我去面試聊了半天MySQL索引,結(jié)果面試官黑臉讓我回家等結(jié)果...

1、面試真題
- MySQ索引的原理和數(shù)據(jù)結(jié)構(gòu)能介紹一下嗎?
- b+樹(shù)和b-樹(shù)有什么區(qū)別?
- MySQL聚簇索引和非聚簇索引的區(qū)別是什么?
- 他們分別是如何存儲(chǔ)的?
- 使用MySQL索引都有哪些原則?
- MySQL復(fù)合索引如何使用?
2、面試官心理分析
數(shù)據(jù)庫(kù)是30k以內(nèi)的工程師面試必問(wèn)的問(wèn)題,而且如果問(wèn)數(shù)據(jù)庫(kù),一定是問(wèn)mysql,N年前可能java工程師出去面試,oracle這塊的技能是殺手锏,現(xiàn)在已經(jīng)沒(méi)人說(shuō),會(huì)oracle是加分項(xiàng)了,現(xiàn)在都是熟悉大數(shù)據(jù)hadoop、hbase等技術(shù)是加分項(xiàng)。
3、面試題剖析
(1)索引的數(shù)據(jù)結(jié)構(gòu)是什么
其實(shí)就是讓你聊聊mysql的索引底層是什么數(shù)據(jù)結(jié)構(gòu)實(shí)現(xiàn)的,弄不好現(xiàn)場(chǎng)還會(huì)讓你畫(huà)一畫(huà)索引的數(shù)據(jù)結(jié)構(gòu),然后會(huì)問(wèn)問(wèn)你mysql索引的常見(jiàn)使用原則,弄不好還會(huì)拿個(gè)SQL來(lái)問(wèn)你,就這SQL建個(gè)索引一般咋建?
至于索引是啥?這個(gè)問(wèn)題太基礎(chǔ)了,大家都知道,mysql的索引說(shuō)白了就是用一個(gè)數(shù)據(jù)結(jié)構(gòu)組織某一列的數(shù)據(jù),然后如果你要根據(jù)那一列的數(shù)據(jù)查詢的時(shí)候,就可以不用全表掃描,只要根據(jù)那個(gè)特定的數(shù)據(jù)結(jié)構(gòu)去找到那一列的值,然后找到對(duì)應(yīng)的行的物理地址即可。
那么回答面試官的一個(gè)問(wèn)題,mysql的索引是怎么實(shí)現(xiàn)的?
答案是,不是二叉樹(shù),也不是一顆亂七八糟的樹(shù),而是一顆b+樹(shù)。這個(gè)很多人都會(huì)這么回答,然后面試官一定會(huì)追問(wèn),那么你能聊聊b+樹(shù)嗎?
但是說(shuō)b+樹(shù)之前,咱們還是先來(lái)聊聊b-樹(shù)是啥,從數(shù)據(jù)結(jié)構(gòu)的角度來(lái)看,b-樹(shù)要滿足下面的條件:
(1)d為大于1的一個(gè)正整數(shù),稱(chēng)為B-Tree的度。
(2)h為一個(gè)正整數(shù),稱(chēng)為B-Tree的高度。
(3)每個(gè)非葉子節(jié)點(diǎn)由n-1個(gè)key和n個(gè)指針組成,其中d<=n<=2d。
(4)每個(gè)葉子節(jié)點(diǎn)最少包含一個(gè)key和兩個(gè)指針,最多包含2d-1個(gè)key和2d個(gè)指針,葉節(jié)點(diǎn)的指針均為null 。
(5)所有葉節(jié)點(diǎn)具有相同的深度,等于樹(shù)高h(yuǎn)。
(6)key和指針互相間隔,節(jié)點(diǎn)兩端是指針。
(7)一個(gè)節(jié)點(diǎn)中的key從左到右非遞減排列。
(8)所有節(jié)點(diǎn)組成樹(shù)結(jié)構(gòu)。
(9)每個(gè)指針要么為null,要么指向另外一個(gè)節(jié)點(diǎn)。
(10)如果某個(gè)指針在節(jié)點(diǎn)node最左邊且不為null,則其指向節(jié)點(diǎn)的所有key小于v(key1),其中v(key1)為node的第一個(gè)key的值。
(11)如果某個(gè)指針在節(jié)點(diǎn)node最右邊且不為null,則其指向節(jié)點(diǎn)的所有key大于v(keym),其中v(keym)為node的最后一個(gè)key的值。
(12)如果某個(gè)指針在節(jié)點(diǎn)node的左右相鄰key分別是keyi和keyi+1且不為null,則其指向節(jié)點(diǎn)的所有key小于v(keyi+1)且大于v(keyi)。
上面那段規(guī)則,我也是從網(wǎng)上找的,說(shuō)實(shí)話,沒(méi)幾個(gè)java程序員能耐心去看明白或者是背下來(lái),大概知道是個(gè)樹(shù)就好了。就拿個(gè)網(wǎng)上的圖給大家示范一下吧:
比如說(shuō)我們現(xiàn)在有一張表:
我們現(xiàn)在對(duì)id建個(gè)索引:15、56、77、20、49
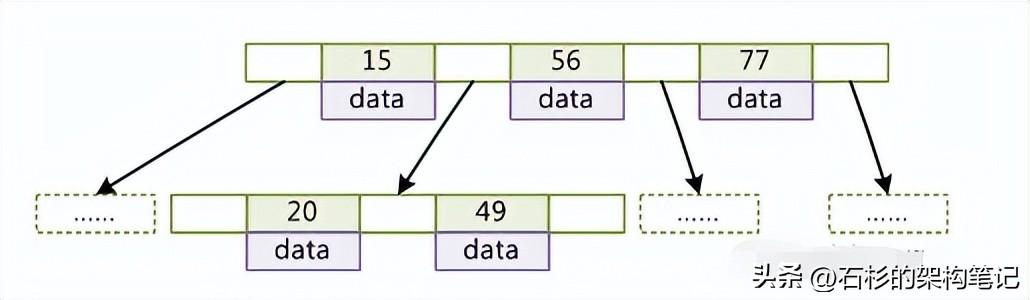
反正大概就長(zhǎng)上面那個(gè)樣子,查找的時(shí)候,就是從根節(jié)點(diǎn)開(kāi)始二分查找。大概就知道這個(gè)是事兒就好了,深講里面的數(shù)學(xué)問(wèn)題和算法問(wèn)題,時(shí)間根本不夠,面試官也沒(méi)指望你去講里面的數(shù)學(xué)和算法問(wèn)題,因?yàn)槲夜烙?jì)他自己也不一定能記住。
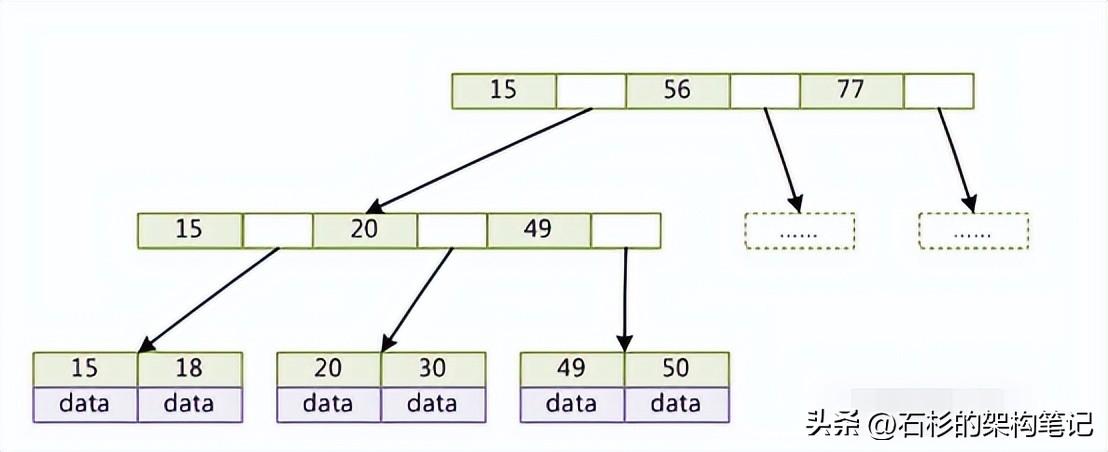
好了,b-樹(shù)就說(shuō)到這里,直接看下一個(gè),b+樹(shù)。b+樹(shù)是b-樹(shù)的變種,啥叫變種?就是說(shuō)一些原則上不太一樣了,稍微有點(diǎn)變化,同樣的一套數(shù)據(jù),放b-樹(shù)和b+樹(shù)看著排列不太一樣的。而mysql里面一般就是b+樹(shù)來(lái)實(shí)現(xiàn)索引,所以b+樹(shù)很重要。
b+樹(shù)跟b-樹(shù)不太一樣的地方在于:
- 每個(gè)節(jié)點(diǎn)的指針上限為2d而不是2d+1。
- 內(nèi)節(jié)點(diǎn)不存儲(chǔ)data,只存儲(chǔ)key;
- 葉子節(jié)點(diǎn)不存儲(chǔ)指針。
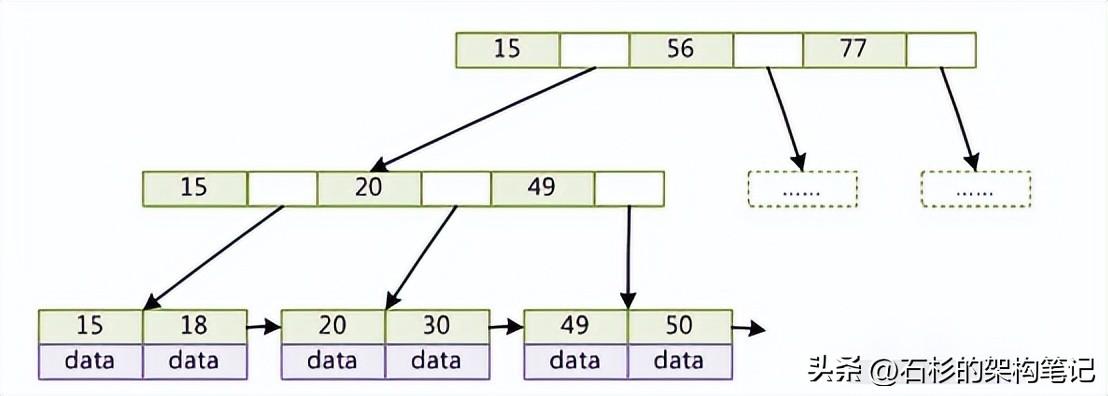
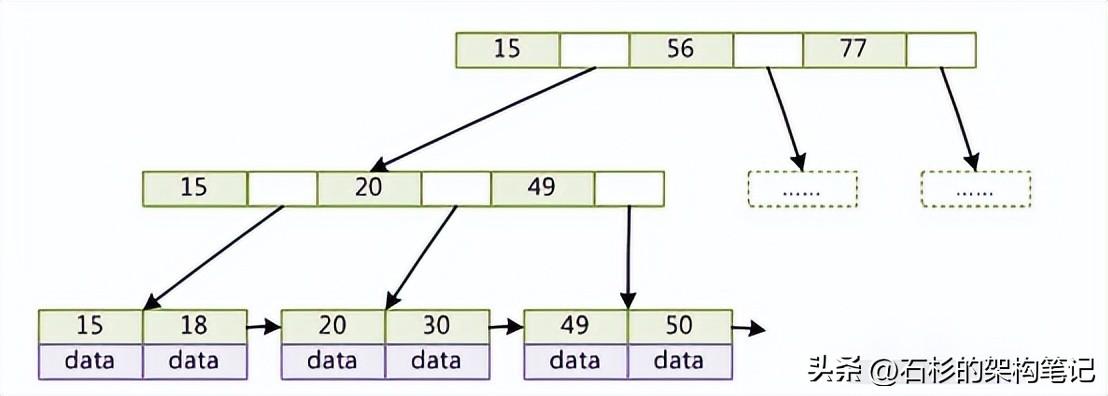
這圖我就不自己畫(huà)了,網(wǎng)上弄個(gè)圖給大家瞅一眼:
但是一般數(shù)據(jù)庫(kù)的索引都對(duì)b+樹(shù)進(jìn)行了優(yōu)化,加了順序訪問(wèn)的指針,如網(wǎng)上弄的一個(gè)圖,這樣在查找范圍的時(shí)候,就很方便,比如查找18~49之間的數(shù)據(jù):
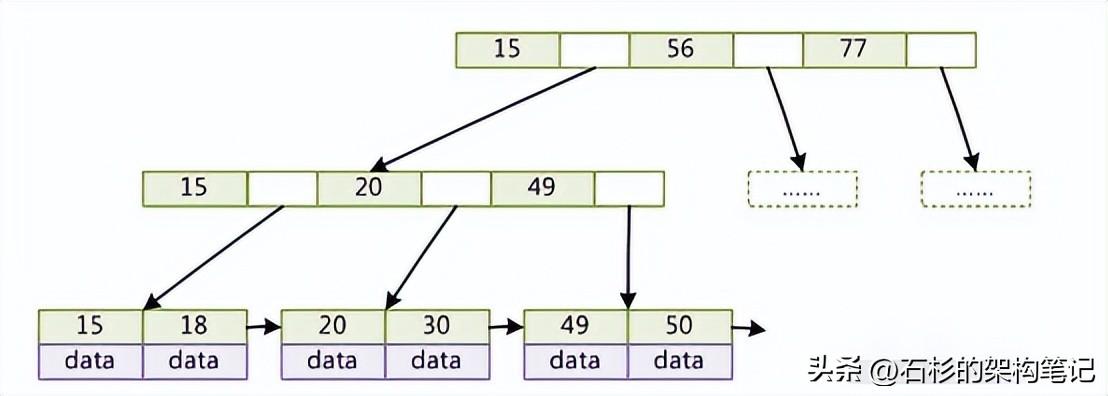
其實(shí)到這里,你就差不多了,你自己仔細(xì)看看上面兩個(gè)圖,b-樹(shù)和b+樹(shù)都現(xiàn)場(chǎng)畫(huà)一下,然后給說(shuō)說(shuō)區(qū)別,和通過(guò)b+樹(shù)查找的原理即可。
接著來(lái)聊點(diǎn)稍微高級(jí)點(diǎn)的,因?yàn)樯厦嬲f(shuō)的只不過(guò)都是最基礎(chǔ)和通用的b-樹(shù)和b+樹(shù)罷了,但是mysql里不同的存儲(chǔ)引擎對(duì)索引的實(shí)現(xiàn)是不同的。
(2)myism存儲(chǔ)引擎的索引實(shí)現(xiàn)
先來(lái)看看myisam存儲(chǔ)引擎的索引實(shí)現(xiàn)。就拿上面那個(gè)圖,咱們來(lái)現(xiàn)場(chǎng)手畫(huà)一下這個(gè)myisam存儲(chǔ)的索引實(shí)現(xiàn),在myisam存儲(chǔ)引擎的索引中,每個(gè)葉子節(jié)點(diǎn)的data存放的是數(shù)據(jù)行的物理地址,比如0x07之類(lèi)的東西,然后我們可以畫(huà)一個(gè)數(shù)據(jù)表出來(lái),一行一行的,每行對(duì)應(yīng)一個(gè)物理地址。
索引文件
id=15,data:0x07,0a89,數(shù)據(jù)行的物理地址。
數(shù)據(jù)文件單獨(dú)放一個(gè)文件。

select * from table where id = 15 -> 0x07物理地址 -> 15,張三,22。
myisam最大的特點(diǎn)是數(shù)據(jù)文件和索引文件是分開(kāi)的,大家看到了么,先是索引文件里搜索,然后到數(shù)據(jù)文件里定位一個(gè)行的。
(3)innodb存儲(chǔ)引擎的索引
好了,再來(lái)看看innodb存儲(chǔ)引擎的索引實(shí)現(xiàn),跟myisam最大的區(qū)別在于說(shuō),innodb的數(shù)據(jù)文件本身就是個(gè)索引文件,就是主鍵key,然后葉子節(jié)點(diǎn)的data就是那個(gè)數(shù)據(jù)的所在行。我們還是用上面那個(gè)索引起來(lái)現(xiàn)場(chǎng)手畫(huà)一下這個(gè)索引好了,給大家來(lái)感受一下。
innodb存儲(chǔ)引擎,要求必須有主鍵,會(huì)根據(jù)主鍵建立一個(gè)默認(rèn)索引,叫做聚簇索引,innodb的數(shù)據(jù)文件本身同時(shí)也是個(gè)索引文件,索引存儲(chǔ)結(jié)構(gòu)大致如下:
15,data:0x07,完整的一行數(shù)據(jù),(15,張三,22)。
22,data:完整的一行數(shù)據(jù),(22,李四,30)。
就是因?yàn)檫@個(gè)原因,innodb表是要求必須有主鍵的,但是myisam表不要求必須有主鍵。另外一個(gè)是,innodb存儲(chǔ)引擎下,如果對(duì)某個(gè)非主鍵的字段創(chuàng)建個(gè)索引,那么最后那個(gè)葉子節(jié)點(diǎn)的值就是主鍵的值,因?yàn)榭梢杂弥麈I的值到聚簇索引里根據(jù)主鍵值再次查找到數(shù)據(jù),即所謂的回表,例如:
select * from table where name = ‘張三’。
先到name的索引里去找,找到張三對(duì)應(yīng)的葉子節(jié)點(diǎn),葉子節(jié)點(diǎn)的data就是那一行的主鍵,id=15,然后再根據(jù)id=15,到數(shù)據(jù)文件里面的聚簇索引(根據(jù)主鍵組織的索引)根據(jù)id=15去定位出來(lái)id=15這一行的完整的數(shù)據(jù)
所以這里就明白了一個(gè)道理,為啥innodb下不要用UUID生成的超長(zhǎng)字符串作為主鍵?因?yàn)檫@么玩兒會(huì)導(dǎo)致所有的索引的data都是那個(gè)主鍵值,最終導(dǎo)致索引會(huì)變得過(guò)大,浪費(fèi)很多磁盤(pán)空間。
還有一個(gè)道理,一般innodb表里,建議統(tǒng)一用auto_increment自增值作為主鍵值,因?yàn)檫@樣可以保持聚簇索引直接加記錄就可以,如果用那種不是單調(diào)遞增的主鍵值,可能會(huì)導(dǎo)致b+樹(shù)分裂后重新組織,會(huì)浪費(fèi)時(shí)間。
(4)索引的使用規(guī)則
一般來(lái)說(shuō)跳槽時(shí)候,索引這塊必問(wèn),b+樹(shù)索引的結(jié)構(gòu),一般是怎么存放的,出個(gè)題,針對(duì)這個(gè)SQL,索引應(yīng)該怎么來(lái)建立
select * from table where a=1 and b=2 and c=3,你知道不知道,你要怎么建立索引,才可以確保這個(gè)SQL使用索引來(lái)查詢
好了,各位同學(xué),聊到這里,你應(yīng)該知道具體的myisam和innodb索引的區(qū)別了,同時(shí)也知道什么是聚簇索引了,現(xiàn)場(chǎng)手畫(huà)畫(huà),應(yīng)該都o(jì)k了。然后我們?cè)賮?lái)說(shuō)幾個(gè)最最基本的使用索引的基本規(guī)則。
其實(shí)最基本的,作為一個(gè)java碼農(nóng),你得知道最左前綴匹配原則,這個(gè)東西是跟聯(lián)合索引(復(fù)合索引)相關(guān)聯(lián)的,就是說(shuō),你很多時(shí)候不是對(duì)一個(gè)一個(gè)的字段分別搞一個(gè)一個(gè)的索引,而是針對(duì)幾個(gè)索引建立一個(gè)聯(lián)合索引的。
給大家舉個(gè)例子,你如果要對(duì)一個(gè)商品表按照店鋪、商品、創(chuàng)建時(shí)間三個(gè)維度來(lái)查詢,那么就可以創(chuàng)建一個(gè)聯(lián)合索引:shop_id、product_id、gmt_create
一般來(lái)說(shuō),你有一個(gè)表(product):shop_id、product_id、gmt_create,你的SQL語(yǔ)句要根據(jù)這3個(gè)字段來(lái)查詢,所以你一般來(lái)說(shuō)不是就建立3個(gè)索引,一般來(lái)說(shuō)會(huì)針對(duì)平時(shí)要查詢的幾個(gè)字段,建立一個(gè)聯(lián)合索引
后面在java系統(tǒng)里寫(xiě)的SQL,都必須符合最左前綴匹配原則,確保你所有的sql都可以使用上這個(gè)聯(lián)合索引,通過(guò)索引來(lái)查詢
(1)全列匹配
這個(gè)就是說(shuō),你的一個(gè)sql里,正好where條件里就用了這3個(gè)字段,那么就一定可以用到這個(gè)聯(lián)合索引的:
(2)最左前綴匹配
這個(gè)就是說(shuō),如果你的sql里,正好就用到了聯(lián)合索引最左邊的一個(gè)或者幾個(gè)列表,那么也可以用上這個(gè)索引,在索引里查找的時(shí)候就用最左邊的幾個(gè)列就行了:
select * from product where shop_id=1 and product_id=1,這個(gè)是沒(méi)問(wèn)題的,可以用上這個(gè)索引的。
(3)最左前綴匹配了,但是中間某個(gè)值沒(méi)匹配
這個(gè)是說(shuō),如果你的sql里,就用了聯(lián)合索引的第一個(gè)列和第三個(gè)列,那么會(huì)按照第一個(gè)列值在索引里找,找完以后對(duì)結(jié)果集掃描一遍根據(jù)第三個(gè)列來(lái)過(guò)濾,第三個(gè)列是不走索引去搜索的,就是有一個(gè)額外的過(guò)濾的工作,但是還能用到索引,所以也還好,例如:
就是先根據(jù)shop_id=1在索引里找,找到比如100行記錄,然后對(duì)這100行記錄再次掃描一遍,過(guò)濾出來(lái)gmt_create=’2018-01-01 10:00:00’的行。
這個(gè)我們?cè)诰€上系統(tǒng)經(jīng)常遇到這種情況,就是根據(jù)聯(lián)合索引的前一兩個(gè)列按索引查,然后后面跟一堆復(fù)雜的條件,還有函數(shù)啥的,但是只要對(duì)索引查找結(jié)果過(guò)濾就好了,根據(jù)線上實(shí)踐,單表幾百萬(wàn)數(shù)據(jù)量的時(shí)候,性能也還不錯(cuò)的,簡(jiǎn)單SQL也就幾ms,復(fù)雜SQL也就幾百ms。可以接受的。
(4)沒(méi)有最左前綴匹配
那就不行了,那就在搞笑了,一定不會(huì)用索引,所以這個(gè)錯(cuò)誤千萬(wàn)別犯。
select * from product where product_id=1,這個(gè)肯定不行。
(5)前綴匹配
這個(gè)就是說(shuō),如果你不是等值的,比如=,>=,<=的操作,而是like操作,那么必須要是like ‘XX%’這種才可以用上索引,比如說(shuō):
(6)范圍列匹配
如果你是范圍查詢,比如>=,<=,between操作,你只能是符合最左前綴的規(guī)則才可以范圍,范圍之后的列就不用索引了。
這里就在聯(lián)合索引中根據(jù)shop_id來(lái)查詢了。
(7)包含函數(shù)
如果你對(duì)某個(gè)列用了函數(shù),比如substring之類(lèi)的東西,那么那一列不用索引。
上面就根據(jù)shop_id在聯(lián)合索引中查詢
(5)索引的缺點(diǎn)以及使用注意
索引是有缺點(diǎn)的,比如常見(jiàn)的就是會(huì)增加磁盤(pán)消耗,因?yàn)橐加么疟P(pán)文件,同時(shí)高并發(fā)的時(shí)候頻繁插入和修改索引,會(huì)導(dǎo)致性能損耗的。
我們給的建議,盡量創(chuàng)建少的索引,比如說(shuō)一個(gè)表一兩個(gè)索引,兩三個(gè)索引,十來(lái)個(gè),20個(gè)索引,高并發(fā)場(chǎng)景下還可以。
字段,status,100行,status就2個(gè)值,0和1。
你覺(jué)得你建立索引還有意義嗎?幾乎跟全表掃描都差不多了。
select * from table where status=1,相當(dāng)于是把100行里的50行都掃一遍。
你有個(gè)id字段,每個(gè)id都不太一樣,建立個(gè)索引,這個(gè)時(shí)候其實(shí)用索引效果就很好,你比如為了定位到某個(gè)id的行,其實(shí)通過(guò)索引二分查找,可以大大減少要掃描的數(shù)據(jù)量,性能是非常好的。
在創(chuàng)建索引的時(shí)候,要注意一個(gè)選擇性的問(wèn)題,select count(discount(col)) / count(*),就可以看看選擇性,就是這個(gè)列的唯一值在總行數(shù)的占比,如果過(guò)低,就代表這個(gè)字段的值其實(shí)都差不多,或者很多行的這個(gè)值都類(lèi)似的,那創(chuàng)建索引幾乎沒(méi)什么意義,你搜一個(gè)值定位到一大坨行,還得重新掃描。
就是要一個(gè)字段的值幾乎都不太一樣,此時(shí)用索引的效果才是最好的。
還有一種特殊的索引叫做前綴索引,就是說(shuō),某個(gè)字段是字符串,很長(zhǎng),如果你要建立索引,最好就對(duì)這個(gè)字符串的前綴來(lái)創(chuàng)建,比如前10個(gè)字符這樣子,要用前多少位的字符串創(chuàng)建前綴索引,就對(duì)不同長(zhǎng)度的前綴看看選擇性就好了,一般前綴長(zhǎng)度越長(zhǎng)選擇性的值越高。
好了,各位同學(xué),索引這塊能聊到這個(gè)程度,或者掌握到這個(gè)程度,其實(shí)普通的互聯(lián)網(wǎng)系統(tǒng)中,80%的活兒都可以干了,因?yàn)樵诨ヂ?lián)網(wǎng)系統(tǒng)中,一般就是盡量降低SQL的復(fù)雜度,讓SQL非常簡(jiǎn)單就可以了,然后搭配上非常簡(jiǎn)單的一個(gè)主鍵索引(聚簇索引)+ 少數(shù)幾個(gè)聯(lián)合索引,就可以覆蓋一個(gè)表的所有SQL查詢需求了。更加復(fù)雜的業(yè)務(wù)邏輯,讓java代碼里來(lái)實(shí)現(xiàn)就ok了。
大家要明白,SQL達(dá)到95%都是單表增刪改查,如果你有一些join等邏輯,就放在java代碼里來(lái)做。SQL越簡(jiǎn)單,后續(xù)遷移分庫(kù)分表、讀寫(xiě)分離的時(shí)候,成本越低,幾乎都不用怎么改造SQL。
我這里給大家說(shuō)下,互聯(lián)網(wǎng)公司而言,用MySQL當(dāng)最牛的在線即時(shí)的存儲(chǔ),存數(shù)據(jù),簡(jiǎn)單的取出來(lái);不要用MySQL來(lái)計(jì)算,不要寫(xiě)join、子查詢、函數(shù)放MySQL里來(lái)計(jì)算,高并發(fā)場(chǎng)景下;計(jì)算放java內(nèi)存里,通過(guò)寫(xiě)java代碼來(lái)做;可以合理利用mysql的事務(wù)支持。