比較CPU和GPU中的矩陣計(jì)算
GPU 計(jì)算與 CPU 相比能夠快多少?在本文中,我將使用 Python 和 PyTorch 線(xiàn)性變換函數(shù)對(duì)其進(jìn)行測(cè)試。

以下是測(cè)試機(jī)配置:
CPU:英特爾 i7 6700k (4c/8t) GPU:RTX 3070 TI(6,144 個(gè) CUDA 核心和 192 個(gè) Tensor 核心) 內(nèi)存:32G 操作系統(tǒng):Windows 10
無(wú)論是cpu和顯卡都是目前常見(jiàn)的配置,并不是頂配(等4090能夠正常發(fā)貨后我們會(huì)給出目前頂配的測(cè)試結(jié)果)?
NVIDIA GPU 術(shù)語(yǔ)解釋
CUDA 是Compute Unified Device Architecture的縮寫(xiě)。可以使用 CUDA 直接訪(fǎng)問(wèn) NVIDIA GPU 指令集,與專(zhuān)門(mén)為構(gòu)建游戲引擎而設(shè)計(jì)的 DirectX 和 OpenGL 不同,CUDA 不需要用戶(hù)理解復(fù)雜的圖形編程語(yǔ)言。但是需要說(shuō)明的是CUDA為N卡獨(dú)有,所以這就是為什么A卡對(duì)于深度學(xué)習(xí)不友好的原因之一。
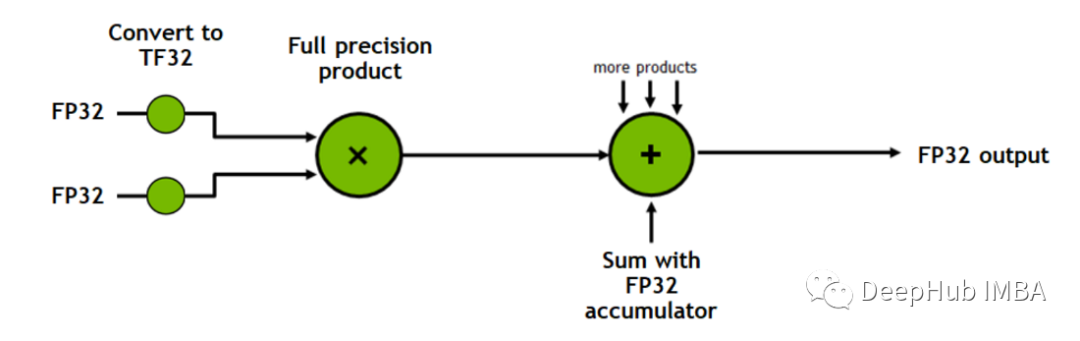
Tensor Cores是加速矩陣乘法過(guò)程的處理單元。
例如,使用 CPU 或 CUDA 將兩個(gè) 4×4 矩陣相乘涉及 64 次乘法和 48 次加法,每個(gè)時(shí)鐘周期一次操作,而Tensor Cores每個(gè)時(shí)鐘周期可以執(zhí)行多個(gè)操作。

上面的圖來(lái)自 Nvidia 官方對(duì) Tensor Cores 進(jìn)行的介紹視頻
CUDA 核心和 Tensor 核心之間有什么關(guān)系?Tensor Cores 內(nèi)置在 CUDA 核心中,當(dāng)滿(mǎn)足某些條件時(shí),就會(huì)觸發(fā)這些核心的操作。
測(cè)試方法
GPU的計(jì)算速度僅在某些典型場(chǎng)景下比CPU快。在其他的一般情況下,GPU的計(jì)算速度可能比CPU慢!但是CUDA在機(jī)器學(xué)習(xí)和深度學(xué)習(xí)中被廣泛使用,因?yàn)樗诓⑿芯仃嚦朔ê图臃ǚ矫嫣貏e出色。
上面的操作就是我們常見(jiàn)的線(xiàn)性操作,公式是這個(gè)
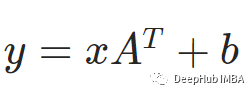
這就是PyTorch的線(xiàn)性函數(shù)torch.nn.Linear的操作。可以通過(guò)以下代碼將2x2矩陣轉(zhuǎn)換為2x3矩陣:
CPU 基線(xiàn)測(cè)試
在測(cè)量 GPU 性能之前,我需要線(xiàn)測(cè)試 CPU 的基準(zhǔn)性能。
為了給讓芯片滿(mǎn)載和延長(zhǎng)運(yùn)行時(shí)間,我增加了in_row、in_f、out_f個(gè)數(shù),也設(shè)置了循環(huán)操作10000次。
現(xiàn)在,讓我們看看CPU完成10000個(gè)轉(zhuǎn)換需要多少秒:
可以看到cpu花費(fèi)55秒。
GPU計(jì)算
為了讓GPU的CUDA執(zhí)行相同的計(jì)算,我只需將. To (' cpu ')替換為. cuda()。另外,考慮到CUDA中的操作是異步的,我們還需要添加一個(gè)同步語(yǔ)句,以確保在所有CUDA任務(wù)完成后打印使用的時(shí)間。
并行運(yùn)算只用了1.3秒,幾乎是CPU運(yùn)行速度的42倍。這就是為什么一個(gè)在CPU上需要幾天訓(xùn)練的模型現(xiàn)在在GPU上只需要幾個(gè)小時(shí)。因?yàn)椴⑿械暮?jiǎn)單計(jì)算式GPU的強(qiáng)項(xiàng)
如何使用Tensor Cores
CUDA已經(jīng)很快了,那么如何啟用RTX 3070Ti的197Tensor Cores?,啟用后是否會(huì)更快呢?在PyTorch中我們需要做的是減少浮點(diǎn)精度從FP32到FP16。,也就是我們說(shuō)的半精度或者叫混合精度
又是2.6倍的提升。
總結(jié)
在本文中,通過(guò)在CPU、GPU CUDA和GPU CUDA +Tensor Cores中調(diào)用PyTorch線(xiàn)性轉(zhuǎn)換函數(shù)來(lái)比較線(xiàn)性轉(zhuǎn)換操作。下面是一個(gè)總結(jié)的結(jié)果:

NVIDIA的CUDA和Tensor Cores確實(shí)大大提高了矩陣乘法的性能。
后面我們會(huì)有兩個(gè)方向的更新
1、介紹一些簡(jiǎn)單的CUDA操作(通過(guò)Numba),這樣可以讓我們了解一些細(xì)節(jié)
2、我們會(huì)在拿到4090后發(fā)布一個(gè)專(zhuān)門(mén)針對(duì)深度學(xué)習(xí)的評(píng)測(cè),這樣可以方便大家購(gòu)買(mǎi)可選擇