聊聊那些年遇到過的奇葩代碼
引言
無論是開發新需求還是維護舊平臺,在工作的過程中我們都會接觸到各種樣式的代碼,有時候會碰到一些優秀的代碼心中不免肅然起敬,但是更多的時候我們會遇到很多奇葩代碼,有的時候罵罵咧咧的吐槽一段奇葩代碼后定睛一看作者,居然是幾個月以前自己的寫的,心中難免浮現曹操的那句名言:不可能,絕對不可能。很多同學可能會說要求別太高了,代碼能跑就行。但是實際上代碼就是程序猿的名片,技術同學不能局限于實現功能需求,還是得有寫高質量代碼的追求。那么今天就和大家聊聊那些年遇到過的奇葩代碼,看看自己以前有沒有寫過這樣的代碼,現在還會不會這樣寫了。
奇葩代碼大賞
命名沒有業務語義
可能乍一看這段代碼其實沒啥大問題,但是如果要知道這段代碼到底是干嘛的可能你一下子反應不過來,需要好好看看代碼邏輯才知道。通過查看代碼我們知道此處的代碼業務語義是變更任務狀態,但是實際的方法名稱是handleTask,命名明顯過于寬泛了,不能精確表達實際的業務語義。
那么為什么要把代碼擼一遍才能明確方法的含義呢?歸根到底就是方法命名不夠準確,不能完全表達這段代碼所對應的業務語義。那為什么我們經常不能很準確的進行類或者方法的命名呢?我想最根本的原因還是碼代碼的同學沒能夠精準把握這段代碼的業務語義,因此在起名字的時候要么過于寬泛,要么詞不達意。
因此無論是類命名或者方法命名都要能夠明確的表達業務語義,只有這樣無論是一段時間自己回過頭來看或者其他維護者來看代碼都能夠通過看命名就可以明確代碼蘊含的業務邏輯。
單個方法過長
特別是在一些老項目中,我們經常會遇到一個方法里面能塞進去幾百行代碼。一般造成這種單個方法代碼過長的原因無非有兩個,一個是用過程化的思維編寫代碼,想到哪些業務步驟都統統寫在一個方法中;另一個就是后來的維護者需要增加新的功能,一看代碼這么長也不敢瞎改只能在長方法中繼續碼代碼,造成方法原來越長難以維護。
無論是從后期代碼可維護性還是從SRP設計原則來說,單個方法中代碼行數最好不要超過100行,否則帶來的后果就是各種業務邏輯糅合在一起,不僅后期維護代碼的同學不容易理解其中包含的業務語義,而且如果功能變化修改起來也比較費勁。
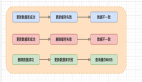
如上架鮮品的邏輯,可以看的出來在上架生鮮產品的時候會經歷貨品檢查、貨品擺渡、貨品上架等多個個步驟,但是在這個shelveFreshGoods方法中將這些業務步驟走雜糅在了一起,如果我們想修改或者增加業務邏輯的時候就需要在這個方法中只能在這個長方法中進行修改,可能會導致方法越來越長。而如果通過拆分的方式進行業務子過程劃分,也就是說將上述的幾個步驟都封裝成方法。那么修改某業務邏輯可直接在對應拆出來的步驟中進行,這樣修改的范圍就縮小了,另外業務邏輯看上去一目了然。
業務數據循環插入
在進行業務代碼開發的時候,批量進行業務數據插入是非常常見的CRUD基操。但是有的同學在寫批量插入接口的時候會這么寫,通過for循環或者stream來進行循環數據寫入。這樣的寫法會平白增加服務與數據庫的交互次數,占用不必要的數據庫連接,很容易遇到性能問題。如果一次性插入的數據不多的話(幾條數據)倒也影響不大,但是如果數據量多起來的話必定會成為性能瓶頸。
很明顯可以看得出來,原先的寫法需要與數據庫進行多次交互。而優化后的寫法只需要和數據庫交互一次。實際上我們可以在mapper文件中進行批量插入進行優化,這樣實際上通過批量插入的sql語句,從而實現服務與數據庫只交互一次就完成數據的批量保存。
先查數據再更新數據庫
在進行業務代碼編寫的時候,經常會碰到這樣的場景,如果數據庫中有數據則進行更新,如果沒有數據則直接插入。我們來看看下面這種寫法,先從數據庫中查詢數據,如果存在則進行更新,如果不存在則進行數據插入,有兩次數據庫交互操作。
實際上可以直接通過數據庫的sql進行控制,存在數據則進行更新,不存在則插入,這樣可以避免和數據庫的多次交互。
業務依賴技術細節
我們先來看下Robert C. Martin提出來的依賴倒置原則怎么描述的:
High-level modules should not depend on low-level modules. Both should depend on abstractions.
高層模塊不應該依賴于低層模塊,二者都應該依賴于抽象。
- Robert C. Martin
Abstractions should not depend on details. Details (concrete implementations) should depend on abstractions.
抽象不應該依賴于細節,細節應該依賴于抽象。
- Robert C. Martin
這兩句話聽上去有點不明覺厲,不如我們結合下具體的業務場景更好理解一點。假設在一個監控告警平臺中,如果線上平臺出現了問題,比如調用訂單生成接口失敗,無法生成訂單。平臺檢測到這樣的異常之后需要通知研發同學進行問題排查定位。此時監控告警平臺會將告警信息發送到釘釘群中進行通知。因此我們需要一個發送釘釘消息的接口,如下所示。
看上去代碼是沒什么問題的,有了告警就調用發送釘釘消息的接口方法。但是實際上這樣的寫法違反了依賴倒置的設計原則。為什么這么說,試想一下如果哪天公司決定不用釘釘接收告警信息,改用企業微信了或者是自己公司的通訊軟件。那么此處的sendDingTalk必定是要進行修改的,因為我們的告警通知業務依賴了具體的發送消息通知的實現細節,這明顯是不合理的。
因此此處比較好的做法是,定義一個notifyMessage的接口,具體的實現細節上層不必關心,無論是通過釘釘通知還是企業微信通知也好,只要實現這個通知的接口就OK了。即便后期進行切換,原來的業務邏輯并不需要進行修改,只要修改具體通知接口的實現就可以了。
長SQL
程序猿接手項目的時候,最怕遇到的就是項目中那些動不動上百行的長SQL。這些長SQL中有的存在各種嵌套查詢,甚至包含了三四層子查詢;有的包含了四五個left join,inner join連接了五六張表,這些長SQL一個電腦屏幕都裝不下,仿佛裝不下的還有寫這個長SQL的同學的“才華”。更無語的是如果寫這個SQL的同學已經離職了,你想問下大致的查詢邏輯都沒人可以問,即便是沒有離職,寫的人過了一段時間后再看這段SQL估計也挺費勁。
可能有的同學會說我也不想寫長SQL啊,奈何數據分散在各個表中,業務邏輯也比較復雜,所以只能各種join各種子查詢,不知不覺就寫了長SQL。但是實際上長SQL并不能解決上述數據分散業務復雜的問題,反而帶來了后期維護差等各種問題,長SQL表面上看是一個數據庫操作,但是在數據庫引擎層面還是將長SQL分成了多個子操作,各個子操作完成后再將結果數據進行統一返回。
那么如何避免寫出來這種維護性很差的長SQL呢?對于一些查詢場景比較多的長SQL可以嘗試使用大寬表來承載需要展示的各個字段數據,這樣頁面查詢的時候直接在大寬表上進行查詢,而不必再組合各個業務數據進行查詢,或者將又有的長SQL拆分成多個視圖以及存儲過程來簡化SQL的復雜性。
接口參數過多
這個問題在實際項目開發中經常遇到,當你需要調一個別人封裝好的接口的時候,對方突然丟過來一個方法包含了七八個參數。我想當時你的心情應該是想對他深深說一句真是栓Q你了。其實對于一個方法的參數來說,這里建議參數個數還是最多不要超過5個。
實際上我們可以用模型對象來進行參數封裝,這樣可以避免方法中參數個數過多導致后期維護困難。因為隨著業務的發展,有可能會出現修改接口能力來滿足新的需求,但是這個時候如果動接口參數的話,那么對應的接口以及實現類都需要修改,萬一有其他地方調用這個接口,那么修改的地方就會更多,很明顯這不符合OCP設計原則。因此這個時候如果使用的是一個對象作為方法的參數,那么無論是增加或者減少參數都只需要修改參數對象,并不需要修改對應方法的接口參數,這樣接口的擴展性會更加強一點。因此我們在寫代碼的時候不能光著眼于當下,還要考慮對應需求發生變化的時候,我的代碼怎么才能適應這種變化做到最小化修改,后期無論是自己維護還是別人的同學維護都會更加方便一點。
重復代碼
之前專門寫過關于如何消除系統重復的代碼的文章,具體可以參見如下:
如何優雅的消除系統重復代碼
常見代碼優化寫法
盡量復用工具函數
集合判斷
日常開發的時候我們經常遇到關于數據集合非空判斷的邏輯,常見的寫法如下,雖然沒什么問題但是看起來非常不順溜,簡單來說就是不夠直接,一眼望過去還得反應一下。
但是通過使用封裝好的工具類直接進行判斷,所看即所得,清楚明白表達集合檢查邏輯。
Boolean轉換
在一些場景下我們需要將Boolean值轉化為1或者0,因此常見如下代碼:
實際上可以借助于工具方法簡化為如下代碼:
lambda表達式簡化集合
集合最常見的場景就是進行數據過濾,篩選出符合條件的對象,代碼如下:
實際上我們可以利用lambda表達式進行代碼簡化:
Optional減少if判斷
假設我們要獲取任務的名稱,如果沒有則返回unDefined,傳統的寫法可能是這樣,包含了多個if判斷,看上去有點啰里啰唆不夠簡潔。
我們嘗試使用Optional進行代碼簡化優化之后,是不是看上去立馬簡潔很多了?
總結
本文主要和大家聊了聊日常工作中比較常見的奇葩代碼,當然吐槽并不是目的,研發同學能夠識別到奇葩代碼并進行優化,同時自己在實際開發工程中能夠盡量避免寫這些代碼才是真正的目的。不知道大家在工作中有沒有遇到過類似的奇葩代碼或者自己曾經寫過哪些現在回過頭來看比較奇葩的代碼,如果有的話歡迎大家在評論區一起討論交流哈 。