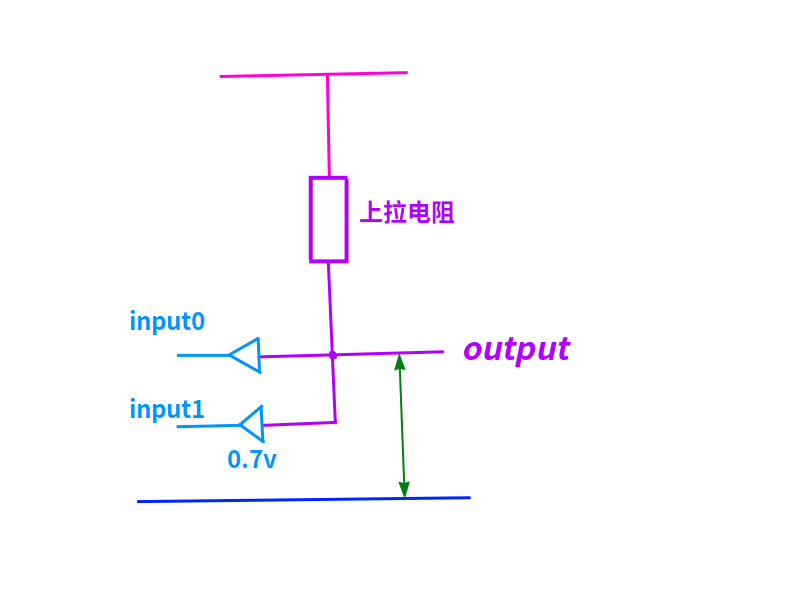
與門
如上圖,2個二極管只要有一個(與電源負極)導通時,輸出端的電壓就是0.7v,為低電位。
2個二極管都截止時,輸出端的電壓等于電源電壓,為高電位。
只使用三極管的b-e兩極時,三極管就相當于二極管。
這些簡單的門電路,都可以用來處理一個二進制位的運算,即位運算。
1.位運算
位運算,是比加減乘除更簡單的運算。
在位運算時,一個數的多個二進制位之間是不相關的。
所以,只要把32個上圖的電路并聯起來,就可以處理32位的位運算。
2.加減運算
加法和減法因為有進位和借位,它們的多個二進制位之間是相關的。
所以,加法和減法的電路實現是比較復雜的,乘法和除法更復雜。
但是,加減乘除運算都是可以用電路實現的。
(這里就不展開了,否則又得寫一大篇)
3.C語言
在位運算和加減乘除的基礎上,就可以實現一門編程語言了。
邏輯運算(&&, ||, !),就是1個二進制位的位運算。
比較運算(>, <, ==, !=, >=, <=),實際比較的是運算結果與0的大小。
2 > 1 比較的是 2 - 1 > 0,
0可以用1個二進制位表示,所以比較運算實際上也是加減運算+位運算。
if / else,就是邏輯運算。
while / for,就是個復雜點的if / else:
它會根據條件跳轉到循環開頭或結尾,而if / else不會跳轉到開頭,就這么點區別。
位運算、加減乘除、邏輯、比較、if else、while for,一門編程語言的主要運算也就這些。
當然,從數字計算機的出現到C語言的誕生,中間還隔了20多年的時間,經歷了機器語言、匯編語言,上古高級語言3個階段。
C語言從出現到現在,已經用了50年了,依然寶刀未老?
C語言之后的編程語言,基本都是在C語言的基礎上修修補補。
例如:C++添加了OOP機制;
java又在C++的基礎上做了一些簡化,并且把運行平臺從CPU搬到了jvm虛擬機,實現了跨平臺;
go語言除了有點古怪的語法之外,又差不多回到了C語言的最初設計,并且添加了協程。
現在,人們在編程語言上能夠做的改進已經比較少了,更多的是順應程序員的習慣。
所以,有個編譯器大牛好幾年前就說過:編程語言是程序員的“宗教戰爭”。
所以,php是最好的編程語言?
4.unix系統
C語言出現之后,丹尼斯-里奇和肯-湯普森馬上就用它重寫了unix系統。
這是C語言被發明的主要目的,和第一個應用。
丹尼斯-里奇在unix系統的設計模式,成了后來操作系統的典范。
unix說,“一切皆是文件”。
包括Linux在內的泛unix系的操作系統,都遵循了這一原則,而且API高度相同。
但是,API這個詞是從“異端”windows那里來的。
unix / linux 的API學名叫系統調用(syscall),但因為2000年前后微軟巨大的影響了,都被叫成了API。
并且,windows把文件的描述結構叫句柄,linux叫文件描述符,現在很多linux程序員也把文件描述符叫句柄。
畢竟,windows XP在代表了一個時代!
操作系統、數據庫、編譯器,是傳統的三大基礎軟件。
在1970年,unix和C語言出現之后,美國巨頭們就迅速壟斷了這三大領域。
不過,人類的科技發展,從來都是想重新發明自己!
怎么讓電腦像人一樣的看東西,是科學家們從1980年之后的研究重點。
5.計算機視覺
讓電腦去識別圖像的技術,叫計算機視覺,英文縮寫CV.
CV的大概可以分為兩步:
1)目標檢測,即把目標位置從背景圖片里畫出來,
2)目標識別,識別畫出來的目標是什么。

人臉識別
把人的面部從圖片中框出來,就是人臉檢測:常用的算法是Haar小波分類器。
識別框出來的人臉是誰,就是人臉識別:常用的算法是CNN,它是深度學習的一種模型。
在深度學習出現之前,人們經常使用傳統算法的組合去識別圖像。
例如:
高斯模糊,可以平滑掉圖像中的一些斑點。
拉普拉斯變換,可以檢測圖像的邊緣。
形態學膨脹,可以把一大片鄰近的點連成一塊區域:在文字識別中常用這個算法。
文字是一種邊緣特別突出的圖形,與自然物體的差異很大,所以拉普拉斯變化之后文字區域非常的明顯。
但是在閥值分隔之后,這個區域往往形成一些密集而不連續的點:
經過形態學膨脹之后,這些點就連成了一塊,可以求它的外接矩形了;
外接矩形,基本上就可以框出文字所在的區域;
然后,就可以根據特征去識別了。
對人臉的識別,也是先框出所在的區域,然后根據特征去識別。
傳統算法經常使用的是特征點檢測+分類器:
SIFT算法用來檢測特征點,SVM支持向量機用來對特征點分類,SIFT+SVM曾經是深度學習出現之前使用最多的CV算法。
當然,SIFT+SVM的效果也就那樣,畢竟它們都是非常死板的固定算法,適用場景有限。
在2006年,辛頓提出深度學習之前,CV算法對復雜場景的識別率一直不高。
雖然傳統算法在數學上都是可解釋的,但識別率是硬傷。
深度學習的參數雖然難以解釋,但它的識別率比傳統算法高得多。
這十幾年來,深度學習基本一統了CV領域。
深度學習的入門,所需要的數學知識并不多,學過高數和線代的都能很快入門。