Arctic的湖倉一體踐行之路
本文將系統(tǒng)地介紹 lakehouse、table format 概念,闡述湖倉一體作為數(shù)據(jù)湖流批一體的解決方案,可以發(fā)揮哪些價值。在這個價值驅(qū)動下,我們過去兩年開發(fā)了 arctic 這個流式湖倉服務(wù),并在今年下半年開源。
湖倉一體拓展了數(shù)據(jù)中臺和 dataops 的邊界,讓業(yè)務(wù)基于數(shù)據(jù)湖,數(shù)據(jù)中臺也能做流式更新;實時數(shù)倉,讓數(shù)據(jù)湖能夠具備傳統(tǒng)數(shù)倉,kudu,doris 的能力,為業(yè)務(wù)極大地降本提效。
1.前數(shù)據(jù)湖是什么
數(shù)據(jù)湖這個概念最早由 Pentaho 創(chuàng)始人兼 CTO James Dixon 在 2010 年提出,從當時背景看,這個點子主要是為了推銷自家公司基于 hadoop 的 BI 產(chǎn)品方案,時至今日,雖然 Pentaho 已被日立公司收購,這位大佬也另謀出處,而數(shù)據(jù)湖的含義已遠遠超出原先的定義,經(jīng)過各個大廠,尤其是 AWS,Azure 這類公有云廠商的加持,基于數(shù)據(jù)湖已衍生出非常多樣的工具和方法論。
簡單說,我們可以把數(shù)據(jù)湖當做一個存儲各類結(jié)構(gòu)化、半結(jié)構(gòu)化和非結(jié)構(gòu)化數(shù)據(jù)的池子,這個池子可以是私有化的 hadoop 集群,也可以是云端的對象存儲,因為我們要存儲體量非常大的原始數(shù)據(jù)和明細數(shù)據(jù),這個池子的成本必須足夠低,開啟 EC 的 HDFS 或?qū)ο蟠鎯o疑是最佳選擇。這個大需要多大?我們用 AWS 提供的一張圖來說明:

有了很大的池子存儲原始數(shù)據(jù)和明細數(shù)據(jù),數(shù)據(jù)分析師再也不用擔心數(shù)據(jù)無法溯源,明細丟失的問題,但是按照傳統(tǒng)的 BI 方法論,依然需要將數(shù)據(jù)湖的數(shù)據(jù)導(dǎo)入到數(shù)倉中,才能構(gòu)建出終端想要的數(shù)據(jù)集市,那么為什么我們不能放棄舊框架,直接在數(shù)據(jù)湖上做分析,不是更快更省?
于是乎,數(shù)據(jù)湖開始了紅紅火火的十年,在過去十多年中發(fā)生了很多標志性事件,我們將數(shù)據(jù)湖過去十年的發(fā)展拆為兩個階段:
第一個五年(2010-2015)打地基,像 mapreduce,spark,flink 這些計算引擎讓數(shù)據(jù)湖之上的 ETL,數(shù)據(jù)清洗和加工變得簡單,parquet、orc 這類列存文件格式,impala、presto、trino 這些基于數(shù)據(jù)湖的 OLAP 引擎讓數(shù)據(jù)湖之上的數(shù)據(jù)分析觸手可得。
第二個五年(2015-2020)造建筑,不管是云端還是私有環(huán)境,各種數(shù)據(jù)模型,研發(fā)工具 ,治理平臺玩地風生水起,網(wǎng)易有數(shù)、阿里 Dataworks 都是在這個時期誕生的數(shù)據(jù)中臺產(chǎn)品。總體來看,數(shù)據(jù)湖技術(shù)經(jīng)過五年的打地基,五年的造建筑,目前基于數(shù)據(jù)湖的工具和方法論已經(jīng)非常成熟,比如網(wǎng)易做大數(shù)據(jù)的同學(xué),很多人都接觸過有數(shù),或者直接使用過 hadoop、hive。
與幾十年根基的傳統(tǒng)數(shù)倉相比,數(shù)據(jù)湖近十年發(fā)展歷程可謂占盡天時地利人和,越來越多的企業(yè)在強調(diào)數(shù)字化轉(zhuǎn)型,越來越多的業(yè)務(wù)需要大數(shù)據(jù)幫助決策,此為天時;強大的擴展性,讓任何企業(yè)都可以通過堆機器來應(yīng)對爆炸的數(shù)據(jù)體量,不被任何商業(yè)公司綁架,不管你需不需要數(shù)倉,你可能都需要一個數(shù)據(jù)湖,此為地利;hadoop 開源體系,給用戶帶來了豐富的生態(tài)資源,也給企業(yè)培養(yǎng)了海量的大數(shù)據(jù)人才,大家喜歡開源,此為人和,另外,AI、機器學(xué)習(xí)、數(shù)據(jù)挖掘這類非標業(yè)務(wù)非常依賴生態(tài)資源的加持,數(shù)據(jù)湖在這方面有得天獨厚的優(yōu)勢。
但同時,數(shù)據(jù)湖缺乏標準化的服務(wù),生態(tài)內(nèi)的組件大多各自為戰(zhàn),這帶來了幾個問題:
- 建筑造地累,比如有數(shù)在產(chǎn)品側(cè)需要對接非常多的組件,每個組件都有自己的玩法,架構(gòu)難免臃腫,人效上不去,當然如果產(chǎn)品不做這些事,就得業(yè)務(wù)自己做,人效更低;
- 會導(dǎo)致數(shù)據(jù)沼澤問題,哪些表在給哪些業(yè)務(wù)用,哪些數(shù)據(jù)有浪費,有重復(fù)建設(shè),這些都必須在上層定制方案,基礎(chǔ)設(shè)施這一層缺乏有效的度量和管理支撐,過去企業(yè)分享數(shù)據(jù)中臺效果,動輒節(jié)省一大半的成本,說明數(shù)據(jù)湖之上的沼澤問題是非常嚴重的;
- 對流和實時場景支持有限,因為數(shù)據(jù)湖的生態(tài)中沒有支持行級更新的服務(wù),行業(yè)內(nèi)基本上用數(shù)據(jù)湖做離線數(shù)倉,實時數(shù)倉會選擇其他方案;
- 數(shù)據(jù)質(zhì)量,因為數(shù)據(jù)湖非常開放,并且本身會存很多原始數(shù)據(jù),在數(shù)據(jù)質(zhì)量方面有天然不足,需要上層產(chǎn)品在質(zhì)量保障方面多加考量。
2.火爆的湖倉一體
湖倉一體是個舶來詞,英文叫 lakehouse, 由 databricks 公司首先在2020年3月提出,在 databricks 的理念中,傳統(tǒng)數(shù)據(jù)湖在批計算,AI,機器學(xué)習(xí)等領(lǐng)域有豐富的資源和實踐,但是在流計算,數(shù)據(jù)質(zhì)量和數(shù)據(jù)治理方面相較于傳統(tǒng)數(shù)倉有較大不足,為此 databricks 提供了 lakehouse 平臺,基于數(shù)據(jù)湖之上提供不弱于傳統(tǒng)數(shù)倉的能力,也能享受數(shù)據(jù)湖在 AI,機器學(xué)習(xí),批計算上的積累。
Databricks 作為一家商業(yè)化公司來講 lakehouse 的故事,必然有營銷的成分在,但必須承認 lakehouse 這個概念已經(jīng)深入人心,包括 databricks 的老對手 snowflake,也在講自己是 lakehouse。感興趣的同學(xué)建議看看 Databricks 工程師最早提出 lakehouse 的博客:
What Is a Lakehouse?
說到 lakehouse,就必須提到 table format 的概念,Table format 最早由 iceberg 提出,現(xiàn)在基本成為行業(yè)共識, table format 是什么?簡單概括:
- Table format 定義了哪些文件構(gòu)成一張表,這樣任何引擎都可以根據(jù) table format 查詢和檢索數(shù)據(jù);
- Table format 規(guī)范了數(shù)據(jù)和文件的分布方式,任何引擎寫入數(shù)據(jù)都要遵照這個標準,通過 format 定義的標準支持 ACID,模式演進等高階功能。
目前國內(nèi)外同行將 delta、iceberg 和 hudi 作為數(shù)據(jù)湖 table format 的對標方案,在 databricks 的故事中,delta 是 lakehouse 的存儲底座,所以 table format 和 lakehouse 有非常密切的關(guān)系,我們有理由相信,lakehouse 方案應(yīng)當是基于數(shù)據(jù)湖 table format,涵蓋數(shù)據(jù)研發(fā)和數(shù)據(jù)治理的一整套方案。
湖倉一體有多火,關(guān)注行業(yè)動態(tài)的小伙伴應(yīng)該會有切身感受,比如從今年開始基本上任何有體量的大會、論壇、meetup 都會組織湖倉一體相關(guān)的分會場,我們也能看到各個大廠在這個方向上的積極探索和實踐,在 gartner 發(fā)布 Hype Cycle? for Data Management 權(quán)威報告中,lakehouse 目前處于躍升期位置,相比于成熟期的 deta lakes,lakehouse 未來還有 3-5 年的發(fā)展成熟周期:

還有一份報告值得關(guān)注,在 2021 (2022 的報告還未發(fā)布)最新發(fā)布的數(shù)據(jù)庫魔力象限中,主打 lakehouse 產(chǎn)品的 databricks 和 snowflake 攜手進入領(lǐng)導(dǎo)力第一象限,而去年這份報告中,只有 snowflake 處于挑戰(zhàn)者的位置:

Lakehouse 不光在技術(shù)圈受捧,在資本圈也是鼎鼎有名,巴老爺子加持的 snowflake 千億神話自不必說,databricks 經(jīng)過多輪融資之后,也達到了 380 億美金的估值。就在前不久,delta2.0 完全開源了(過去只開源了一部分)。
3.為什么做 Arctic?
2020 年開始,通過用戶走訪和行業(yè)調(diào)研,我們開始嘗試用 flink + iceberg 打造流批一體數(shù)據(jù)湖的方案,首要的目標是先構(gòu)建存儲的流批統(tǒng)一,在流批一體的數(shù)據(jù)湖之上,再去探索代碼的流批一體,但是在實踐中發(fā)現(xiàn),iceberg 作為 table format,直接拿來匹配流批一體的需求還存在很大的 GAP,arctic 這個項目便是在這個背景下產(chǎn)生的。
3.1 企業(yè)需要湖倉一體
流批一體和湖倉一體是什么關(guān)系,這是過去兩年被問的最多的問題。
簡單說,流批一體是需求,湖倉一體是方案,就好比我說我想吃甜的東西,你拿給我一塊蛋糕,甜是流批一體,蛋糕是湖倉一體。我們可以蛋糕是甜的,但不能是甜的東西就一定是蛋糕,從 lakehouse 提出的背景看,湖倉一體一定是流批一體,但流批一體不一定基于數(shù)據(jù)湖,事實上很多傳統(tǒng)數(shù)倉都具備流批一體的能力。
企業(yè)為什么需要湖倉一體,可以拆成兩個問題:
- 企業(yè)為什么需要流批一體
- 為什么要在數(shù)據(jù)湖上做這個事
我們來看看目前主流的流批共存的架構(gòu)是怎么樣的:

場景中用 hive 做批表,kafka 做流表,實時場景下需要用戶構(gòu)建數(shù)據(jù)庫同步到 hbase 的實時任務(wù),需要用戶實現(xiàn) join hbase 維表的流計算任務(wù),把數(shù)據(jù)寫到支持實時更新的 kudu 中,最后由業(yè)務(wù)根據(jù)實時和離線的需要選擇查詢 kudu 表還是 hive 表,在此之前,用戶需要分別在數(shù)據(jù)模型中建表,使用 kudu 的工具建表,并且自己處理兩個系統(tǒng)的差異。在這個架構(gòu)中,用戶遭受了割裂的體驗,并且需要在上層做很多工作。
在這套 lambda 架構(gòu)中,用戶使用 hive 和離線開發(fā)工具構(gòu)建離線數(shù)倉,使用 kudu,hbase 和實時開發(fā)平臺構(gòu)建實時任務(wù),相同的業(yè)務(wù)邏輯構(gòu)建了兩套數(shù)據(jù)模型,維護兩套數(shù)倉和兩套任務(wù)鏈路,造成人效和資源的浪費,語義的二義性也會給維護帶來更大的成本,對數(shù)據(jù)分析師,算法工程師,數(shù)據(jù)科學(xué)家,去熟悉兩套規(guī)范和工具,理解更多的底層概念也是一項很大的挑戰(zhàn)。比如對網(wǎng)易云音樂而言,數(shù)據(jù)分析師和算法工程師很多,怎樣盡可能提效和降本是一個很有意義的課題,而對一些規(guī)模有限的業(yè)務(wù)團隊,人力緊張,也可能沒有多余的預(yù)算來搭建兩套系統(tǒng),既快且省可能是第一位的訴求。
理解了流批一體的必要性,那么為什么要基于數(shù)據(jù)湖做流批一體?
第一數(shù)據(jù)湖是個兜底的存儲中心,具有極強的彈性伸縮能力,符合“省”的要求,第二過去我們圍繞數(shù)據(jù)湖已經(jīng)搭建了非常豐富的工具,而且現(xiàn)在依然在向 dataops 的方向持續(xù)演進,基于這套方法論也沉淀了非常多的規(guī)范和實踐,如果基于數(shù)據(jù)湖做流批一體,數(shù)據(jù)中臺上的很多能力可以復(fù)用,快速上手,符合業(yè)務(wù)對“快”的需求。
反之如果我們使用其他數(shù)倉做流批一體,比如 doris,相當于在數(shù)據(jù)湖之外又構(gòu)建了一個數(shù)據(jù)孤島,在依然需要數(shù)據(jù)湖的情況下,業(yè)務(wù)需要自己處理 doris 和數(shù)據(jù)湖的傳輸和一致性,沒有從根本上解決問題。
3.2 Table format 不等于湖倉一體
我們從數(shù)據(jù)分析的可用性,數(shù)據(jù)加工的實時性,湖倉的管理三個方面來說明 table format 與我們需要的 lakehouse 之間的 gap。
3.2.1 數(shù)據(jù)分析可用性
與 Hive 相比,delta/iceberg/hudi 最核心的不同是在表格式中抽象出快照的概念,表的任何數(shù)據(jù)變更都會構(gòu)造出新的快照,delta/iceberg/hudi 通過快照的隔離實現(xiàn)數(shù)據(jù)寫入的 ACID 和讀取的 MVCC,更好地支持數(shù)據(jù)實時攝取和計算,如下圖所示:

Table format 是數(shù)據(jù)湖之上比 hive 更進一步的元數(shù)據(jù)封裝,遵循所讀即所寫的原則,而在用戶的讀寫之間應(yīng)當有一個標準化的服務(wù),比如在流和實時場景下,會在數(shù)據(jù)湖中寫入很多碎片文件,這些小文件會導(dǎo)致讀性能的急劇下降,在 chbenchmark中,我們發(fā)現(xiàn)流式寫入 2 小時就會導(dǎo)致 olap 性能下降 1 倍以上,不管是數(shù)據(jù)去重還是小文件合并,我們需要需要一套持續(xù)優(yōu)化的服務(wù)來保障數(shù)據(jù)分析持續(xù)可用。
3.2.2 實時數(shù)據(jù)加工
湖倉一體的特性讓批和流的數(shù)據(jù)加工、數(shù)據(jù)分析、科學(xué)計算、機器學(xué)習(xí)都能在數(shù)據(jù)湖中完成,在這幾個環(huán)節(jié)中,數(shù)據(jù)加工是最基礎(chǔ)的步驟,流批一體的數(shù)據(jù)加工可以讓 BI 和 AI 共享 lakehouse 高人效,低成本,強彈性的紅利。
目前生產(chǎn)環(huán)境中大多使用 hive 和 kafka 分別作為批表和流表選型,實時場景下再搭配 flink 和 kudu 這類支持行級更新的列存數(shù)據(jù)庫做實時數(shù)倉方案,用消息隊列的優(yōu)勢在于毫秒到秒級的數(shù)據(jù)時效性,如果我們用 lakehouse 替換掉 hive 和 kafka,在離線數(shù)倉和批計算上,可以做到平替,但是在實時數(shù)倉和流計算上,由于數(shù)據(jù)湖的增量讀有分鐘級延遲,會出現(xiàn)毫秒/秒級的時效性到分鐘級時效性的降級。而且從實踐上講,以 kafka 或 pulsar 作為流表實現(xiàn)更加成熟,這令數(shù)據(jù)湖在實時加工鏈路中天然吸引不足。
在大量用戶調(diào)研后,我們發(fā)現(xiàn)用戶大多能接受數(shù)據(jù)分析分鐘級別的時效性,但對端到端的處理延遲有更高的要求,尤其對數(shù)據(jù)開發(fā)同學(xué),KPI 指標可能是構(gòu)建的數(shù)據(jù)建設(shè)的復(fù)用度,低時效性的數(shù)據(jù)處理可能喪失對更多場景的吸引,同時面對復(fù)雜的數(shù)據(jù)分層場景,會讓端到端的延遲更加不可控。
另一個實時數(shù)據(jù)加工的問題是維表關(guān)聯(lián),就是我們俗稱打?qū)挼膱鼍埃谏衔牡?lambda 架構(gòu)中,當用戶需要維表關(guān)聯(lián)時,往往需要引入一套 hbase 或 redis 這樣的 KV 系統(tǒng),數(shù)據(jù)開發(fā)同學(xué)、算法工程師不光要耗時耗力學(xué)習(xí)和使用 kv,還需要自己構(gòu)建數(shù)據(jù)庫到 kv 的同步,接收和處理這些同步任務(wù)的報警,處理 kv 數(shù)據(jù)的序列化反序列化,嚴重降低了數(shù)據(jù)開發(fā)和算法工程師的幸福度。
在 databricks 的理念中,lakehouse 能做到開箱即用的流批一體,但顯然用戶期望的流批一體和 delta、iceberg 這類 table format 之間還有較大的 gap,用戶對 lakehouse 的期望既要兼顧到端到端的延遲,數(shù)據(jù)打?qū)挄r也要能像離線 join 一樣做到即插即用。
3.2.3 怎么做湖倉管理
上文提到,小文件是典型的湖倉管理要解決的問題,過多的小文件會讓 OLAP 性能下降,HDFS 的 NN 不堪重負。而當我們在數(shù)據(jù)湖之上構(gòu)建更多的實時數(shù)倉,會面臨更多成本、時效性和性能的管理需求:
- 表的時效性怎么量化,是否達到用戶預(yù)期?
- 湖倉表當前的查詢性能有多少可優(yōu)化空間?
- 數(shù)據(jù)優(yōu)化的資源怎樣量化,怎樣最大化利用?
- 怎樣靈活分配資源,為高優(yōu)先調(diào)度資源?
區(qū)別于 MPP 架構(gòu)的傳統(tǒng)數(shù)倉,湖倉是個天然存算分離,彈性伸縮的架構(gòu),過去部署一套 greenplum,部署了幾臺機器,就用幾臺機器,如果發(fā)現(xiàn)容量或性能不足,就去擴容,數(shù)據(jù)遷移。對這種傳統(tǒng)存算一體的架構(gòu),對應(yīng)的管理系統(tǒng)目標是盡可能把內(nèi)部的運作黑盒化,對外提供一些度量和指標來衡量系統(tǒng)的健康度或性能。
而在湖倉中,首先這套管理系統(tǒng)是缺失的,hive 以及現(xiàn)在的數(shù)據(jù)湖 table format 歸根到底只是定義了表在數(shù)據(jù)湖上的元數(shù)據(jù)形態(tài),并沒有動態(tài)的湖倉管理機制,其次如果我們想做一套湖倉管理系統(tǒng),思路和存算一體的 MPP 數(shù)據(jù)庫也會有所區(qū)別,比如湖倉在后臺進行的數(shù)據(jù)優(yōu)化動作,用戶需要為這些彈性的優(yōu)化行為花錢,而這個錢會直接作用在湖倉的時效性和性能上,存算分離的管理系統(tǒng)需要為用戶更加透明地梳理好時效性,性能,成本之間的關(guān)系:

這套湖倉管理系統(tǒng),需要在保障性能、可用性的前提下,利用好數(shù)據(jù)湖彈性伸縮的能力幫助用戶最大限度降本,為用戶花出去的每分錢負責。
4.Arctic 是什么
我們聊了企業(yè)為什么需要流批一體和湖倉一體,也聊到了 table format 和湖倉一體之間的 GAP,生產(chǎn)場景中會存在的需求和問題,Arctic 便是我們團隊對這些需求和問題的答案。
Arctic 目前已經(jīng)開源,我們對 arctic 目前的定位是流式湖倉服務(wù),是基于 lakehouse 開箱即用的流批一體服務(wù),流式強調(diào)在數(shù)據(jù)湖之添加了更多實時的能力,如更加優(yōu)化的 CDC 攝取,流式更新,生產(chǎn)可用的實時合并,對用戶無感的流式數(shù)據(jù)自優(yōu)化等,服務(wù)強調(diào) arctic 是搭建在 table format 之上的管理服務(wù),如上文所屬,arctic 管理服務(wù)聚焦在為用戶梳理時效性,性能以及成本之間的關(guān)系,幫助用戶做好容量規(guī)劃,數(shù)據(jù)管理和治理。目前 arctic 是搭建在 iceberg 之上,理論上說,arctic 未來也可以基于 delta 和 hudi。
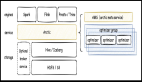
Arctic 架構(gòu)如下圖所示:

可以看到,Arctic 的核心組件包含 AMS 和 Optimizer,在 arctic 中,AMS 被定義為新一代 HMS,AMS 管理 Arctic 所有 schema,向計算引擎提供元數(shù)據(jù)服務(wù)和事務(wù) API,以及負責觸發(fā)后臺結(jié)構(gòu)優(yōu)化任務(wù)。
Arctic 作為流式湖倉服務(wù),會在后臺持續(xù)進行文件結(jié)構(gòu)優(yōu)化操作,并致力于這些優(yōu)化任務(wù)的可視化和可測量,優(yōu)化操作包括但不限于小文件合并,數(shù)據(jù)分區(qū),數(shù)據(jù)在 Tablestore 之間的合并轉(zhuǎn)化。
Optimizer container 是 optimizing 任務(wù)調(diào)度的容器,目前生產(chǎn)環(huán)境主要是在 yarn 上調(diào)度,支持擴展 optimizer container 實現(xiàn)調(diào)度到 k8s 或其平臺。Optimizer group 用于資源隔離,optimizing container 下可以設(shè)置一個或多個 optimizer group,也可以通過 optimizer group 實現(xiàn)優(yōu)先級的功能,在 yarn 上 optimizer container 對應(yīng)隊列。
篇幅關(guān)系不再對 arctic 的架構(gòu)與概念進一步展開,感興趣的同學(xué)可以移步我們的文檔,后續(xù)我也會在其他的文章里聊聊 arctic 在架構(gòu)設(shè)計中的考量,與其他產(chǎn)品的差異。
5.能用 Arctic 做什么?
Arctic 的目標是開箱即用的流批一體:

與原先流批割裂的 lambda 架構(gòu)相比,arctic 用存儲統(tǒng)一了數(shù)據(jù)生產(chǎn)的鏈路,arctic 表既可以作為離線表給 spark 用,也可以作為流表給 flink 用,還可以用 impala/trino 的 OLAP 引擎查詢 arctic 表,構(gòu)建數(shù)據(jù)集市。值得一提的是,arctic 的流表能夠做到毫秒到秒級,arctic 將用戶需要的消息隊列,作為 broker service 封裝到 arctic 的管理體系里,用戶只需要在創(chuàng)建表的時候指定是否需要引入隊列,在后續(xù)的使用中即可透明無感地用到消息隊列實時分發(fā)的能力,arctic 在對接 flink 的 connector 中,封裝了消息隊列與數(shù)據(jù)湖的雙寫和一致性保障。
在 AP 性能上,arctic 通過 optimizer 機制實現(xiàn)表的結(jié)構(gòu)自優(yōu)化,在我們的 benchmark 測試中,流式寫入 iceberg 表 1 個小時以后,因為小文件問題,以及一些不完善,性能下降會非常厲害,1.5 小時候數(shù)據(jù)已經(jīng)跑不出來了,arctic 的平均延遲維持在 20s 左右,而 hudi 30s 左右(平均延遲越小,性能越好),詳細的 benchmark 報告可以移步:https://arctic.netease.com/ch/benchmark/

Arctic 流批一體的能力可以拓展數(shù)據(jù)中臺,或 dataops 的邊界,更直觀點說,用戶可以直接用各種有數(shù)的中臺工具來實現(xiàn)流批一體,比如今年我們在幫有道做的替換 doris,和傳媒一起做的替換 clickhouse,業(yè)務(wù)在使用之前的系統(tǒng)時,缺乏高效率的工具,還要為這些獨立部署的資源買單,切到 arctic 之后,由于數(shù)據(jù)湖高度彈性的能力,和低成本的特性,可以給用戶省錢提效。
Arctic 不光可以用在大數(shù)據(jù)場景,今年調(diào)研發(fā)現(xiàn),在線業(yè)務(wù)也有一些需要存儲大體量的歷史數(shù)據(jù),或者 AP 和 TP 混用的場景,比如風控場景需要存儲非常多日志清洗后的數(shù)據(jù),而這些數(shù)據(jù)全部存儲在 ES 里成本會失控,我們和云音樂團隊一起做了一個數(shù)據(jù)湖與 ES 混合使用的方案,數(shù)據(jù)湖來兜底,會存儲非常久的數(shù)據(jù),并且是實時入湖,在我們測量下,用數(shù)據(jù)湖來實現(xiàn)冷熱分離,占用的空間小 XX 倍,成本上則帶來幾十倍的提升。
6.期望與規(guī)劃
要做到開箱即用的流批一體,arctic 還有不少的工作要做。
比如不依賴外部 kv 的維表關(guān)聯(lián),在前不久發(fā)布的 arctic v0.3.1 版本中,我們發(fā)布了這項功能的 beta 版本,在一些維表不是很大的場景下,可以做到生產(chǎn)可用,未來還需要做哪些優(yōu)化工作,已經(jīng)在 roadmap 里,再比如 inline upsert 功能,讓 flink 任務(wù)可以流式更新大寬表中的部分列,從而代替狀態(tài)過大的多流 join,這兩個是我們今年在流場景下想要重點打造的功能。完整的 roadmap 記錄在 這里 。
在批場景,我們已經(jīng)支持了相當一部分業(yè)務(wù),通過 spark 的讀時合并讓業(yè)務(wù)能夠獨到準實時的數(shù)據(jù),用戶也可以通過有數(shù)提供的 impala 對接 arctic 實現(xiàn)分鐘級時效性的實時數(shù)倉,用 trino 的用戶,可以將 arctic 的 trino connector 集成到自己的 trino 集群中,我們的小伙伴會做好對接工作。
未來 arctic 也將不斷豐富管理功能(這塊在 lakehouse 領(lǐng)域還比較空白),arctic 作為網(wǎng)易數(shù)帆重點打造的一個開源項目,非常歡迎內(nèi)外部的開發(fā)者能夠關(guān)注、使用和參與,一起打造行業(yè)領(lǐng)先的湖倉管理系統(tǒng),未來一年我們極有可能嘗試在 apache 孵化。