













什么是分布式數據庫?聊聊它的前世今生
?在互聯網技術發展的今天,相信大家都對分布式數據庫表示出了濃厚的興趣,并且不約而同地問了我這樣一個問題:啥是分布式數據庫?更有“愛好學習”的朋友希望借此展現出“勤學好問”的品德,進而補充道:“這是哪個大廠出的產品?”
好吧,我的朋友,你們真的戳中了我的笑點。但笑一笑后,我不禁陷入了思考:為什么分布式數據庫在大眾,甚至專業領域內認知如此之低呢?
原因我大概可以總結為兩點:數據庫產品特點與商業氛圍。
首先,數據庫產品的特點是抽象度高。用戶一般僅僅從使用層面接觸數據庫,知道數據庫能實現哪些功能,而不關心或者很難關心其內部原理。而一些類型的分布式數據庫的賣點正是這種抽象能力,從而使用戶覺得應用這種分布式化的數據庫與傳統單機數據庫沒有明顯的差別,甚至更加簡單。
其次,數據庫的商業氛圍一直很濃厚。數據庫產品高度抽象且位置關鍵,這就天然成為資本追逐的領地。而商業化產品和服務的賣點就是其包含支撐服務,而且許多商業數據庫最賺錢的部分就是提供該服務。因此這些產品有意無意地對終端用戶掩蓋了數據庫的技術細節,而用戶有了這層商業保障,也很難有動力去主動了解內部原理。
這就造成即使你工作中接觸了分布式數據庫,也沒有意識到它與過去的數據庫有什么不同。但“福報遲到,但不會缺席”——當由于對其原理缺乏必要認識,導致技術問題頻發時,用戶才會真正意識到它們好像類似,但本質卻截然不同。
而隨著分布式數據庫逐步滲透到各個領域,用戶再也不能“傻瓜式”地根據特性選擇數據庫產品了。新架構催生出來的新特性,促使使用者需要深入參與其中,并需要他們認真評估數據庫技術特點,甚至要重新設計自己的產品來與之更好地結合。
我是“歷史決定論”的忠實簇擁者,我會沿著分布式數據庫的發展脈絡來介紹它。相信你在讀完后,會對一開始的那個問題有自己的答案。那么現在我們從基本概念開始說起。
基本概念
分布式數據庫,從名字上可以拆解為:分布式+數據庫。用一句話總結為:由多個獨立實體組成,并且彼此通過網絡進行互聯的數據庫。
理解新概念最好的方式就是通過已經掌握的知識來學習,下表對比了大家熟悉的分布式數據庫與集中式數據庫之間主要的 5 個差異點。
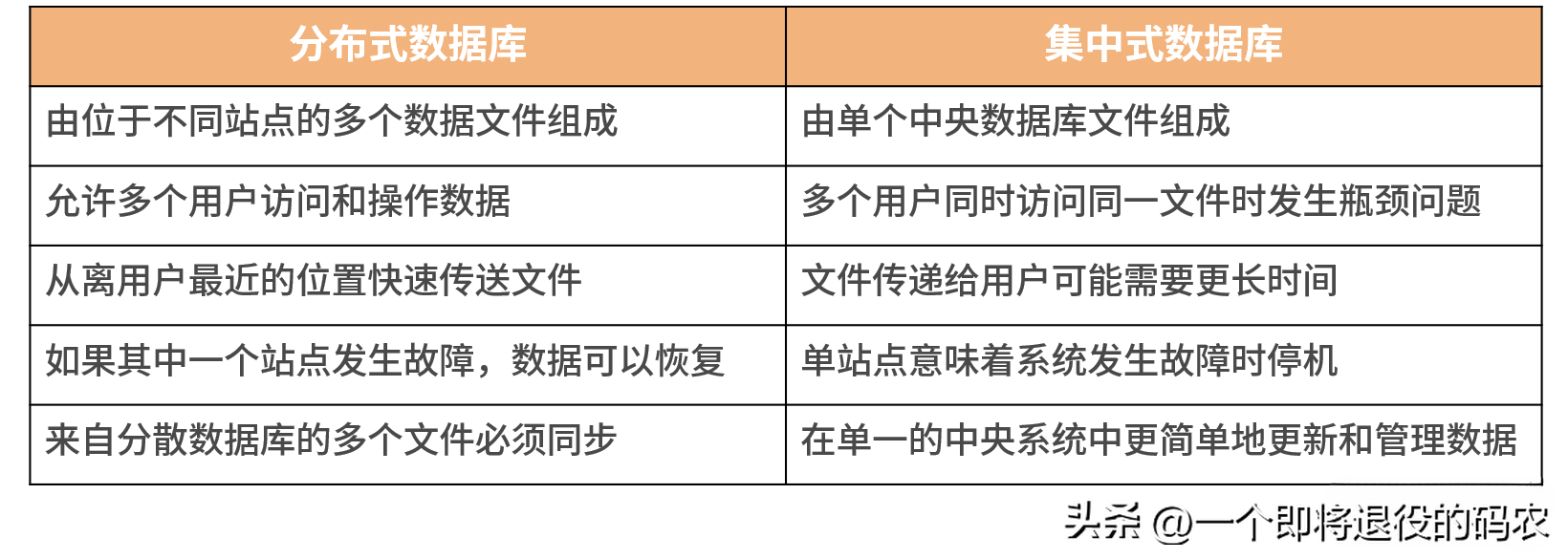
從表中,我們可以總結出分布式數據庫的核心——數據分片、數據同步。
1. 數據分片
該特性是分布式數據庫的技術創新。它可以突破中心化數據庫單機的容量限制,從而將數據分散到多節點,以更靈活、高效的方式來處理數據。這是分布式理論帶給數據庫的一份禮物。
分片方式包括兩種。
水平分片:按行進行數據分割,數據被切割為一個個數據組,分散到不同節點上。
垂直分片:按列進行數據切割,一個數據表的模式(Schema)被切割為多個小的模式。
2. 數據同步
它是分布式數據庫的底線。由于數據庫理論傳統上是建立在單機數據庫基礎上,而引入分布式理論后,一致性原則被打破。因此需要引入數據庫同步技術來幫助數據庫恢復一致性。
簡而言之,就是使分布式數據庫用起來像“正常的數據庫”。所以數據同步背后的推動力,就是人們對數據“一致性”的追求。這兩個概念相輔相成,互相作用。
當然分布式數據庫還有其他特點,但把握住以上兩點,已經足夠我們理解它了。下面我將從這兩個特性出發,探求技術史上分布式數據庫的發展脈絡。我會以互聯網、云計算等較新的時間節點來進行斷代劃分,畢竟我們的核心還是著眼現在、面向未來。
商業數據庫
互聯網浪潮之前的數據庫,特別是前大數據時代。談到分布式數據庫繞不開的就是 Oracle RAC。
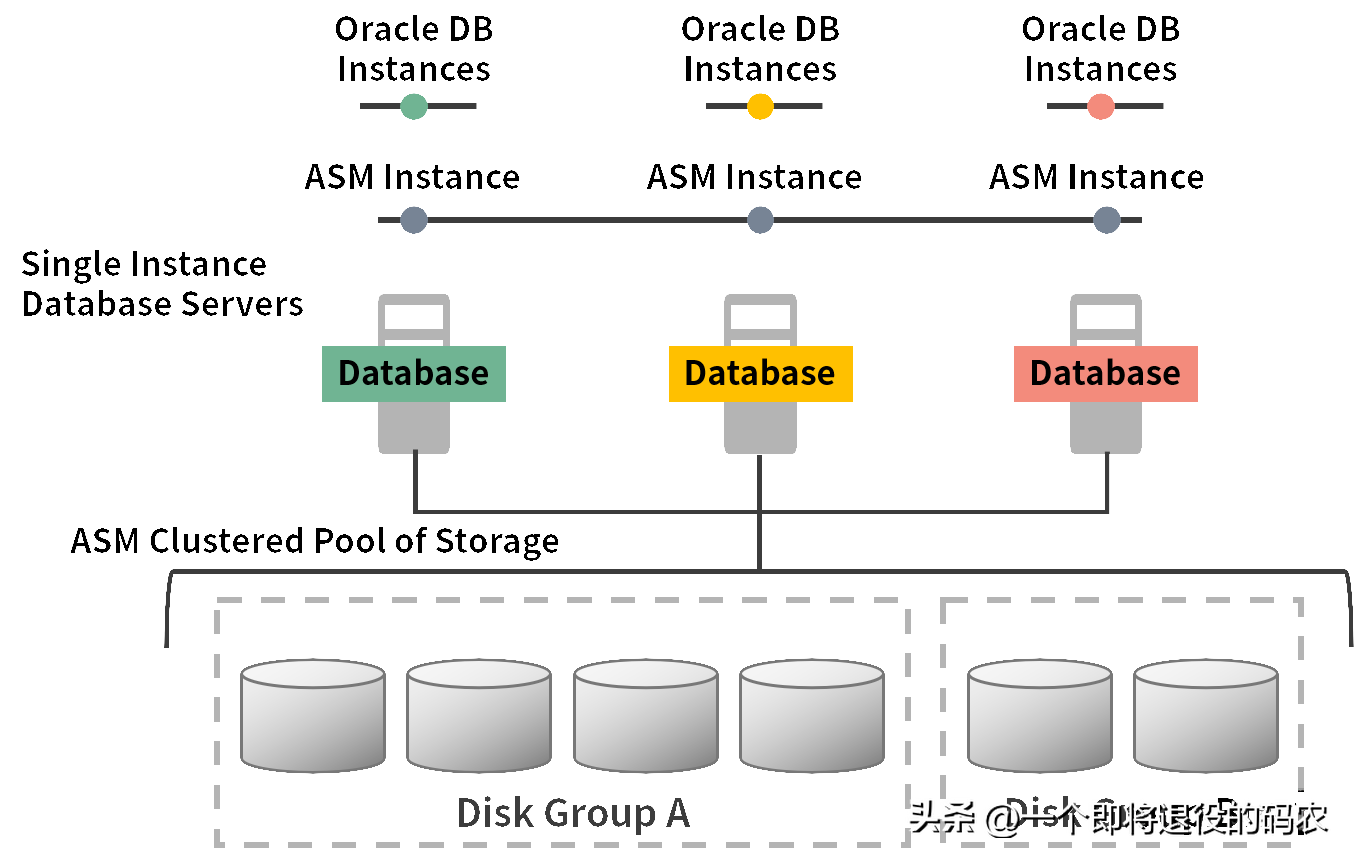
Oracle RAC 是典型的大型商業解決方案,且為軟硬件一體化解決方案。我在早年入職國內頂級電信行業解決方案公司的時候,就被其強大的性能所震撼,又為它高昂的價格所深深折服。它是那個時代數據庫性能的標桿和極限,是完美方案與商業成就的體現。
我們試著用上面談到的兩個特性來簡單分析一下 RAC:它確實是做到了數據分片與同步。每一層都是離散化的,特別在底層存儲使用了 ASM 鏡像存儲技術,使其看起來像一塊完整的大磁盤。
這樣做的好處是實現了極致的使用體驗,即使用單例數據庫與 RAC 集群數據庫,在使用上沒有明顯的區別。它的分布式存儲層提供了完整的磁盤功能,使其對應用透明,從而達到擴展性與其他性能之間的平衡。甚至在應對特定規模的數據下,其經濟性又有不錯的表現。
這種分布式數據庫設計被稱為“共享存儲架構”(share disk architecture)。它既是 RAC 強大的關鍵,又是其“阿喀琉斯之踵”,DBA 坊間流傳的 8 節點的最大集群限制可以被認為是 RAC 的極限規模。
該規模在當時的環境下是完全夠用的,但是隨著互聯網的崛起,一場轟轟烈烈的“運動”將會打破 Oracle RAC 的不敗金身。
大數據
我們知道 Oracle、DB2 等商業數據庫均為 OLTP 與 OLAP 融合數據庫。而首先在分布式道路上尋求突破的是 OLAP 領域。在 2000 年伊始,以 Hadoop 為代表的大數據庫技術憑借其“無共享”(share nothing)的技術體系,開始向以 Oracle 為代表的關系型數據庫發起沖擊。
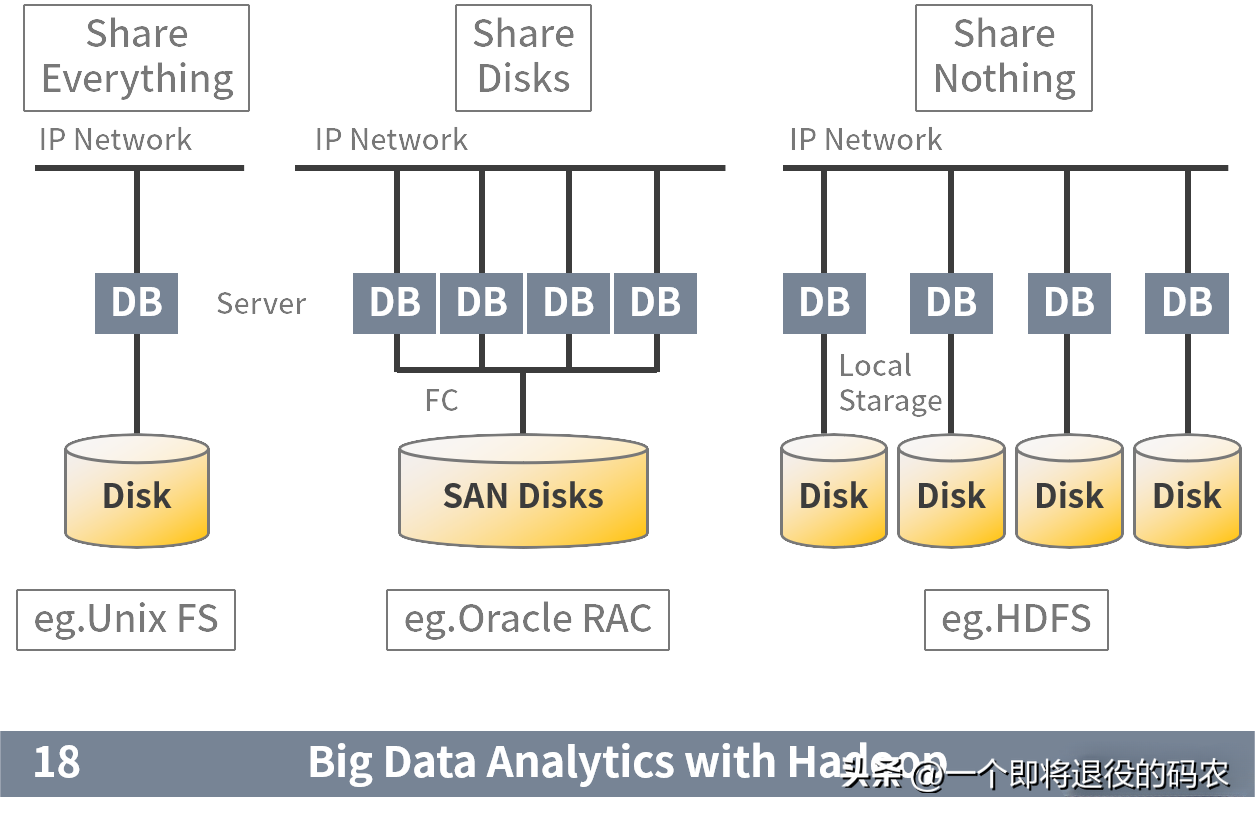
這是一次水平擴展與垂直擴展,通用經濟設備與專用昂貴服務,開源與商業這幾組概念的首次大規模碰撞。拉開了真正意義上分布式數據庫的帷幕。
當然從一般的觀點出發,Hadoop 一類的大數據處理平臺不應稱為數據庫。但是從前面我們歸納的兩點特性看,它們又確實非常滿足。因此我們可以將它們歸納為早期面向商業分析場景的分布式數據庫。從此 OLAP 型數據庫開始了自己獨立演化的道路。
除了 Hadoop,另一種被稱為 MPP(大規模并行處理)類型的數據庫在此段時間也經歷了高速的發展。MPP 數據庫的架構圖如下:
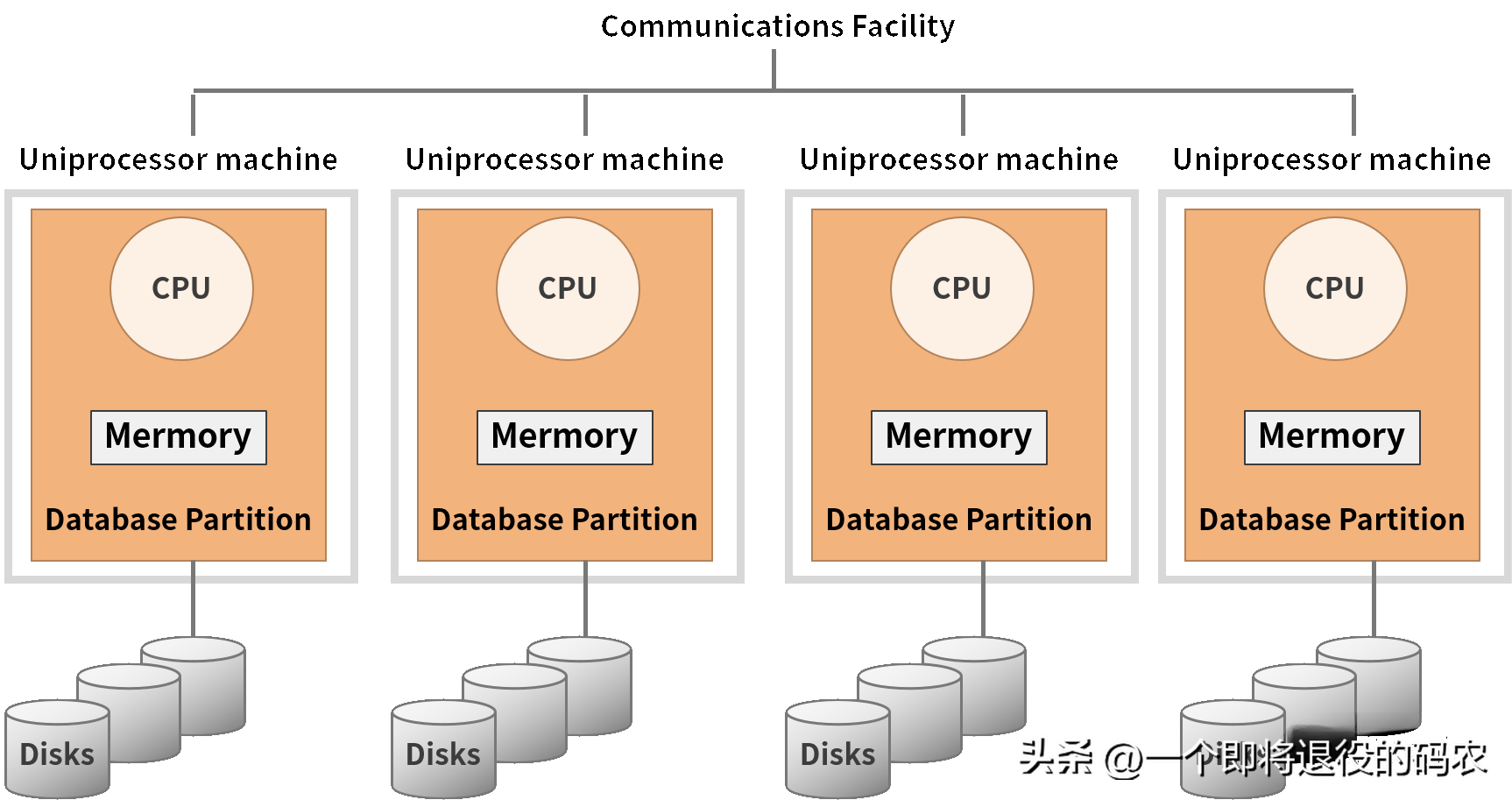
我們可以看到這種數據庫與大數據常用的 Hadoop 在架構層面上非常類似,但理念不同。簡而言之,它是對 SMP(對稱多處理器結構)、NUMA(非一致性存儲訪問結構)這類硬件體系的創新,采用 shared-nothing 架構,通過網絡將多個 SMP 節點互聯,使它們協同工作。
MPP 數據庫的特點是首先支持 PB 級的數據處理,同時支持比較豐富的 SQL 分析查詢語句。同時,該領域是商業產品的戰場,其中不僅僅包含獨立廠商,如 Teradata,還包含一些巨頭玩家,如 HP 的 Vertica、EMC 的 Greenplum 等。
大數據技術的發展使 OLAP 分析型數據庫,從原來的關系型數據庫之中獨立出來,形成了完整的發展分支路徑。而隨著互聯網浪潮的發展,OLTP 領域迎來了發展的機遇。
互聯網化
國內數據庫領域進入互聯網時代第一個重大事件就是“去 IOE”。
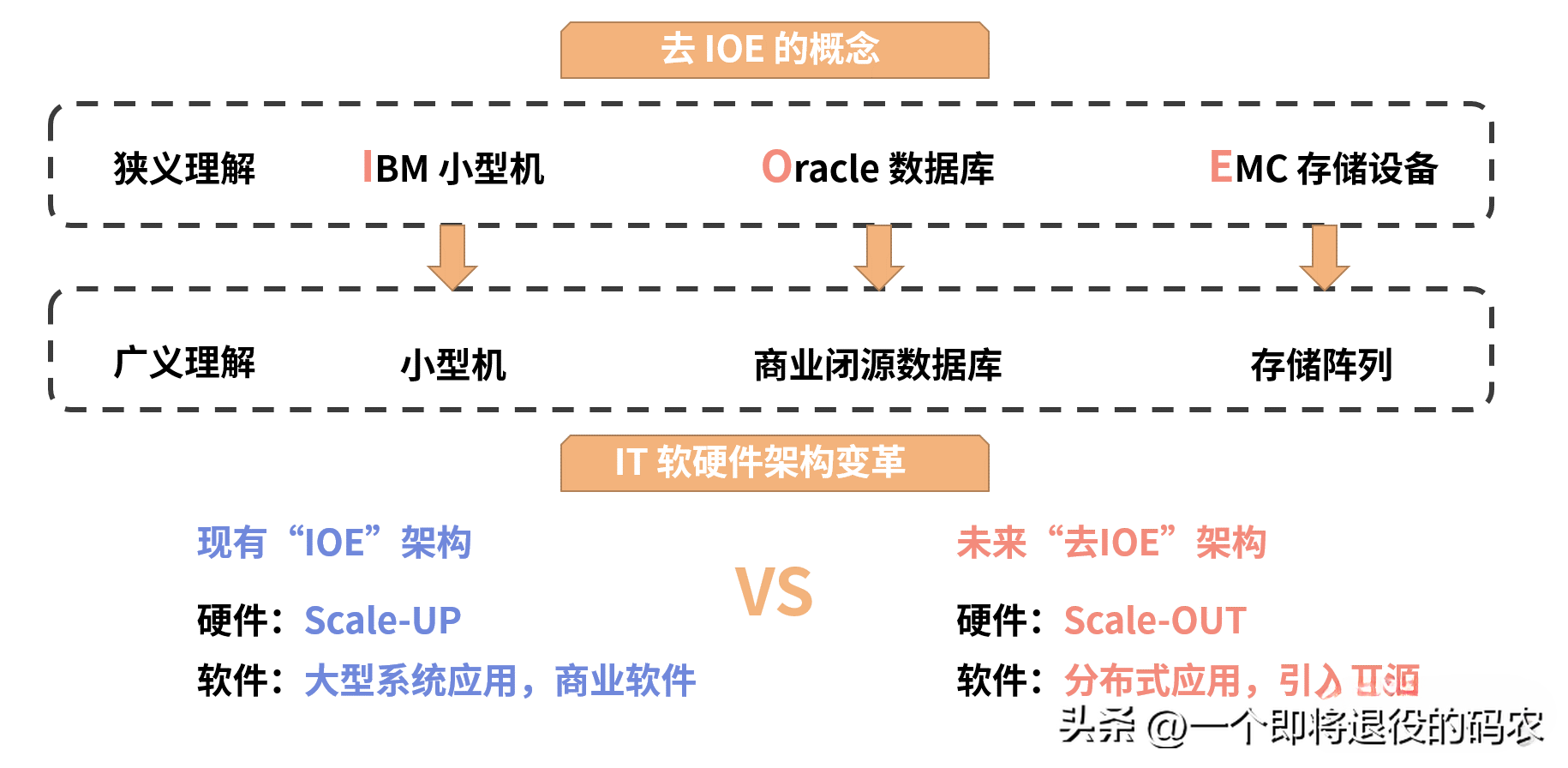
其中尤以“去 Oracle 數據庫”產生的影響深遠。十年前,阿里巴巴喊出的這個口號深深影響了國內數據庫領域,這里我們不去探討其中細節,也不去評價它正面或負面的影響。但從對于分布式數據庫的影響來說,它至少帶來兩種觀念的轉變。
應用成為核心:去 O 后,開源數據庫需要配合數據庫中間件(proxy)去使用,但這種組合無法實現傳統商業庫提供的一些關鍵功能,如豐富的 SQL 支持和 ACID 級別的事務。因此應用軟件需要進行精心設計,從而保障與新數據庫平臺的配合。應用架構設計變得非常關鍵,整個技術架構開始脫離那種具有調侃意味的“面向數據庫” 編程,轉而變為以應用系統為核心。
弱一致性理念普及:雖然強一致性仍然需求旺盛,但人們慢慢接受了特定場景下可以嘗試弱一致性來解決系統的吞吐量問題。而這帶來了另外一個益處,一線研發與設計人員開始認真考慮業務需要什么樣的一致性,而不是簡單依靠數據庫提供的特性。
以上兩個觀念都是在破除了對于 Oracle 的迷信后產生的,它們本身是正面的,但是如果沒有這場運動,其想要在普通用戶之中普及確實有很大困難。而這兩種觀念也為日后分布式數據庫,特別是國產分布式數據的發展帶來了積極的影響。
而與此同期,全球范圍內又上演著 NoSQL 化浪潮,它與國內去 IOE 運動一起推動著數據庫朝著橫向分布的方向一路狂奔。關于 NoSQL 的內容,將會在下一講詳細介紹。
與上一部分中提到的大數據技術類似,隨著互聯網的發展,去 IOE 運動將 OLTP 型數據庫從原來的關系型數據庫之中分離出來,但這里需要注意的是,這種分離并不是從基礎上構建一個完整的數據庫,而是融合了舊有的開源型數據庫,同時結合先進的分布式技術,共同構造了一種融合性的“準”數據庫。它是面向具體的應用場景的,所以閹割掉了傳統的 OLTP 數據庫的一些特性,甚至是一些關鍵的特性,如子查詢與 ACID 事務等。
而 NoSQL 數據庫的重點是支持非結構化數據,如互聯網索引,GIS 地理數據和時空數據等。這種數據在傳統上會使用關系型數據庫存儲,但需要將此種數據強行轉換為關系型結構,不僅設計煩瑣,而且使用效率也比較低下。故NoSQL 數據庫被認為是對整個數據庫領域的補充,從而人們意識到數據庫不應該僅僅支持一種數據模式。
隨著分布式數據庫的發展,一種從基礎上全新設計的分布式 OLTP 數據庫變得越來越重要,而云計算更是為這種數據庫注入新的靈魂,兩者的結合將會給分布式數據庫帶來美妙的化學反應。
云原生是未來
從上文可以看到人們真正具有廣泛認知的分布式數據庫,即 OLTP 型交易式分布式數據庫,依然是分布式數據庫領域一個缺失的片段,且是一個重要的片段。一個真正的 OLTP 數據庫應該具備什么特點呢?
實際上人們需要的是它既具有一個單機的關系型數據庫的特性,又有分布式的分片與同步特性。 DistributedSQL 和 NewSQL 正是為了這個目的而生的 。它們至少具有如下兩點引人注目的特性:
- SQL 的完整支持
- 可靠的分布式事務。
典型的代表有 Spanner、NuoDB、TiDB 和 Oceanbase 等。并且本課程會重點圍繞 DistributedSQL 的關鍵特性展開研究,這些特性是現代分布式數據庫的基石。這里我就不占用過多篇幅介紹了,在 02 | SQL vs NoSQL:一次搞清楚五花八門的各種“SQL”中我們再一起詳細學習。
與此同時,隨著云計算的縱向深入發展,分布式數據庫又迎來新的革命浪潮——云原生數據庫。
首先,由于云服務天生的“超賣”特性,造成其采購成本較低,從而使終端用戶嘗試分布式數據庫的門檻大大降低。
其次,來自云服務廠商的支撐人員可以與用戶可以進行深度的合作,形成了高效的反饋機制。這種反饋機制促使云原生的分布式數據庫有機會進行快速的迭代,從而可以積極響應客戶的需求。
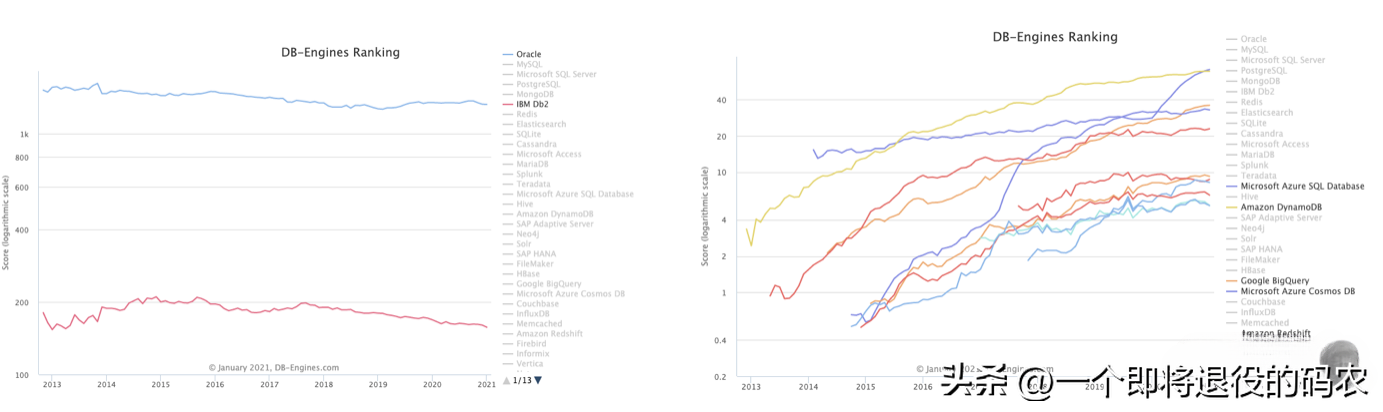
這就是云原生帶給分布式數據庫的變化,它是通過生態系統的優化完成了對傳統商業數據庫的超越。以下來自 DB-Engines 的分析數據說明了未來的數據庫市場屬于分布式數據庫,屬于云原生數據庫。
隨著分布式數據庫的發展,我們又迎來了新的一次融合:那就是 OLTP 與 OLAP 將再一次合并為 HTAP(融合交易分析處理)數據庫。
該趨勢的產生主要來源于云原生 OLTP 型分布式數據庫的日趨成熟。同時由于整個行業的發展,客戶與廠商對于實時分析型數據庫的需求越來越旺盛,但傳統上大數據技術包括開源與 MPP 類數據庫,強調的是離線分析。
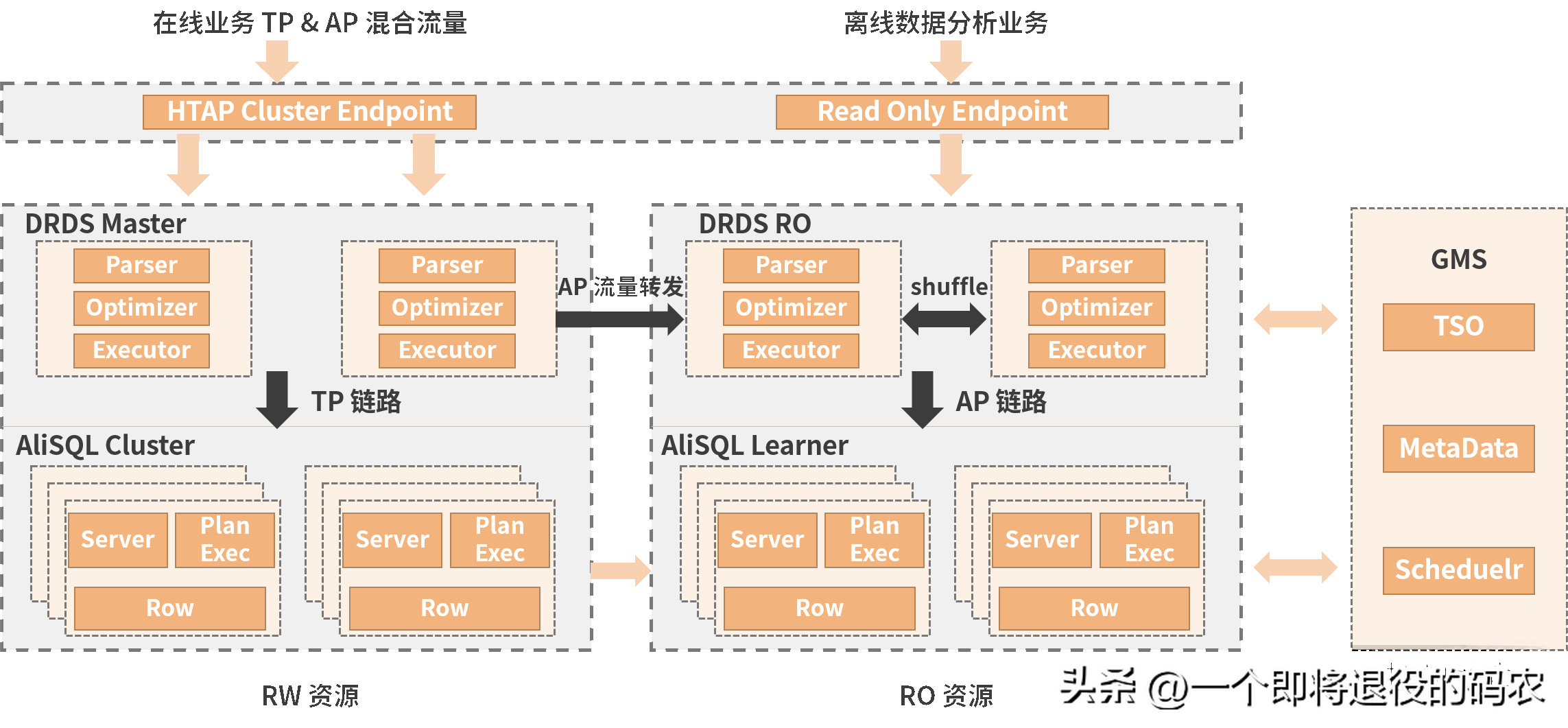
如果要進行秒級的數據處理,那么必須將交易數據與分析數據盡可能地貼近,并減少非實時 ELT 的引入,這就促使了 OLTP 與 OLAP 融合為 HTAP。下圖就是阿里云 PolarDB 的 HTAP 架構。
總結
用《三國演義》的第一句話來說:“天下大勢,分久必合,合久必分。”而我們觀察到的分布式數據庫,乃至數據庫本身的發展正暗合了這句話。
分布式數據庫發展就是一個由合到分,再到合的過程:
早期的關系型商業數據庫的分布式能力可以滿足大部分用戶的場景,因此產生了如 Oracle 等幾種巨無霸數據庫產品;
OLAP 領域首先尋求突破,演化出了大數據技術與 MPP 類型數據庫,提供功能更強的數據分析能力;
去 IOE 引入數據庫中間件,并結合應用平臺與開源單機數據庫形成新一代解決方案,讓商業關系型數據庫走下神壇,NoSQL 數據庫更進一步打破了關系型數據庫唯我獨尊的江湖地位;
新一代分布式 OLTP 數據庫正式完成了分布式領域對數據庫核心特性的完整支持,它代表了分布式數據庫從此走向了成熟,也表明了 OLAP 與 OLTP 分布式場景下,分別在各自領域內取得了勝利;
HTAP 和多模式數據處理的引入,再一次將 OLAP 與 OLTP 融合,從而將分布式數據庫推向如傳統商業關系型數據庫數十年前那般的盛況,而其產生的影響要比后者更為深遠。
我們回顧歷史,目的是更好地掌握未來。而分布式數據庫的歷史同時體現了實用主義的特色,其演化是需求與技術博弈的結果,而不是精心設計出來的。?

























