首個在ImageNet上精度超過80%的二值神經(jīng)網(wǎng)絡(luò)BNext問世,-1與+1的五年辛路歷程
兩年前,當 MeliusNet 問世時,機器之心曾發(fā)表過一篇技術(shù)文章《??第一次勝過 MobileNet 的二值神經(jīng)網(wǎng)絡(luò),-1 與 + 1 的三年艱苦跋涉???》,回顧了 BNN 的發(fā)展歷程。彼時,依靠早期 BNN 工作 XNOR-Net 起家的 XNOR.AI 被蘋果公司收購,大家曾暢想過這種低功耗、高效能的二值神經(jīng)網(wǎng)絡(luò)技術(shù)會不會即將開啟廣闊的應(yīng)用前景。
然而,過去的兩年時間,我們很難從對技術(shù)嚴格保密的蘋果公司獲得關(guān)于 BNN 技術(shù)應(yīng)用的更多信息,而不論是學界和業(yè)界也未出現(xiàn)其他特別亮眼的應(yīng)用案例。另一方面,隨著終端設(shè)備數(shù)量的暴漲,邊緣 AI 應(yīng)用和市場正在迅速增長: 預計到 2030 年將產(chǎn)生 500 到 1250 億臺邊緣設(shè)備,邊緣計算市場將暴漲到 600 億美元規(guī)模。這其中有幾個目前熱門的應(yīng)用領(lǐng)域:AIoT、元宇宙和機器人終端設(shè)備。相關(guān)業(yè)界正在加速發(fā)力技術(shù)落地,與此同時 AI 能力已經(jīng)嵌入到以上領(lǐng)域的諸多核心技術(shù)環(huán)節(jié)中,如 AI 技術(shù)在三維重建、視頻壓縮以及機器人實時感知場景中的廣泛應(yīng)用。在這樣的背景下,業(yè)界對基于邊緣的高能效、低功耗 AI 技術(shù)、軟件工具以及硬件加速的需求變的日益迫切。
目前,制約 BNN 應(yīng)用的瓶頸主要有兩方面:首先,無法有效縮小和傳統(tǒng) 32-bit 深度學習模型的精度差距;第二則是缺乏在不同硬件上的高性能算法實現(xiàn)。機器學習論文上的加速比通常無法體現(xiàn)在你正在使用的 GPU 或 CPU 上。第二個原因的產(chǎn)生可能正是來自于第一個原因,BNN 無法達到令人滿意的精度,因此無法吸引來自系統(tǒng)和硬件加速、優(yōu)化領(lǐng)域的從業(yè)者的廣泛關(guān)注。而機器學習算法社區(qū)通常無法自己開發(fā)高性能的硬件代碼。因此,想要同時獲得高精度和強加速效果,BNN 應(yīng)用或加速器無疑需要來自這兩個不同領(lǐng)域的開發(fā)者進行協(xié)作。
BNN 為什么對于計算和內(nèi)存高效
舉個例子,Meta 推薦系統(tǒng)模型 DLRM 使用 32-bit 浮點數(shù)來儲存權(quán)重和激活參數(shù),它的模型大小約為 2.2GB。而一個少量精度下降 (<4%) 的二值版本模型的大小僅為 67.5MB,由此可見二值神經(jīng)網(wǎng)絡(luò)可以節(jié)省 32 倍的模型大小。這對于儲存受限的邊緣設(shè)備來說具備了非常強的優(yōu)勢。此外,BNN 也非常適合應(yīng)用在分布式 AI 場景中,例如聯(lián)邦學習常常對模型權(quán)重進行傳輸和聚合操作,因此模型大小和帶寬受限往往成為整個系統(tǒng)的瓶頸。常用的手段是通過增加模型本地優(yōu)化迭代次數(shù)來換取權(quán)重傳輸頻率的降低,用這種折中的方法來提升整體效率,如著名的谷歌 FedAvg 算法。但增大本地計算量的策略對端側(cè)用戶并不友好,這里,如果采用 BNN 就可以很輕易的降低幾十倍的數(shù)據(jù)傳輸量。
BNN 的第二個顯著的優(yōu)勢是計算方式極度高效。它只用 1bit 也就是兩種 state 來表示變量。這意味著所有運算只靠位運算就能完成,借助與門、異或門等運算,可以替代傳統(tǒng)乘加運算。位運算是電路中的基礎(chǔ)單元,熟悉電路設(shè)計的同學應(yīng)該明白,有效減小乘加計算單元的面積以及減少片外訪存是降低功耗的最有效手段,而 BNN 從內(nèi)存和計算兩個方面都具備得天獨厚的優(yōu)勢,WRPN[1]展示了在定制化 FPGA 和 ASIC 上,BNN 對比全精度可獲得 1000 倍的功耗節(jié)省。更近期的工作 BoolNet [2]展示了一種 BNN 結(jié)構(gòu)設(shè)計可以幾乎不使用浮點運算并保持純 binary 的信息流,它在 ASIC 仿真中獲得極佳的功耗、精度權(quán)衡。
第一個精度上 80% 的 BNN 是什么樣子的?
來自德國 Hasso Plattner 計算機系統(tǒng)工程研究院的 Nianhui Guo 和 Haojin Yang 等研究者提出了 BNext 模型,成為第一個在 ImageNet 數(shù)據(jù)集上 top1 分類準確率突破 80% 的 BNN:

圖 1 基于 ImageNet 的 SOTA BNN 性能對比

論文地址:https://arxiv.org/pdf/2211.12933.pdf
作者首先基于 Loss Landscape 可視化的形式深入對比了當前主流 BNN 模型同 32-bit 模型在優(yōu)化友好度方面的巨大差異 (圖 2),提出 BNN 的粗糙 Loss Landscape 是阻礙當前研究社區(qū)進一步探索 BNN 性能邊界的的主要原因之一。
基于這一假設(shè),作者嘗試利用新穎的結(jié)構(gòu)設(shè)計對 BNN 模型優(yōu)化友好度進行提升,通過構(gòu)造具備更平滑 Loss Landscape 的二值神經(jīng)網(wǎng)絡(luò)架構(gòu)以降低對高精度 BNN 模型的優(yōu)化難度。具體而言,作者強調(diào)模型二值化大幅度限制了可用于前向傳播的特征模式,促使二值卷積僅能在有限的特征空間進行信息提取與處理,而這種受限前饋傳播模式帶來的優(yōu)化困難可以通過兩個層面的結(jié)構(gòu)設(shè)計得到有效緩解:(1) 構(gòu)造靈活的鄰接卷積特征校準模塊以提高模型對二值表征的適應(yīng)性;(2) 探索高效的旁路結(jié)構(gòu)以緩解前饋傳播中由于特征二值化帶來的信息瓶頸問題。

圖 2 針對流行 BNN 架構(gòu)的 Loss Landscape 可視化對比(2D 等高線視角)
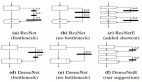
基于上述分析,作者提出了 BNext,首個在 ImageNe 圖像分類任務(wù)達到 > 80% 準確率的二值神經(jīng)網(wǎng)絡(luò)架構(gòu),具體的網(wǎng)絡(luò)架構(gòu)設(shè)計如圖 4 所示。作者首先設(shè)計了基于 Info-Recoupling (Info-RCP) 模塊的基礎(chǔ)二值處理單元。針對鄰接卷積間的信息瓶頸問題,通過引入額外的 Batch Normalization 層與 PReLU 層完成對二值卷積輸出分布的初步校準設(shè)計。接著作者構(gòu)造了基于逆向殘差結(jié)構(gòu)與 Squeeze-And-Expand 分支結(jié)構(gòu)的二次動態(tài)分布校準設(shè)計。如圖 3 所示,相比傳統(tǒng)的 Real2Binary 校準結(jié)構(gòu),額外的逆向殘差結(jié)構(gòu)充分考慮了二值單元輸入與輸出間的特征差距,避免了完全基于輸入信息的次優(yōu)分布校準。這種雙階段的動態(tài)分布校準可以有效降低后續(xù)鄰接二值卷積層的特征提取難度。

圖 3 卷積模塊設(shè)計對比圖
其次,作者提出結(jié)合 Element-wise Attention (ELM-Attention) 的增強二值 Basic Block 模塊。作者通過堆疊多個 Info-RCP 模塊完成 Basic Block 的基礎(chǔ)搭建,并對每個 Info-RCP 模塊引入額外的 Batch Normalization 和連續(xù)的殘差連接以進一步緩解不同 Info-RCP 模塊間的信息瓶頸問題。基于旁路結(jié)構(gòu)對二值模型優(yōu)化影響的分析, 作者提出使用 Element-wise 矩陣乘法分支對每個 Basic Block 的首個 3x3 Info-RCP 模塊輸出進行分布校準。額外的空域注意力加權(quán)機制可以幫助 Basic Block 以更靈活的機制進行前向信息融合與分發(fā),改善模型 Loss Landscape 平滑度。如圖 2.e 和圖 2.f 所示,所提出的模塊設(shè)計可以顯著改善模型 Loss Landscape 平滑度。

圖 4 BNext 架構(gòu)設(shè)計。"Processor 代表 Info-RCP 模塊,"BN "代表 Batch Normalization 層,"C "表示模型基本寬度,"N "和"M " 表示模型不同階段的深度比例參數(shù)。

Table 1 BNext 系列。“Q”表示輸入層、SEbranch以及輸出層量化設(shè)置。
作者將以上結(jié)構(gòu)設(shè)計同流行的MoboleNetv1基準模型結(jié)合,并通過改變模型深度與寬度的比例系數(shù)構(gòu)建了四種不同復雜度的 BNext 模型系列 (Table 1):BNex-Tiny,BNext-Small,BNext-Middle,BNext-Large。
由于相對粗糙的 Loss Landscape,當前二值模型優(yōu)化普遍依賴于 knowledge distillation 等方法提供的更精細監(jiān)督信息,以此擺脫廣泛存在的次優(yōu)收斂。BNext作者首次考慮了優(yōu)化過程中teache模型與二值student模型預測分布巨大差距可能帶來的影響,,指出單純基于模型精度進行的 teacher 選擇會帶來反直覺的 student 過擬合結(jié)果。為解決這一問題,作者提出了 knowledge-complexity (KC) 作為新的 teacher-selection 度量標準,同時考慮 teacher 模型的輸出軟標簽有效性與 teacher 模型參數(shù)復雜度之間的關(guān)聯(lián)性。

如圖 5 所示,基于 knowledge complexity,作者對流行全精度模型系列如 ResNet、EfficientNet、ConvNext 進行了復雜度度量與排序,結(jié)合 BNext-T 作為 student 模型初步驗證了該度量標準的有效性,并基于排序結(jié)果用于后續(xù)實驗中的 knowledge distillation 模型選擇。

圖 5 反直覺的過擬合效應(yīng)和不同教師選擇下的知識復雜性影響
在此基礎(chǔ)上,論文作者進一步考慮了強 teacher 優(yōu)化過程中由于早期預測分布差距造成的優(yōu)化問題,提出 Diversified Consecutive KD。如下所示,作者通過強弱 teachers 組合的知識集成方法對優(yōu)化過程中的目標函數(shù)進行調(diào)制。在此基礎(chǔ)上,進一步引入 knowledge-boosting 策略,利用多個預定義候選 teachers 在訓練過程中對弱 teacher 進行均勻切換,將組合知識復雜度按照從弱到強的順序進行課程式引導,降低預測分布差異性帶來的優(yōu)化干擾。

在優(yōu)化技巧方面,BNext 作者充分考慮了現(xiàn)代高精度模型優(yōu)化中數(shù)據(jù)增強可能帶來的增益,并提供了首個針對現(xiàn)有流行數(shù)據(jù)增強策略在二值模型優(yōu)化中可能帶來影響的分析結(jié)果,實驗結(jié)果表明,現(xiàn)有數(shù)據(jù)增強方法并不完全適用于二值模型優(yōu)化,這為后續(xù)研究中特定于二值模型優(yōu)化的數(shù)據(jù)增強策略設(shè)計提供了思路。
基于所提出架構(gòu)設(shè)計與優(yōu)化方法,作者在大規(guī)模圖像分類任務(wù) ImageNet-1k 進行方法驗證。實驗結(jié)果如圖 6 所示。

圖 6 基于 ImageNet-1k 的 SOTA BNN 方法比較。
相比于現(xiàn)有方法,BNext-L 在 ImageNet-1k 上首次將二值模型的性能邊界推動至 80.57%,對大多數(shù)現(xiàn)有方法實現(xiàn)了 10%+ 的精度超越。相比于來自 Google 的 PokeBNN, BNext-M 在相近參數(shù)量前提下要高出 0.7%,作者同時強調(diào),PokeBNN 的優(yōu)化依賴于更高的計算資源,如高達 8192 的 Bacth Size 以及 720 個 Epoch 的 TPU 計算優(yōu)化,而 BNext-L 僅僅以常規(guī) Batch Size 512 迭代了 512 個 Epoch,這反映了 BNext 結(jié)構(gòu)設(shè)計與優(yōu)化方法的有效性。在基于相同基準模型的比較中,BNext-T 與 BNext-18 都有著大幅度的精度提升。在同全精度模型如 RegNetY-4G (80.0%)等的對比中,BNext-L 在展現(xiàn)相匹配的視覺表征學習能力同時,僅僅使用了有限的參數(shù)空間與計算復雜度,這為在邊緣端部署基于二值模型特征提取器的下游視覺任務(wù)模型提供了豐富想象空間。
What next?
BNext 作者在論文中提到的,他們和合作者們正積極在 GPU 硬件上實現(xiàn)并驗證這個高精度 BNN 架構(gòu)的運行效率,未來計劃擴展到其他更廣泛的硬件平臺上。然而在編者看來,讓社區(qū)對 BNN 重拾信心,被更多系統(tǒng)和硬件領(lǐng)域的極客關(guān)注到,也許這個工作更重要的意義在于重塑了 BNN 應(yīng)用潛力的想象空間。從長遠來看,隨著越來越多的應(yīng)用從以云為中心的計算范式向去中心化的邊緣計算遷移,未來海量的邊緣設(shè)備需要更加高效的 AI 技術(shù)、軟件框架和硬件計算平臺。而目前最主流的 AI 模型和計算架構(gòu)都不是為邊緣場景設(shè)計、優(yōu)化的。因此,在找到邊緣 AI 的答案之前,相信 BNN 始終都會是一個充滿技術(shù)挑戰(zhàn)又蘊涵巨大潛力的重要選項。