設計穩定的微服務系統時不得不考慮的場景
我們的生產環境經常會出現一些不穩定的情況,如:
- 大促時瞬間洪峰流量導致系統超出最大負載,load 飆高,系統崩潰導致用戶無法下單
- “黑馬”熱點商品擊穿緩存,DB 被打垮,擠占正常流量
- 調用端被不穩定服務拖垮,線程池被占滿,導致整個調用鏈路卡死
這些不穩定的場景可能會導致嚴重后果。大家可能想問:如何做到均勻平滑的用戶訪問?如何預防流量過大或服務不穩定帶來的影響?
介紹
下面兩種方式是在面對流量不穩定因素時常見的兩種方案,也是我們在設計高可用的系統前不得不考慮的兩種能力,是服務流量治理中非常關鍵的一環。
流量控制
流量是非常隨機性的、不可預測的。前一秒可能還風平浪靜,后一秒可能就出現流量洪峰了(例如雙十一零點的場景)。每個系統、服務都有其能承載的容量上限,如果突然而來的流量超過了系統的承受能力,就可能會導致請求處理不過來,堆積的請求處理緩慢,CPU/Load 飆高,最后導致系統崩潰。因此,我們需要針對這種突發的流量來進行限制,在盡可能處理請求的同時來保障服務不被打垮,這就是流量控制。
熔斷降級
一個服務常常會調用別的模塊,可能是另外的一個遠程服務、數據庫,或者第三方 API 等。例如,支付的時候,可能需要遠程調用銀聯提供的 API;查詢某個商品的價格,可能需要進行數據庫查詢。然而,這個被依賴服務的穩定性是不能保證的。如果依賴的服務出現了不穩定的情況,請求的響應時間變長,那么調用服務的方法的響應時間也會變長,線程會產生堆積,最終可能耗盡業務自身的線程池,服務本身也變得不可用。
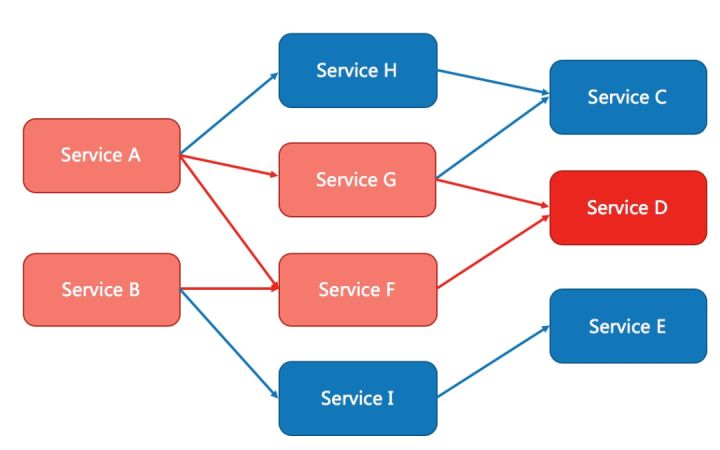
現代微服務架構都是分布式的,由非常多的服務組成。不同服務之間相互調用,組成復雜的調用鏈路。以上的問題在鏈路調用中會產生放大的效果。復雜鏈路上的某一環不穩定,就可能會層層級聯,最終導致整個鏈路都不可用。因此我們需要對不穩定的弱依賴服務進行熔斷降級,暫時切斷不穩定調用,避免局部不穩定因素導致整體的雪崩。
Q:不少同學在問了,那么是不是服務的量級很小就不用進行流量控制限流防護了呢?是不是微服務的架構比較簡單就不用引入熔斷保護機制了呢?
A:其實,這與請求的量級、架構的復雜程度無關。很多時候,可能正是一個非常邊緣的服務出現故障而導致整體業務受影響,造成巨大損失。我們需要具有面向失敗設計的意識,在平時就做好容量規劃和強弱依賴的梳理,合理地配置流控降級規則,做好事前防護,而不是在線上出現問題以后再進行補救。
在流量控制、降級與容錯場景下,我們有多種方式來描述我們的治理方案,下面我將介紹一套開放、通用的、面向分布式服務架構、覆蓋全鏈路異構化生態的服務治理標準 OpenSergo,我們看看 OpenSergo 是如何定義流控降級與容錯的標準,以及支撐這些標準的實現有哪些,能幫助我們解決哪些問題?
OpenSergo 流控降級與容錯 v1alpha1 標準
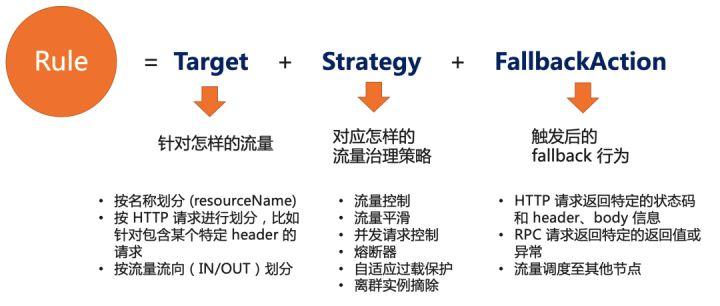
在 OpenSergo 中,我們結合 Sentinel 等框架的場景實踐對流控降級與容錯場景的實現抽象出標準的 CRD。我們可以認為一個容錯治理規則 (FaultToleranceRule) 由以下三部分組成:
- Target: 針對什么樣的請求
- Strategy: 容錯或控制策略,如流控、熔斷、并發控制、自適應過載保護、離群實例摘除等
- FallbackAction: 觸發后的 fallback 行為,如返回某個錯誤或狀態碼
那我們看看針對常用的流控降級場景,OpenSergo 具體的標準定義是什么樣的,他是如何解決我們的問題的?
首先提到的,只要微服務框架適配了 OpenSergo,即可通過統一 CRD 的方式來進行流控降級等治理。無論是 Java 還是 Go 還是 Mesh 服務,無論是 HTTP 請求還是 RPC 調用,還是數據庫 SQL 訪問,我們都可以用這統一的容錯治理規則 CRD 來給微服務架構中的每一環配置容錯治理,來保障我們服務鏈路的穩定性。讓我們來詳細看看OpenSergo在各個具體場景下的一個配置。
流量控制
以下示例定義了一個集群流控的策略,集群總體維度每秒不超過 180 個請求。示例 CR YAML:
這樣一個簡單的 CR 就能給我們的系統配置上一個流量控制的能力,流控能力相當于應用的一個安全氣囊,超出系統服務能力以外的請求將被拒絕,具體邏輯可由我們自定義(如返回指定內容或跳轉頁面)。
熔斷保護
以下示例定義了一個慢調用比例熔斷策略,示例 CR YAML:
這個 CR 的語意就是:在 30s 內請求超過 500ms 的比例達到 60% 時,且請求數達到 5 個,則會自動觸發熔斷,熔斷恢復時長為 5s。
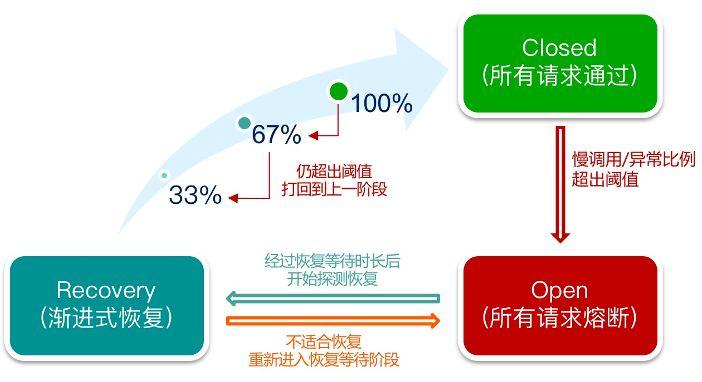
想象一下,在業務高峰期。當某些下游的服務提供者遇到性能瓶頸,甚至影響業務。我們對部分非關鍵服務消費者配置一個這樣的規則,當一段時間內的慢調用比例或錯誤比例達到一定條件時自動觸發熔斷,后續一段時間服務調用直接返回 Mock 的結果,這樣既可以保障調用端不被不穩定服務拖垮,又可以給不穩定下游服務一些“喘息”的時間,同時可以保障整個業務鏈路的正常運轉。
流控降級與容錯標準的實現
Sentinel 介紹
下面介紹一款支持 OpenSergo 流控降級與容錯標準的項目 Sentinel 。
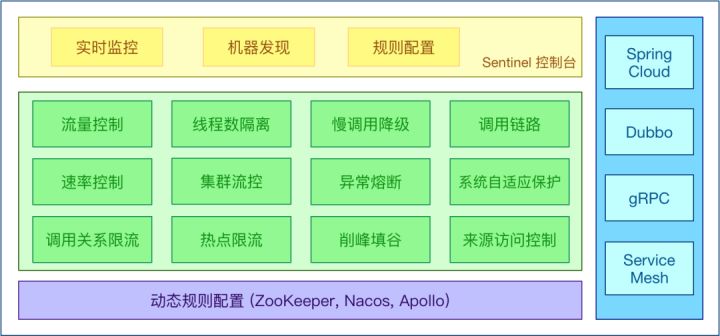
Sentinel 是阿里巴巴開源的,面向分布式服務架構的流量控制組件,主要以流量為切入點,從流量控制、流量整形、熔斷降級、系統自適應保護等多個維度來幫助開發者保障微服務的穩定性。
Sentinel 的技術亮點:
- 高度可擴展能力:基礎核心 + SPI 接口擴展能力,用戶可以方便地擴展流控、通信、監控等功能
- 多樣化的流量控制策略(資源粒度、調用關系、流控指標、流控效果等多個維度),提供分布式集群流控的能力
- 熱點流量探測和防護
- 對不穩定服務進行熔斷降級和隔離
- 全局維度的系統負載自適應保護,根據系統水位實時調節流量
- 覆蓋 API Gateway 場景,為 Spring Cloud Gateway、Zuul 提供網關流量控制的能力
- 云原生場景提供 Envoy 服務網格集群流量控制的能力
- 實時監控和規則動態配置管理能力
一些普遍的使用場景:
- 在服務提供方(Service Provider)的場景下,我們需要保護服務提供方自身不被流量洪峰打垮。這時候通常根據服務提供方的服務能力進行流量控制,或針對特定的服務調用方進行限制。我們可以結合前期壓測評估核心接口的承受能力,配置 QPS 模式的限流,當每秒的請求量超過設定的閾值時,會自動拒絕多余的請求。
- 為了避免調用其他服務時被不穩定的服務拖垮自身,我們需要在服務調用端(Service Consumer)對不穩定服務依賴進行隔離和熔斷。手段包括信號量隔離、異常比例降級、RT 降級等多種手段。
- 當系統長期處于低水位的情況下,流量突然增加時,直接把系統拉升到高水位可能瞬間把系統壓垮。這時候我們可以借助 Sentinel 的 WarmUp 流控模式控制通過的流量緩慢增加,在一定時間內逐漸增加到閾值上限,而不是在一瞬間全部放行。這樣可以給冷系統一個預熱的時間,避免冷系統被壓垮。
- 利用 Sentinel 的勻速排隊模式進行“削峰填谷”,把請求突刺均攤到一段時間內,讓系統負載保持在請求處理水位之內,同時盡可能地處理更多請求。
- 利用 Sentinel 的網關流控特性,在網關入口處進行流量防護,或限制 API 的調用頻率。
阿里云微服務解決方案
在阿里云上提供了一款完全遵循 OpenSergo 微服務標準的企業級產品 MSE,MSE 服務治理的企業版中的流量治理能力我們可以理解為是一個商業化版本的 Sentinel ,我們也簡單總結了一下 MSE 流量治理與社區方案在流控降級與容錯場景下的一個能力對比。

下面我將基于 MSE 來演示一下,如何通過流量控制與熔斷降級來保護我們的系統,可以從容地面對不確定性的流量以及一系列不穩定的場景。
- 配置流控規則
我們可以在監控詳情頁面查看每個接口實時的監控情況。
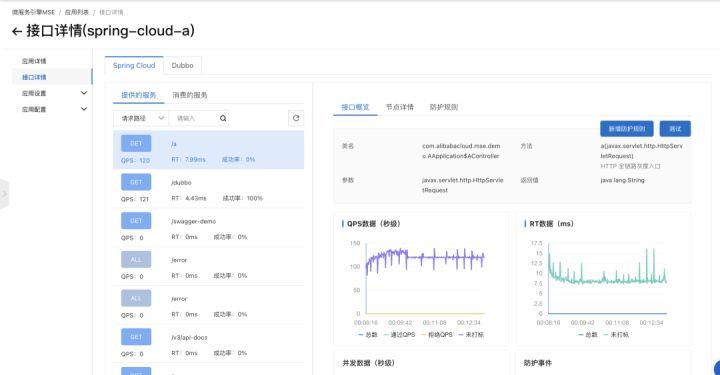
我們可以點擊接口概覽右上角的“新增防護規則”按鈕,添加一條流控規則:
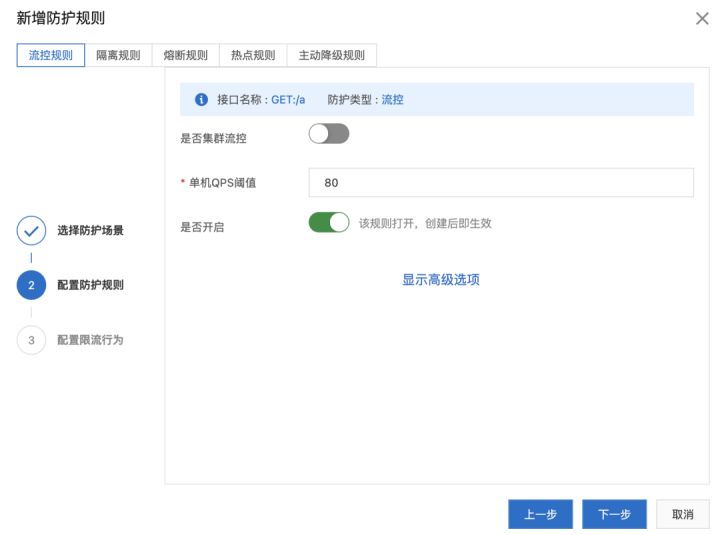
我們可以配置最簡單的 QPS 模式的流控規則,比如上面的例子即限制該接口每秒單機調用量不超過 80 次。
- 監控查看流控效果
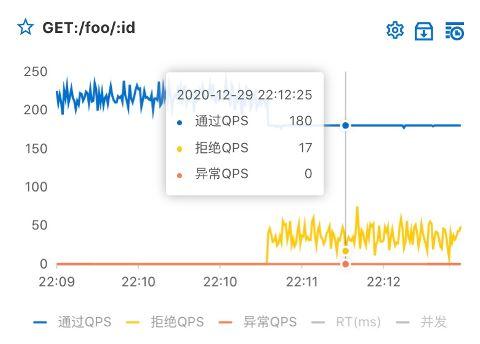
配置規則后,稍等片刻即可在監控頁面看到限流效果:
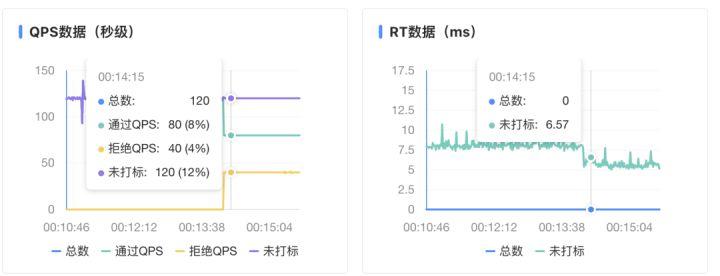
被拒絕的流量也會返回錯誤信息。MSE 自帶的框架埋點都有默認的流控處理邏輯,如 Web 接口被限流后返回 429 Too Many Requests,DAO 層被限流后拋出異常等。若用戶希望更靈活地定制各層的流控處理邏輯,可以通過 SDK 方式接入并配置自定義的流控處理邏輯。
總結
流控降級與容錯是我們設計穩定的微服務系統時不得不考慮的場景,如果我們設計每一套系統都要花許多心思來設計系統的流控降級與容錯能力,這將會成為讓我們每一個開發者都頭疼的問題。那么我們接觸與設計了那么多系統的流控降級,有沒什么通用的場景、最佳實踐、設計標準與規范乃至參考實現可以沉淀的?
本文從場景出發簡單介紹了 OpenSergo 的流量控制與熔斷保護標準,同時也介紹了 Sentinel 流量防護的背景和手段,最后通過示例來介紹如何利用 MSE 服務治理的流量防護能力來為 您的應用保駕護航。