MySQL 不相關子查詢怎么執行?

經過??上一篇??? where field in (...) 的開場準備,本文正式開啟??子查詢系列??,這個系列會介紹子查詢的各種執行策略,計劃包括以下主題:
- 不相關子查詢 (Subquery)
- 相關子查詢 (Dependent Subquery)
- 嵌套循環連接 (Blocked Nested Loop Join)
- 哈希連接 (Hash Join)
- 表上拉 (Table Pullout)
- 首次匹配 (First Match)
- 松散掃描 (Loose Scan)
- 重復值消除 (Duplicate Weedout)
- 子查詢物化 (Materialize)
上面列表中,從表上拉(Table Pullout)開始的 5 種執行策略都用 Join 實現,所以把嵌套循環連接、哈希連接也包含在這個系列里面了。
子查詢系列文章的主題,在寫作過程中可能會根據情況調整,也可能會插入其它不屬于這個系列的文章。
本文我們先來看看不相關子查詢是怎么執行的?
本文內容基于 MySQL 8.0.29 源碼。
1、概述
從現存的子查詢執行策略來看,半連接 (Semijoin) 加入之前,不相關子查詢有兩種執行策略:
策略 1,子查詢物化,也就是把子查詢的執行結果存入臨時表,這個臨時表叫作物化表。
explain select_type = ??SUBQUERY?? 就表示使用了物化策略執行子查詢,如下:
策略 2,轉換為相關子查詢,explain select_type = DEPENDENT SUBQUERY,如下:
本文我們要介紹的就是使用物化策略執行不相關子查詢的過程,不相關子查詢轉換為相關子查詢的執行過程,留到下一篇文章。
2、執行流程
我們介紹的執行流程,不是整條 SQL 的完整執行流程,只會涉及到子查詢相關的那些步驟。

查詢優化階段,MySQL 確定了要使用物化策略執行子查詢之后,就會創建臨時表。
關于創建臨時表的更多內容,后面有一小節單獨介紹。
執行階段?,server 層從存儲引擎讀取到主查詢?的第一條記錄之后,就要判斷記錄是否匹配 where 條件。
判斷包含子查詢的那個 where 條件字段時,發現子查詢需要物化,就會執行子查詢。
為了方便描述,我們給包含子查詢的那個 where 條件字段取個名字:sub_field,后面在需要時也會用到這個名字。
執行子查詢的過程,是從存儲引擎一條一條讀取子查詢表中的記錄。每讀取到一條記錄,都寫入臨時表中。
子查詢的記錄都寫入臨時表之后,從主查詢記錄中拿到 sub_field? 字段值,去臨時表中查找,如果找到了記錄,sub_field 字段條件結果為 true,否則為 false。
主查詢的所有 where 條件都判斷完成之后,如果每個 where 條件都成立,記錄就會返回給客戶端,否則繼續讀取下一條記錄。
server 層從存儲引擎讀取主查詢?的第 2 ~ N 條記錄,判斷記錄是否匹配 where 條件時,就可以直接用 sub_field? 字段值去臨時表中查詢是否有相應的記錄,以判斷 sub_field 字段條件是否成立。
從以上內容可以見,子查詢物化只會執行一次。
3、創建臨時表
臨時表是在查詢優化階段創建的,它也是一個正經表。既然是正經表,那就要確定它使用什么存儲引擎。
臨時表會優先使用內存存儲引擎,MySQL 8 有兩種內存存儲引擎:
- 從 5.7 繼承過來的MEMORY 引擎。
- 8.0 新加入的TempTable 引擎。
有了選擇就要發愁,MySQL 會選擇哪個引擎?
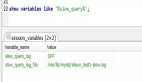
這由我們決定,我們可以通過系統變量 internal_tmp_mem_storage_engine 告訴 MySQL 選擇哪個引擎,它的可選值為 TempTable(默認值)、MEMORY。
然而,internal_tmp_mem_storage_engine? 指定的引擎并不一定是最終的選擇,有兩種情況會導致臨時表使用磁盤?存儲引擎 InnoDB。
這兩種情況如下:
情況 1,如果我們指定了使用 MEMORY 引擎,而子查詢結果中包含 BLOB 字段,臨時表就只能使用 InnoDB 引擎了。
為啥?因為 MEMORY 引擎不支持 BLOB 字段。
情況 2,如果系統變量 big_tables? 的值為 ON?,并且子查詢中沒有指定 SQL_SMALL_RESULT Hint,臨時表也只能使用 InnoDB 引擎。
big_tables 的默認值為 OFF。
這又為啥?
因為 big_tables = ON 是告訴 MySQL 我們要執行的所有 SQL 都包含很多記錄,臨時表需要使用 InnoDB 引擎。
然而,時移事遷,如果某天我們發現有一條執行頻繁的 SQL,雖然要使用臨時表,但是記錄數量比較少,使用內存存儲引擎就足夠用了。
此時,我們就可以通過 Hint 告訴 MySQL 這條 SQL 的結果記錄數量很少,MySQL 就能心領神會的直接使用 internal_tmp_mem_storage_engine 中指定的內存引擎了。
SQL可以這樣指定 Hint:
捋清楚了選擇存儲引擎的邏輯,接下來就是字段了,臨時表會包含哪些字段?
這里沒有復雜邏輯需要說明,臨時表只會包含子查詢 SELECT 子句中的字段,例如:上面的示例 SQL 中,臨時表包含的字段為 address_id。
使用臨時表存放子查詢的結果,是為了提升整個 SQL 的執行效率。如果臨時表中的記錄數量很多,根據主查詢字段值去臨時表中查找記錄的成本就會比較高。
所以,MySQL 還會為臨時表中的字段創建索引,索引的作用有兩個:
- 提升查詢臨時表的效率。
- 保證臨時表中記錄的唯一性,也就是說創建的索引是唯一索引。
說完了字段,我們再來看看索引結構,這取決于臨時表最終選擇了哪個存儲引擎:
- MEMORY、TempTable 引擎,都使用 HASH 索引。
- InnoDB 引擎,使用 BTREE 索引。
4、自動優化
為了讓 SQL 執行的更快,MySQL 在很多細節處做了優化,對包含子查詢的 where 條件判斷所做的優化就是其中之一。
介紹這個優化之前,我們先準備一條 SQL:
主查詢 city 表中有以下記錄:

示例 SQL where 條件中,country_id 條件包含子查詢,如果不對 where 條件判斷做優化,從 city 表中每讀取一條記錄之后,先拿到 country_id 字段值,再去臨時表中查找記錄,以判斷條件是否成立。
從上面 city 表的記錄可以看到, city_id = 73 ~ 78 的記錄,country_id 字段值都是 44。
從 city 表中讀取到 city_id = 73 的記錄之后,拿到 country_id 的值 44,去臨時表中查找記錄。
不管是否找到記錄,都會有一個結果,為了描述方便,我們假設結果為 true。
接下來從 city 表中讀取 city_id = 74 ~ 78 的記錄,因為它們的 country_id 字段值都是 44,實際上沒有必要再去臨時表里找查找記錄了,直接復用 city_id = 73 的判斷結果就可以了,這樣能節省幾次去臨時表查找記錄的時間。
由上所述,總結一下 MySQL 的優化邏輯:
對于包含子查詢的 where 條件字段,如果連續幾條記錄的字段值都相同,這組記錄中,只有第一條記錄會根據 where 條件字段值去臨時表中查找是否有對應記錄,這一組的剩余記錄直接復用第一條記錄的判斷結果。
5、手動優化
上一小節介紹的是 MySQL 已經做過的優化,但還有一些可以做而沒有做的優化,我們寫 SQL 的時候,可以自己優化,也就是手動優化。
我們還是使用前面的示例 SQL 來介紹手動優化:

主查詢有兩個 where 條件,那么判斷 where 條件是否成立有兩種執行順序:
- 先判斷 country_id 條件,如果結果為 true,再判斷 city 條件。
- 先判斷 city 條件,如果結果為 true,再判斷 country_id 條件。
MySQL 會按照 where 條件出現的順序判斷,也就是說,我們把哪個 where 條件寫在前面,MySQL 就先判斷哪個。對于示例 SQL 來說,就是上面所列的第一種執行順序。
為了更好的比較兩種執行順序的優劣,我們用量化數據來說明。
根據 country_id 字段值去子查詢臨時表中查找記錄的成本,會高于判斷 city 字段值是否小于 China 的成本,所以,假設執行一次 country_id 條件判斷的成本為 5,執行一次 city 條件判斷的成本為 1。
對于主查詢的某一條記錄,假設 country_id 條件成立,city 條件不成立,兩種執行順序成本如下:
- 先判斷 country_id 條件,成本為 5,再判斷 city 條件,成本為 1,總成本 5 + 1 = 6。
- 先判斷 city 條件,成本為 1,因為條件不成立,不需要再判斷 country_id 條件,總成本為 1。
上面所列場景,第一種執行順序的成本高于第二種執行順序的成本,而 MySQL 使用的是第一種執行順序。
MySQL 沒有為這種場景做優化,我們可以手動優化,寫 SQL 的時候,把這種包含子查詢的 where 條件放在最后,盡可能讓 MySQL 少做一點無用工,從而讓 SQL 可以執行的更快一點。
6、總結
對于 where 條件包含子查詢的 SQL,我們可以做一點優化,就是把這類 where 條件放在最后,讓 MySQL 能夠少做一點無用功,提升 SQL 執行效率。
本文轉載自微信公眾號「一樹一溪」,可以通過以下二維碼關注。轉載本文請聯系一樹一溪公眾號。