













談談如何跨越數據架構的漩渦
如果讓當前數據工程領域的人繪制一個“現代”數據架構,幾乎肯定會得到如下結果:

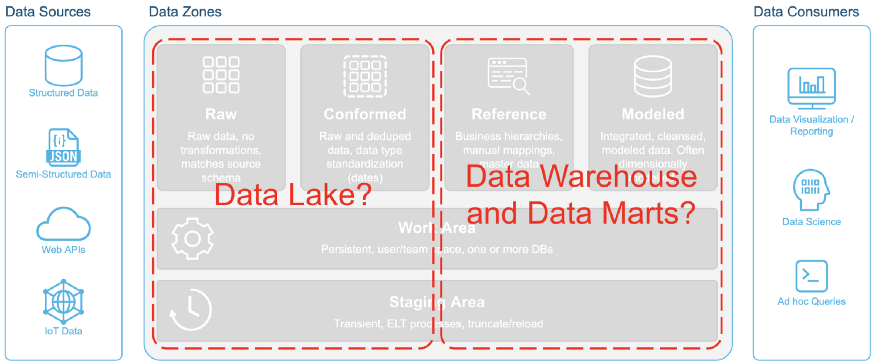
這樣的數據架構格局反映了基于系統的架構設計方法。這種基于系統的架構有何現代感?它已經存在了將近 10 年,并且沒有太大變化。該架構由三個主要組件組成:數據倉庫、數據湖和數據集市(或服務層)。
首先是數據倉庫。之所以需要擁有獨立的數據集市和數據湖,是因為那些傳統的數據倉庫無法擴展以滿足置于其上的不同的、相互競爭的應用場景。數據集市的出現是因為中央數據倉庫無法擴展以滿足最終用戶的不同應用和高并發需求。然后是數據湖,因為企業數據倉庫無法存儲和處理大數據(在數量、種類和速度方面)。
創建數據湖和數據集市是為了滿足當時數據工程領域的實際需求。即使在今天,數據倉庫仍然無法支持企業的所有不同應用。即使對于較新的云數據倉庫也是如此。這些不同的數據系統導致了孤立的數據,這對于企業從中獲取商業價值和安全治理具有非常大的挑戰。
用不同的方式思考數據
為了優化數據架構,我們需要停止根據現有類型的系統來思考數據,例如遺留數據倉庫、數據集市和數據湖。這樣做沒有幫助,而且會在企業數據環境中引入人為的邊界。
以下是關于如何以不同方式思考數據的建議。在較高級別,可以將所有企業數據分組到以下邏輯數據區域:
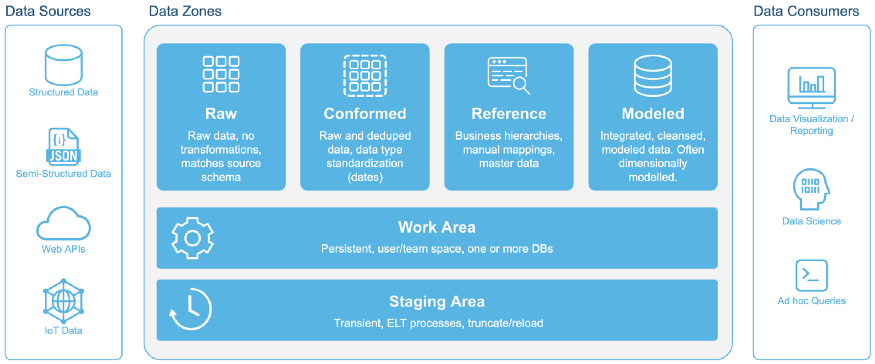
因此,讓我們開始按照這樣的區域而不是系統來考慮數據。舊的基于系統的思維將繼續讓數據工程專業人員陷入舊的做事方式,并將繼續分裂數據格局。采用新的思維模式,無需將數據區域劃分為不同的孤立數據系統,例如:
當像單一平臺可以打破這些孤島時,為什么還要用以前的思路思考呢?我們不應考慮系統問題,而應考慮為所有企業數據建立一個單一平臺,例如

構建企業統一的數據平臺
我們通常使用多個名稱來標識數據的位置和使用方式,包括操作數據存儲 (ODS)、企業信息工廠 (CIF)、數據倉庫、數據集市等等。每個術語代表在企業內對數據進行分組的不同方式。但不幸的是,今天那些不同的數據組代表了不同的數據系統。讓我們開始根據區域(或數據類型)而不是系統來考慮數據。
企業數據架構的目標絕不是將數據格局拆分為多個不同的系統,特別是拆分為數據倉庫、數據集市和數據湖。我們需要停止做一些事情,因為“他們總是那樣做”,并重新思考我們正在努力完成的事情。我們的目標應該是為企業的所有數據建立一個統一的平臺,例如,如下所示:

這樣的數據平臺可以支持所有的數據倉庫、數據湖、數據工程、數據交換、數據應用程序和數據科學的應用場景,我們可以將數據倉庫、數據集市和數據湖整合到一個平臺中。
大多數“云”數據倉庫都是 20 多年前設計的,并且已經遷移到云端。他們無法真正利用云的可擴展性。而那些最近設計的系統不提供完整的企業數據管理體驗,提供治理、符合 ACID 的交易、實時數據共享、完全托管服務等。現在是時候開始以不同的方式思考我們的數據了。






















