













譯者 | 朱先忠
審校 | 孫淑娟
工作區安全可能是公司中一種費力又費時的資金流失渠道,特別是對于處理敏感信息或擁有數千名員工的多個辦公室的公司而言。電子鑰匙是安全系統自動化的標準選擇之一,但實際上,仍然存在諸如丟失、遺忘或偽造鑰匙等不少缺點。
生物識別技術是傳統安全措施的可靠替代品,因為它們代表了“你是什么”身份驗證的概念。這意味著,用戶可以使用他們獨特的特征,如指紋、虹膜、聲音或面部,來證明他們能夠進入某個空間。使用生物特征作為身份驗證方法可以確保密鑰不會丟失、遺忘或偽造。因此,在本文中,我們將談談我們在邊緣生物特征方面的開發經驗,這是邊緣設備、人工智能和生物特征的組合,以實現一個基于人工智能技術的安全監控系統。
什么是邊緣生物特征?
首先,讓我們來理清:什么是邊緣AI?在傳統的人工智能體系結構中,常見的做法是在云中部署模型和數據,與操作設備或硬件傳感器分離。這迫使我們將云服務器保持在適當的狀態,保持穩定的互聯網連接,并為云服務付費。如果在互聯網連接中斷的情況下無法訪問遠程存儲,那么,整個AI應用程序將變得毫無用處。
“相比之下,邊緣AI的理念是在設備上部署人工智能應用程序,離用戶更近。邊緣設備可能有自己的GPU,允許我們在設備上就地處理輸入。
這提供了許多優點,例如由于所有操作都是在本地設備上執行的,所以延遲減少,總體成本和功耗也變得更低。此外,由于設備可以輕松地從一個位置移動到另一個位置,因此整個系統更具便攜性。
鑒于我們不需要大型生態系統,與依賴穩定互聯網連接的傳統安全系統相比,帶寬需求也較低。邊緣設備甚至可以在連接關閉的情況下運行,因為數據可以存儲在設備的內部存儲器中。這使得整個系統設計更加可靠和穩健。”
——丹尼爾·利亞多夫(MobiDev的Python工程師)
唯一值得注意的缺陷是,所有處理都必須在短時間內在設備上完成,硬件組件必須足夠強大,并且必須是最新的,才能實現此功能。
對于人臉或語音識別等生物特征認證任務,安全系統的快速響應和可靠性至關重要。因為我們希望確保無縫的用戶體驗和適當的安全性,所以依靠邊緣設備可以帶來這些好處。
生物特征信息,如員工的臉和聲音,似乎足夠安全,因為它們代表了神經網絡可以識別的獨特模式。此外,這種類型的數據更容易收集,因為大多數企業在其CRM或ERP中已經有員工的照片。這樣,你還可以通過收集你的員工的指紋樣本來避免任何隱私問題。
結合邊緣技術,我們可以為工作區入口創建靈活的AI安全攝像頭系統。下面,我們將根據我們自己公司的開發經驗,并借助邊緣生物特征,來討論如何實現這樣的一個系統。
人工智能監控系統設計
該項目的主要目的是在辦公室入口處對員工進行身份驗證,只需看一眼攝像機即可。計算機視覺模型能夠識別一個人的臉,將其與之前獲得的照片進行比較,然后控制門的自動打開。作為一項額外措施,還將添加語音驗證支持,以避免以任何方式欺騙系統。整個流水線由4個模型組成,它們分別負責執行從人臉檢測到語音識別的各項不同任務。
所有這些措施都是通過一個用作視頻/音頻輸入傳感器的單一器件以及一個用于發送鎖止/解鎖命令的控制器來完成的。作為邊緣設備,我們選擇使用NVIDIA公司的??Jetson Xavier??。之所以作出這一選擇,主要是因為此設備使用了GPU內存(這對于加速深入學習項目的推理至關重要),而且NVIDIA公司提供的Jetpack–SDK也高度可用——支持在基于Python3環境的設備上進行編碼。因此,沒有嚴格的必要將DS模型轉換為另一種格式,幾乎所有的代碼庫都可以由DS工程師根據設備進行調整;而且,也不需要從一種編程語言重寫為另一種語言形式。
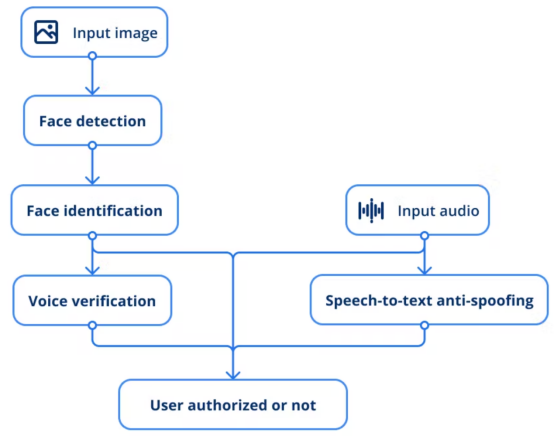
AI安全系統工作流程
根據上面的描述,整個過程遵循如下流程:
1. 將輸入圖像提供給人臉檢測模型以查找用戶。
2. 人臉識別模型通過提取向量并將其與現有員工照片進行比較來進行推斷,以確定是否是同一個人。
3. 另一個模型是通過語音樣本來驗證特定人的語音。
4. 此外,采用語音到文本反欺騙方案以防止任何類型欺騙技術。
接下來,讓我們討論每一個實現環節,并詳細說明訓練和數據收集過程。
數據采集
在深入研究系統模塊之前,一定要注意所使用的數據庫。我們的系統依賴于為用戶提供所謂的參考或基本事實數據。該數據目前包括每個用戶的預計算人臉和語音矢量,看起來像一個數字數組。系統還存儲成功登錄的數據,以備日后重新訓練使用。鑒于此,我們選擇了最輕量級的解決方案SQLite DB。有了這個數據庫,所有數據都存儲在一個易于瀏覽和備份的文件中,而且數據科學工程師的學習時間更短。
因為面部識別需要所有可能進入辦公室的員工的照片,所以我們使用存儲在公司數據庫中的面部照片。當人們使用面部驗證來開門時,放置在辦公室門口的Jetson設備也收集了面部數據樣本。
最初語音數據不可用,所以我們組織采集數據,要求人們錄制20秒的片段。然后,我們使用語音驗證模型來獲取每個人的矢量,并將其存儲在數據庫中。你可以使用任何音頻輸入設備采集語音樣本。在我們的項目中,我們使用便攜手機和內置麥克風的網絡攝像頭來錄制聲音。
面部檢測
人臉檢測可以確定給定場景中是否存在人臉的問題。如果有,模型應該給出每個面部的坐標,以便您知道每個臉在圖像上的位置,包括面部標志。此信息很重要,因為我們需要在邊界框中接收一個面部,以便在下一步中運行人臉識別。
對于人臉檢測,我們使用了??RetinaFace模型??和InsightFace項目中的MobileNet關鍵組件。該模型輸出圖像上每個檢測到的人臉的四個坐標以及5個人臉標記。事實上,以不同角度或使用不同光學元件拍攝的圖像可能會因變形而改變面部的比例。這可能會導致模型難以識別此人。
為了滿足這一需求,面部標志被用來進行變形,這是一種減少同一個人的這些圖像之間可能存在的差異的技術。因此,獲得的裁剪面和扭曲面看起來更相似,提取的臉向量也更準確。
面部識別
下一步是人臉識別。在這個階段,模型必須從給定的圖像(即獲得的圖像)中識別出人。識別是在參考(地面真實數據)的幫助下完成的。因此,在這里,模型將通過測量兩個向量之間差異的距離分數來比較兩個向量,以判斷站在相機前的是不是同一個人。該評估算法將與我們所擁有的一名員工的初始照片進行比較。
人臉識別是使用??SE-ResNet-50架構??的模型完成的。為了使模型結果更加穩健,在獲得人臉矢量輸入之前,圖像將被翻轉一下來進行平均化處理。此時,用戶標識流程如下:
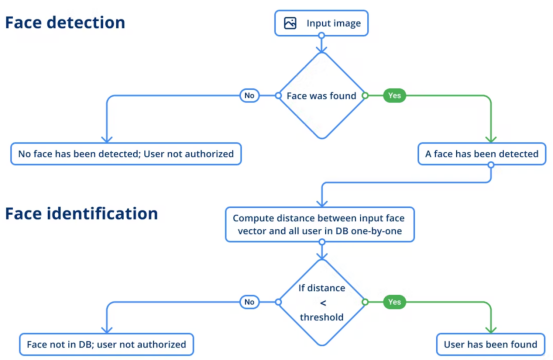
人臉和語音驗證流程
語音驗證
接下來,我們轉到語音驗證環節。此步驟應該完成驗證兩個音頻是否包含同一個人的聲音。你可能會問,為什么不考慮語音識別呢?答案是,現在面部識別的效果比語音好得多,圖像比語音能提供更多的信息來識別用戶。為了避免出現通過面部識別用戶A而通過語音識別用戶B,系統只采用了面部識別方案。
基本邏輯與人臉識別階段幾乎相同,因為我們通過向量之間的距離來比較兩個向量,除非我們找到相似的向量。唯一的區別是,我們已經有了一個關于誰是試圖從前面的人臉識別模塊中通過的人的假設。
在語音驗證模塊的積極開發過程中,出現了許多問題。
之前采用Jasper架構的型號無法驗證同一個人從不同話筒上錄制的錄音。因此,我們通過使用??ECAPA-TDNN架構???解決了這個問題,該架構在??SpeechBrain框架的VoxCeleb2??數據集上進行了訓練,它在驗證員工方面做得更好。
然而,音頻片段仍然需要一些預處理。目的是通過保留聲音和減少當前背景噪音來提高音頻錄制質量。然而,所有測試技術都嚴重影響了語音驗證模型的質量。很可能,即使是最輕微的降噪也會改變錄音中的語音音頻特性,因此模型將無法正確驗證此人。
此外,我們還調查了音頻錄制的長度以及用戶應該發音多少個單詞。作為這次調查的結果,我們提出了一些建議。結論是:這種錄音的持續時間應至少為3秒,需要朗讀大約8個單詞。
語音到文本反欺騙
最后一個安全方面的措施是,系統應用了Nemo框架中基于??QuartzNet??構建的語音到文本反欺騙。該模型提供了良好的用戶體驗,適用于實時場景。要衡量一個人所說的與系統期望的接近程度,需要計算他們之間的Levenshtein距離。
獲取員工的照片以欺騙面部驗證模塊是一項可以實現的任務,同時還可以錄制語音樣本。語音到文本反欺騙不包括入侵者試圖使用授權人員的照片和音頻進入辦公室的場景。這個想法很簡單:當每個人驗證自己時,他們會說出系統給出的短語。短語由一組隨機選擇的單詞組成。雖然短語中的單詞數量并不多,但實際可能的組合數量是相當巨大的。應用隨機生成的短語,我們消除了欺騙系統的可能性,因為它需要授權用戶說出大量錄制的短語。擁有一張用戶的照片不足以欺騙具有此保護的AI安全系統。
邊緣生物特征識別系統的優點
此時,我們的邊緣生物識別系統讓用戶遵循一個簡單的操作流程,這需要他們說出一個隨機生成的短語來解鎖門。此外,通過人臉檢測,我們為辦公室入口提供人工智能監控服務。
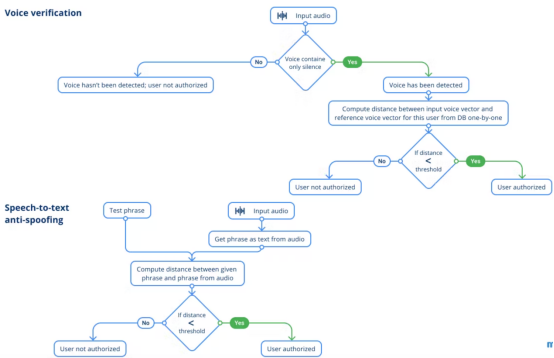
語音驗證和語音到文本反欺騙模塊
“通過添加多個邊緣設備,系統經輕松修改即可擴展應用到不同的場景中。與普通計算機相比,我們可以通過網絡直接配置Jetson,通過GPIO接口與低級設備建立連接,并很容易用新硬件進行升級。我們還可以與任何具有web API的數字安全系統集成。
但此方案的主要好處在于,我們可以直接從設備收集數據來改進系統,因為在入口處收集數據似乎非常方便,不存在任何特定的中斷。”
——丹尼爾·利亞多夫(MobiDev的Python工程師)
譯者介紹
朱先忠,51CTO社區編輯,51CTO專家博客、講師,濰坊一所高校計算機教師,自由編程界老兵一枚。
原文標題:??Developing AI Security Systems With Edge Biometrics??,作者:Dmitriy Kisil




















