打破不可能三角、比肩5400億模型,IDEA封神榜團隊僅2億級模型達到零樣本學習SOTA
自從 GPT-3 問世,展現(xiàn)出千億級模型的強大實力以來,NLP 任務面臨著規(guī)模、樣本、Fine-tuning 性能的不可能三角。如何在保證 10 億參數(shù)以下的語言模型可以達到 SOTA 的 Few-Shot (甚至是 Zero-shot)還有 Fine-tuning 的性能?一定要上千億的參數(shù)并且忍受不穩(wěn)定的 prompt 提示才可以解決 zero-shot 場景嗎?本文中,IDEA 研究院封神榜團隊介紹了一種新的「表現(xiàn)型」UniMC,僅有 2 億參數(shù)即可達到 Zero-shot 的 SOTA。相關工作已經(jīng)被 EMNLP 2022 接收。
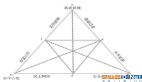
在今年的一篇文章 [1] 中指出,自預訓練技術被提出以來,NLP 界一直存在著一個不可能三角(如下圖 1),即一個模型不能同時滿足:
- 中等模型大小(10 億以下);
- SOTA 的 Few-Shot (甚至是 Zero-shot)性能;
- SOTA 的 Fine-tuning 性能。

圖 1
不可能三角存在的原因是,當前預訓練模型的參數(shù)量只有達到一定的數(shù)量級,并且使用提示學習才能體現(xiàn)出強大的 few/zero-shot 性能。
最近我們封神榜團隊被 EMNLP 2022 收錄的論文:《Zero-Shot Learners for Natural Language Understanding via a Unified Multiple Choice Perspective》則打破了這一「魔咒」,提供了一個靈活高效的解決思路。我們的論文提出的 UniMC 在擁有模型參數(shù)量很小(僅僅是億級)和 SOTA 的 Fine-tuning 能力的前提下,同時還能擁有(與 5400 億的 PaLM 相當?shù)模?SOTA 的 Few/Zero-Shot 性能。
 ?
?
- 論文地址:https://arxiv.org/abs/2210.08590
- 模型開源地址:https://github.com/IDEA-CCNL/Fengshenbang-LM/tree/main/fengshen/examples/unimc/
技術背景
2018 年 BERT 的提出,標志著整個 NLP 領域進入一個預訓練時代,NLP 的百尺竿頭終于更進一步。現(xiàn)有的模型如 DeBERTa 等預訓練掩碼語言模型(PMLM)已經(jīng)可以在 10 億級以下的參數(shù)做到 fine-tuning 的 SOTA 了,但是面對 Zero-shot 場景下的 NLU 任務時表現(xiàn)無力。
原因在于,使用 PMLM 的時候,我們需要在其頂部針對具體任務增加一個 MLP 層,如圖 2(c)。并且,這個 MLP 層會增加額外的參數(shù),這使得這種方法面對 Zero-shot 場景時,只能選擇隨機初始化,根本沒辦法獲得合理的輸出。而且,在 finetuning 的場景下,增加 MLP 層也會造成不同任務之間是無法遷移的(比如,2 分類和 3 分類任務之間無法遷移)。
針對 Zero-shot 場景,近年來的主流做法是利用上百億乃至千億的預訓練語言模型(PLM)統(tǒng)一將 NLU 任務轉化為文本生成任務,這樣可以通過人工構造 prompt 或者是人工設計 verbalizer 使得大模型可以應用于 zero-shot 任務上,如圖 2(a)。進一步地,F(xiàn)LAN 論文中,使用了大量人工構造的模版來統(tǒng)一了不同的任務,使得別的任務的知識可以遷移到特定任務上,如圖 2(b)。不過,這樣的生成模型具有以下缺點:
- 生成模型需要將 verbalizer(標簽描述)給生成出來,而 verbalizer 通常由人工進行編寫,不同的 verbalizer 會導致較大的性能差異;
- prompt 也需要人工設計,不同的 prompt 會極大影響下游任務的效果;
- 生成模型在推理時,需要自回歸的生成答案,速度較慢。并且一般是單向的,無法像 BERT 一樣可以獲取雙向信息;
- 為保證 few/zero-shot 性能,生成模型參數(shù)量往往較大,達到 GPT-3 的 1750 億或者是 PaLM 的 5400 億;
- 雖然 FLAN 的 Instruction tuning 可以遷移別的任務的知識到特定任務上,但是面對不同任務需要新的訓練。比如,評估 A 時,需要在 BCDE 上訓練;評估 B 時,需要在 ACDE 上訓練。
而我們提出了圖 2(d)中 UniMC 的方法,避免了上述問題,并且在中英文數(shù)個任務中達到了 SOTA 或者是與最先進模型相近的表現(xiàn)。

圖 2
UniMC(一個新的模型表現(xiàn)型)
模型思路?
大部分的 NLU 任務都是基于標簽的,而生成模型需要將標簽給生成出來,這無疑是加重了任務的難度和模型的學習成本。對于許多基于標簽的任務(Label-based Task)來說,通常只需要給定輸入文本,輸出文本屬于每種 label 的概率即可。基于這個思路,我們將 NLU 任務轉化為多項選擇任務(Multiple-Choice)。即給定文本、問題和選項,輸出每個選項的概率,而不需要將選項生成出來。
在此基礎之上,我們提出一個新的概念:模型的表現(xiàn)型。現(xiàn)有的模型表現(xiàn)型,都是在后面添加某個層,比如分類層。或者是,生成模型 GPT 的表現(xiàn)型是通過 Prompt 來挖掘模型的知識。而我們提出的 UniMC 方案不需要在 PMLM 引入任何額外的層,挖掘了另一種 PMLM 的表現(xiàn)型。
在本論文中,我們選擇了 ALBERT 作為我們的骨干 PMLM 網(wǎng)絡。
統(tǒng)一的多項選擇格式
如圖 3,我們希望把基于標簽的 NLU 任務都轉換成統(tǒng)一的 MC(Multiple-Choice)格式。我們的理念是,盡可能少添加人工信息。

圖 3
具體地說,我們做了如下兩步:
- 把 label 變成 option;
- 選擇是否添加 question prompt(question 基本來自數(shù)據(jù)集的描述)。
優(yōu)點:只設計了一種 option prompt,設計一種或者是沒有 question prompt。
模型結構?
UniMC 的結構如下圖 4 所示,它采用類似于 BERT 的自編碼結構。主要流程為,我們先統(tǒng)一好不同任務的輸入,并且限制好輸入信息之間的流通性,經(jīng)過 PMLM 之后,利用 O-MLM、OP 和 MLM 進行 MC training,最后使用 O-MLM 和 OP 進行 zero-shot 預測。接下來我將一步一步地拆解我們的方案。

圖 4
輸入 Input ?
如圖 5 紅色實線框區(qū)域內容。在輸入到 UniMC 之前還要處理一下,變成 UniMC 特有的 token 格式。為了提升計算效率,我們將所有選項與問題和文本進行直接拼接,即 [Options, Question, Passage]。并且我們在每一個選項的前面插入一個特殊的 token,[O-MASK],用來表示 yes 或 no(選不選這個選項)。(注,為了可以提高復用性,我們復用了[MASK] token。
如圖 5 綠色虛線框區(qū)域內容。我們需要考慮輸入信息源太多,有選項信息、問題信息和文本段信息。它們之間的信息會相互影響,所以我們希望隔絕不同的信息。比如,我們在輸入的時候,假如可以看到別的選項,那么這道題的難度就下降了,模型會有惰性。
因此我們進行了如下考慮:
- 使用 Segment ID,告訴模型 option 和 context(question,passage)信息是不同的;
- 修改 Postion ID,需要模型同等地看待不同 option 的位置信息;
- 修改 Attention Mask 矩陣,避免模型可以看到不同 option 的信息導致模型產生惰性。

圖 5
模型如何做選擇題?(O-MLM 和 OP)
如圖 6,我們利用 O-MLM 和 OP 任務來讓模型可以去「選擇」答案。O-MASK 完全繼承于 MASK token(具體地,為了不添加額外的參數(shù)以及充分利用模型在無監(jiān)督預訓練階段所學習到的知識,我們復用了 MaskLM head 的參數(shù))。唯一不同的是,它是 100% 被 mask 的。O-MLM 任務的目標就是把 O-MASK 解碼出 ‘yes’ 或 ‘no’,其用來預測該選項是否被選擇。
而 OP 任務的作用在于,從各個選項的‘yes’中預測答案。具體地,我們取每個 [O-MASK] 輸出的 ‘yes’ 的 logit 進行 softmax 得到每個選項的概率,取概率最大的的選項最為預測答案即可。

圖 6
在一個 Batch 中處理多個 MC 任務
如圖 7,我們希望在一個 batch 中放入多個 MC 數(shù)據(jù)集,這樣可以增強模型的能力,而且,也更加統(tǒng)一(Unified)。我們在構建 batch 的時候,發(fā)現(xiàn)了一個問題:假如,一個 batch 里面有不同選項的 sample 呢?
所以我們在輸出的前面,再設計了一個 logit mask 的方法。直接給無關的 token 賦予一個負無窮大的預測值,加起來,我們就可以在計算 softmax 的時候消除別的 token 對于 O-MASK 的影響了。并且,不同數(shù)量的多項選擇題可以在一個 batch 中統(tǒng)一處理。?

圖 7
模型訓練和預測
MC Training?
與 FLAN 的 Instruction Tuning 不同,我們僅僅在 MC 數(shù)據(jù)集上進行訓練,這主要是為了讓模型學會如何做選擇題,并且 MC 數(shù)據(jù)集具有一定的通用性,比如,不同的數(shù)據(jù)集可能由數(shù)量不等的標簽組成。

圖 8
Zero-shot Inference
有趣的是,我們可以發(fā)現(xiàn),這兩個任務,是可以在 Training 和 zero-shot inference 兩個階段擁有一致性的。這是因為我們都是使用了 O-MLM 和 OP 兩個任務來實現(xiàn)讓模型做選擇題。并且由于我們拋棄了分類層,所有的參數(shù)都可以復用,這樣一來就激活了 PMLM 的 Zero-shot 能力。

圖 9
UniMC 性能
英文場景?
我們收集了 14 份 multiple -choice 任務進行預訓練,然后做其他 NLU 任務進行 zero-shot 性能測試。在 4 個 NLI 任務中, UniMC 取得了 SOTA 并且超越 5400 億參數(shù)的 PaLM 模型。

圖 10
并且我們在分類任務上擊敗了以 GPT-2 和 GPT-3 為骨干的網(wǎng)絡。對于非常困難的 Dbpedia 任務,高達 13 個類別,甚至可以達到 88.9% 的超高準確率。

圖 11
為了探究 UNIMC 的泛化性,我們和 FLAN 做了對比。可以看到,我們的 UniMC 幾乎可以在所有任務中超越 FLAN 或者是接近。

圖 12
中文場景
在中文場景中,我們收集了 40 份有監(jiān)督數(shù)據(jù)集,并統(tǒng)一構造成為 MC 的任務形式對 UniMC 模型進行預訓練,然后在 FewCLUE 和 ZeroCLUE 的 9 個任務上進行測試。截止 2022 年 8 月 30 日,UniMC 取得了 FewCLUE 和 ZeroCLUE 雙榜第一(圖中的二郎神 - UnifiedMC 即為 UniMC)。

圖 13

圖 14
總結
我們提出了一個新穎的 Zero-shot 場景下的 NLU 任務的解決方案,僅利用億級的參數(shù)量就戰(zhàn)勝了千倍參數(shù)量的復雜大模型。
此外,我們幾乎沒有引入任何的人工信息。并且克服了 BERT 類模型的預訓練和微調不一致的問題,我們的訓練和預測是具有一致性的。我們甚至可以做到一次訓練,多次 zero-shot 預測,極大地節(jié)約了算力成本。?目前 IDEA 封神榜團隊已經(jīng)推出了超過 70 個預訓練大模型。
- 模型:https://huggingface.co/IDEA-CCNL
- 封神榜總論文(中英雙語):https://arxiv.org/abs/2209.02970
- 封神榜主頁:https://github.com/IDEA-CCNL/Fengshenbang-LM
引用
[1]Impossible Triangle: What's Next for Pre-trained Language Models?https://readpaper.com/paper/4612531641570566145