記一次跨域配置引發的思考
作者簡介
Flora,攜程高級研發經理,關注Node.js相關領域。
如果對跨域不太熟悉的同學,可以閱讀一下MDN HTTP訪問控制(CORS)這篇文章。相關概念在本文中就不再做贅述。
一、背景回顧
一個周五的下午,我們收到了一個需求,需要調整一下響應頭中的Access-Control-Allow-Origin字段。這個需求的起因是什么呢?
先看一下目前的情況。針對webresource站點(后續皆以這個站點作為資源站點的代號),無論是否是跨域請求,都會返回這樣的頭部。見圖1。

圖1 請求webresource站點的響應頭截圖
Fig.1 Screenshot of response headers for requesting a webresource site
這個響應看上去似乎沒有什么問題。
但是考慮這樣一個場景:如果用戶需要基于HTTP cookies和HTTP認證信息發送身份憑證,那么就需要再客戶端設置一個特殊的credentials標志。例如,如果使用了fetch,那么就需要新增fetch的配置,如圖2所示:

圖2 fetch方法新增credentials配置
Fig.2 fetch method adds credentials configuration
再客戶端調整成如上配置后,再次運行會報以下錯誤,見圖3。
“Access to fetch at
'https://webresource.c-ctrip.com/ResUnionOnline/R1/common/marinRedirect.js?v=20220903'
from origin 'https://www.ctrip.com' has been blocked by CORS policy: The value of the 'Access-Control-Allow-Origin' header in the response must not be the wildcard '*' when the request's credentials mode is 'include'.”

圖3 請求出錯截圖
Fig.3 Screenshot of request error
通過翻閱這篇文章(??Reason: Credential is not supported if the CORS header ‘Access-Control-Allow-Origin’ is ‘*??’),我們可以得到解答:
“??CORS?? 請求發出時,已經設定了 credentials,但服務端配置了 http 響應首部 ??Access-Control-Allow-Origin ??的值為通配符 ("*") ,而這與使用 credentials 相悖。”
所以,這才回到了本節一開始我們需要做的一個調整,將原先的Access-Control-Allow-Origin設置為具體的origin值,而非 * 星號。
再次調整之后,服務的響應頭更新為圖4所示:

圖4 請求webresource站點的響應頭截圖
Fig.4 Screenshot of response headers for requesting a webresource site
二、故障現場
周五代碼調整好,資源源站服務的單元測試跑通,發布到金絲雀測試,用戶也反饋不報錯了,變更正式發布。監控看板一切正常,就愉快的回家過周末了。
周六上午突然有開發同學截了一張圖給我,說他們的應用報錯了:

圖5 在線故障截圖
Fig.5 Screenshot of online fault
用戶在??https://ebooking.ctrip.com?? 訪問了一個資源,但是這個資源響應的Access-Control-Allow-Origin的頭是 ??https://flights.ctrip.com?? 。我去訪問了這個頁面,并未發現此類報報錯。回訪了一些用戶,也讓同事一起嘗試訪問,得到的反饋是一部分客戶端報錯,一部分客戶端正常。
三、原因分析
當時我們的第一反應就是再次檢查源站的邏輯更改,發現源站的Access-Control-Allow-Origin的配置代碼無異常,絕對不會將Access-Control-Allow-Origin的值 origin設置錯誤。再次結合反饋的情況,是部分用戶會報錯,開始將排障方向轉向CDN(Content Delivery Network)。
如果對CDN不熟悉的同學,可以閱讀??wikipedia CDN??或者??What is a CDN (Content Delivery Network)???
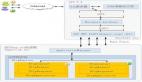
首先看這張簡化的CDN結構圖(圖6)。目前針對webresource站點有三家CDN供應商,我們將他們稱為:B供應商、W供應商和A供應商。其中B和W供應商為國內用戶提供服務,他們的流量配比分別是50%和50%;A供應商為海外用戶提供服務,他的流量配比是100%。
當一個國內用戶請求某個webresource站點的資源時,他有可能會被分配到B、有可能分配到W。B或者W都會有概率(如果CDN節點命中失敗的話),就會請求到資源源站服務。

圖6 簡化的CDN結構圖
Fig.6 Simplified CDN Structure Diagram
由于客戶端的反饋是部分正確部分異常,所以推測是CDN供應商可能某一家有異常或者某個節點有異常。于是再次綁定B供應商和W供應商的服務器節點進行測試,均設置請求頭中的Origin為??https://ebooking.ctrip.com??。
我們得到了如下的結果:
1)B供應商響應的內容和源站響應的內容保持一致,如圖7所示。

圖7 B供應商的響應體截圖
Fig.7 Screenshot of response body for B supplier
2)W供應商響應的內容與源站有2個響應頭不一致,如圖8所示。

圖8 W供應商的響應體截圖
Fig.8 Screenshot of response body for W supplier
第一個不一致是Access-Control-Allow-Origin不是源站,第二個不一致是缺少了Vary的頭部。細心的同學通過“圖4 請求webresource站點的響應頭截圖”,可以看到,源站是有設置Vary頭部為“Origin, Accept-Encoding”,見圖9。要知道,一旦缺少了這個頭部,就無法標識要基于Origin做協商緩存。
對Vary不熟悉的同學,可以參看??HTTP Vary??。
“Vary 是一個 HTTP 響應頭部信息,它決定了對于未來的一個請求頭,應該用一個緩存的回復 (response) 還是向源服務器請求一個新的回復。它被服務器用來表明在 ??content negotiation?? algorithm(內容協商算法)中選擇一個資源代表的時候應該使用哪些頭部信息(headers).”
如果Vary字段中有Origin,那么簡單理解可以是基于Origin+URL做緩存。當Origin不一樣的時候,就需要做頭部信息的更新。同理,比如一些特殊文件polyfill,是需要基于瀏覽器做一些處理的,那么就可以設置將User-Agent設置到Vary中,這樣就會針對同一個文件,基于User-Agent做緩存。

圖9 請求webresource站點的響應頭截圖
Fig.9 Screenshot of response headers for requesting a webresource site
至此問題基本定位到:
當兩個不同的Origin(主站點)跨域請求同一個資源的時候,由于W供應商并沒有根據資源服務返回的響應,正確配置CDN緩存頭部,這樣會導致返回的Access-Control-Allow-Origin值錯亂。
四、故障解決
解決在線故障第一要素是快速響應。所以我們將國內CDN配比從原先的各50%,更改成B供應商100%,保證客戶端的響應正常。
接著聯系W供應商,當我們認為是供應商的一個嚴重的bug時,供應商的答復是:
①請求Origin: http://ebooking.ctrip.com 緩存下來后(其對應的Etag為W/"D96CF9DBB3B578CC1721941E799BE22D"),由于源站響應了Vary: origin, accept-encoding,走入到了Vary緩存的邏輯中;
②再請求Origin: http://a.ctrip.com,由于走入到Vary緩存的邏輯,且VaryData沒有匹配到http://a.ctrip.com,則走入到Vary miss的邏輯中,miss回上層的時候帶了If-None-Match: W/"D96CF9DBB3B578CC1721941E799BE22D",此次回上層帶的Origin是http://a.ctrip.com,但由于帶了If-None-Match,且源站不同Origin的Etag值是相同的。所以響應了304,這時候就會直接復用Origin: http://ebooking.ctrip.com的響應了,也就會用到Origin: http://ebooking.ctrip.com響應的Access-Control-Allow-Origin頭部了”
這里W供應商這里有一個致命的邏輯錯誤:當用If-None-Match請求源站時,源站返回了304。這代表body沒有改變,但同時源站返回了正確的Access-Control-Allow-Origin的頭給到CDN。然而CDN并沒有替換源站給到的頭,而是直接讀取一個緩存中錯誤的頭。
雖然我們源站遵循了HTTP的標準,但是CDN沒有遵循,導致返回給用戶的響應頭出錯了。

圖10 304請求也需要響應Vary頭
Fig.10 304 requests also need to respond to the Vary header
經過一番溝通,W供應商答應可以將這個邏輯做一個配置,規避出錯的問題。但是需要按照資源域名逐一配置,也就是配置白名單的方式。
所以最終的解決方案是給到W供應商一批資源域名列表,讓供應商做手動配置。且需要記住每一次新增一個資源域名都要同步到W供應商。
五、經驗總結
經過這次的故障,我們有如下總結:
1)測試完整性:資源源站站點的每次更新發布,除了需要驗證自身應用的正確性,也需要將每個CDN供應商進行逐一的集成測試。因為不知道哪一個環節或者哪個配置可能會踩到坑。
2)開發標準性:無論我們的上游是怎么處理的,資源源站服務的開發一定要遵循HTTP標準。只有參照標準,才能進行有秩序的治理。??HTTP??是一份需要經常拿來閱讀的文檔。
3)資源的唯一性:在引用靜態資源時,盡量保證資源URL的唯一性,例如可以用md5來標識文件。這樣的好處是,當這個資源出現一些不可預期的故障時,可以及時升級文件來達到快速刷新客戶端請求內容的效果,而不是依靠緩存清理工具。
一方面是因為每個CDN供應商purge(清理緩存)的機制不一樣,而且沒有一個治理工具可以獲悉是否每個CDN節點的緩存正確purge了。我想也許“緩存清理成功率”這個指標并未寫到CDN供應商的交付指標中。
另一個方面是還有一些未可知的緩存節點,例如客戶端的緩存,又例如在某個酒店內部使用的系統,有可能酒店內部網絡存在緩存。
我們曾經發生過無論如何執行CDN側的緩存清理腳本,客戶端都無法拿到新的資源。與CDN供應商排查了許久未果,最終迫不得已還是修改了引用的URL地址(例如加一個query字段,雖然不優雅,但至少能暫時解決問題)。所以保證資源的唯一性還是很有必要的。
最后還想說一句,如果可以實現統一各CDN供應商的標準,那該是件多么美好的事情。
再經過一番深入了解后知悉,某些CDN供應商的設計初衷是直接對接存儲,而非一個靜態源站服務。而一些頭部的配置是直接放在CDN供應商的控制面板中做配置。例如默認不會開啟Vary這些的配置,是為了提升緩存效率。