聊聊大數據下的存算分離
最近跟好幾個用戶在交流的時候都提到了大數據的存算分離,有的是云廠商給他們推薦的方案,比如:某某運營商說最近xx云一直在給他們推薦存算分離化改造,背景是有個幾十臺的HDFS小集群,存儲的文件數量比較多,經常性出問題,xx云的商務就跟他們說用對象存儲如何如何來解決問題,聽起來感覺有點道理,但是又拿不定主意,畢竟整個改造過程動靜大、周期長,而且需要很大的投入,無論從建設周期還是成本投入上來看,都需要慎重考慮。有的是為了技術棧統一,比如:某某醫藥類企業,在整體技術架構重構時,已經引入了xx對象存儲,基于技術棧統一的角度,想了解下大數據基于對象存儲下存算分離是否可行,如果可行,有沒有什么潛在的風險?
上面的兩個例子,都是最近碰到的,相信有類似疑問的用戶還有很多,正好最近2年,我們在內部也在做集群的存算分離化改造,接下去,我們就來談談對于大數據做存算分離這件事到底應該怎么來考慮。個人認為:大數據集群是否適合做存算分離,主要從兩個方面來考慮:
技術層面:存算分離是否能夠簡化我們的技術棧,或者解決某些瓶頸問題。
成本層面:存算分離能否在計算性能、存儲空間等方面帶來成本上的優勢。
1.存算分離和存算一體化
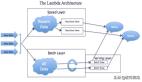
相信早期的大數據集群的建設,都是采用存算一體化的形式進行的,購買幾臺即包含計算資源又帶一定存儲的機型來搭建整個大數據集群,如下圖:

存算一體化的集群中每個節點都具備相同的硬件配置,我們早期內部典型的配置基本上是:48核,256GB內存,12塊8T SATA盤,整體提供約48個CU(1CU包含1核,4GB內存)和96TB的存儲。
隨著業務的發展,我們發現,類似上述存算一體化的架構,在發展到一定階段的時候,整體集群中的資源需求會打破原來存儲計算之間的比例平衡,造成某一類資源的利用率一直無法提升。比如:內部某業務在兩年的時間內數據存儲量上漲到原來的4倍,而計算資源只上漲到原來的2倍,數據存儲量需求明顯比計算資源增長快,這時,如果繼續采用存算一體化的機型就意味著我要滿足存儲資源增長的同時,計算資源也會增長4倍,而實際的需求只要2倍,計算資源存在過剩的情況。
除了業務外,技術上的不斷革新帶來計算能力的提升,也會導致原先的存算一體化資源配置出現比例失調的現象。就拿大數據領域離線計算來說,從最初的Hive發展到Spark,而Spark從Spark1.x到當前的Spark3.x,相比于最早初的框架的能力,整體性能上有數量級的提升。
綜上,業務和技術的不斷發展,會造成原先存算一體化體系下存儲和計算的比例不斷發生變化,我們很難找到一種合適的機型來滿足不斷變化的需求。因此,我們在后續的采購過程中,進行了部分存算分離采購的調整:計算資源和存儲資源進行單獨的方式采購,并且存儲和計算都分別采用了更高密度的機型,從而把線上集群調整到一種合適的存算比例。

存算分離改造帶來的另外一大好處是把原先大數據計算過程中的離散I/O(shuffle數據)和順序I/O(數據塊)進行了很好的拆分,解決了計算過程中的I/O瓶頸,從而進一步提升了CPU的利用率。


通過上述存算分離化改造,集群中大部分節點的資源利用率有了大幅度提升,全天CPU 95峰值維持在90%左右,平均CPU利用率從25%提升到55%以上。

2.存算分離和多層存儲
基于業務和技術的發展,對集群進行存算分離化改造能夠提升整體的計算資源利用率,在此基礎之上,根據業務自身發展的特性,還可以對業務的存儲做多層存儲拆分,進一步降低數據存儲的成本。
一般來說,業務的數據量是一直不斷在增長的,而應用使用的數據,都具有一定的時效性,更多的會集中在最近一兩個月甚至最近一兩周的數據,大量歷史數據更多的是在某些特殊的場景下會被利用到,比如:幾個月前的用戶行為數據。大量的存儲空間被這種重要但已經“過期”的數據所占據。在大部分的存儲系統中,經常被訪問的數據(熱數據)一般只占了15% ~ 25%,而不經常被訪問的數據(冷數據)卻占了75% ~ 85%。由于冷數據不活躍的特點,如果對冷數據的存儲進行一定的改造,將會取得較為不錯的成本收益。

上圖中,我們對原本存在IDC1中的存儲集群做了一定的拆分,把原本一個集群拆分成兩個集群,分別稱之為:熱集群和冷集群,熱集群的搭建與原先一致,而冷集群在搭建的時候,我們采用了EC(糾刪碼)的方式進行了改造,使得大量的冷數據在保證原來的高可用性的同時,存儲成本降至原來的50%,在業務具有較大規模冷數據的情況下,該種方式也可以為業務減少大量數據存儲成本。
3.存算分離和計算混部
存儲上可以根據數據冷熱做到多層存儲,計算層也可以通過一定的混部措施來提升業務整體計算的利用率。按照業務的特性,一般在線的業務高峰期每天的10:00-24:00,而離線計算的高峰期在24:00-8:00,從時間分布來看,在線業務與離線業務存在較好的互補特性。因此,如果能夠把部分離線的任務在在線業務的低峰期,能跑在在線業務的服務器上,做到在線離線業務混合部署,也是可以節省離線計算服務器。

2021年,杭研大數據聯合云計算、傳媒數據團隊在傳媒大數據場景下進行了在線/離線計算混合部署試點,試著把業務的Spark任務調度到輕舟K8s上,使得大數據任務在業務在線業務低峰實現混部,從而減少整個BU大數據計算的節點數量。

4.云環境下的存算分離
大數據私有場景下的存算分離一般通過把存儲和計算拆開,分別采用更高密度的存儲/計算機型來節省整個成本,存儲依舊采用HDFS的方式來搭建集群。而在云環境下,本身提供了對象存儲服務(如:S3,OSS,OBS等),在搭建大數據平臺的時候,是否可以選用對象存儲來做大數據存儲的底層。答案當然是可以,而且大多數云上大數據方案都是這么做的,如:AWS的EMR、阿里云的MaxCompute、華為的MRS等等。杭研大數據團隊針對不同的客戶需求,也設計了云上部署方案,如下:

在上述整個云上部署方案中,我們采用了云平臺的云主機來搭建計算引擎,同時使用了各家云平臺的對象存儲來作為底層數據存儲。云上部署平臺相比于云下私有化部署的大數據平臺來說,最顯著的一個變化就是用對象存儲+Block Cache的方式替換了原來的HDFS存儲,之所以引入Block Cache主要有兩方面的因素考慮:Block Cache通過標準協議,能夠屏蔽底層不同對象存儲,使得整體對上層計算無感知 Block Cache兼具緩存功能,能夠盡量減少遠程對象存儲訪問延遲對計算任務的影響。
除了架構上有些許不同之外,采用云原生對象存儲作為大數據的存儲層,需要考慮性能上的影響,比如,對象存儲對于像remove之類的命令,整體性能會比較低下,特別是在對大目錄的remove上,而大數據計算場景下,會有較多的insert overwrite操作,會頻繁的去刪除老的數據后寫入新的數據。因此對于像remove類的接口,如果性能很差,會大幅度影響計算性能。
5.總結
回過頭來看看開頭的兩個問題:集群經常出問題,需要做存算分離改造,其實還可以有較大的優化空間,比如:增加NameNode JVM的內存,或者合并小文件減少元數據信息等等,一般情況下,幾十臺的規模遠不會達到HDFS性能瓶頸。
至于第二個,為了技術棧的統一,需要衡量對象存儲給大數據計算造成的性能影響后再來綜合考慮。
作者簡介
蔣鴻翔,服務端開發專家。2011年加入網易杭州研究院,主要負責大數據基礎設施類工作,同時承擔內部業務線上大數據集群穩定性保障、協助業務線上技術框架落地,解決業務實際生產過程中的各種問題,與業務一起改進線上技術框架,從而實現降本增效等目的。