人工智能:語音合成技術介紹
作者:郝光明
語音合成簡單來說就是把文字信息轉換為標準語音的過程,最終可以輸出對應的音頻文件。可以實現讓機器像人類一樣可以實時的說話。涉及的領域有聲學、語言學、數字信號處理、計算機管理等方面的知識。
1、語音合成概念介紹
語音合成簡單來說就是把文字信息轉換為標準語音的過程,最終可以輸出對應的音頻文件。可以實現讓機器像人類一樣可以實時的說話。涉及的領域有聲學、語言學、數字信號處理、計算機管理等方面的知識。
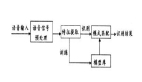
2、語音合成的過程
主要包括:獲取輸入的文本→語言處理→韻律處理→聲學處理→輸出音頻文件。其中語音識別主要是語言處理、韻律處理、聲學處理三個階段的操作。
2.1 語言處理
該階段主要是模擬人類對大自然語言理解的過程,主要工作有輸入文本分析、分詞、語義分析,目的是讓計算機能夠盡可能準確理解輸入文本的含義并為后面的環節做準備。
2.2 韻律處理
主要是為合成的語音規劃出音高、音長、音強等語音特征,目的是為了讓合成的語音能表達確切的語意,使得輸出的音頻文件更符合實際。
2.3 聲學處理
這個階段主要是把前兩個階段處理結果合成最終的音頻文件。
3、語音合成使用場景
3.1 智能服務方面
智能服務方面主要包括語音機器人、智能音響等設備。通過語音合成語音可以輸出形形色色的聲音,比如甜美親切的銀行導航機器人;呆萌可愛的早教機器人;智能音響也極大豐富了我們的日常生活比如通知智能音響可以播放歌曲、相聲、新聞、講故事等實用功能。
3.2 APP應用方面
手機APP應用就更加廣泛了,比如手機閱讀器的聽書功能、地圖的導航播報功能、手機自帶的語音助手、視頻剪輯通過文字直接轉換音頻文件等方面應用非常廣泛。

責任編輯:武曉燕
來源:
IT技術分享社區