因為查詢沒有命中索引,數據庫直接被查崩了
大家都知道,數據庫中使用索引,進行檢索數據的話,那么就會大幅度的提升你的查詢效率,原本可能需要三秒甚至四秒左右的查詢SQL,增加索引之后,會可以能讓查詢速率至少提升百分之30,那么加索引怎么才能如何讓自己的查詢命中索引呢?又應該怎么去給自己的表結構建立索引呢?這才是阿粉想要講的事情。
索引失效
我們在日常開發的時候,很多時候都會在創建表完成之后,給這個對應的表建立上一個索引,而這個索引的定義呢,一般也是根據自己的業務需求來的,但是有些雖然根據自己的業務需求弄好了之后,發現有些查詢明明自己感覺都運用了索引,但是最終卻發現自己的索引失效了。
那么引發索引失效,都有哪些騷操作呢?
實際上就是七個字,模 型 數 空 運 最 快
模:模糊查詢的意思。like的模糊查詢以%開頭,索引失效。比如:
SELECT * FROM user? WHERE name LIKE '%極客技術';
型:代表數據類型。類型錯誤,如字段類型為varchar,where條件用number,索引也會失效。比如:
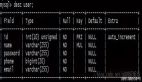
SELECT * FROM user WHERE height= 10;
height為varchar類型導致索引失效。
數:是函數的意思。對索引的字段使用內部函數,索引也會失效。這種情況下應該建立基于函數的索引。比如:
SELECT * FROM user WHERE DATE(create_time) = '2020-09-03';
create_time字段設置索引,那就無法使用函數,否則索引失效。
空:是Null的意思。索引不存儲空值,如果不限制索引列是not null,數據庫會認為索引列有可能存在空值,所以不會按照索引進行計算。比如:
SELECT * FROM user WHERE address IS NULL不走索引。
SELECT * FROM user WHERE address IS NOT NULL;走索引。
建議大家這設計字段的時候,如果沒有必要的要求必須為NULL,那么最好給個默認值空字符串,這可以解決很多后續的麻煩(切記)。
運:是運算的意思。對索引列進行(+,-,*,/,!, !=, <>)等運算,會導致索引失效。比如:
SELECT * FROM user WHERE age - 1 = 20;
最:是最左原則。在復合索引中索引列的順序至關重要。如果不是按照索引的最左列開始查找,則無法使用索引。
快:全表掃描更快的意思。如果數據庫預計使用全表掃描要比使用索引快,則不使用索引。
如何建立索引呢?
這個時候,如果面試官問你的時候,說,如何建立索引,就是建立索引的規范的時候,你應該怎么回答呢?
其實這就是問你,你在設計表的時候,怎么去設計表里面的索引比較合適呢?阿粉列出幾個:
1.經常與其他表進行連接的表,在連接字段上應該建立索引
也就是在關聯條件上面,建立索引,比如a.id = b.aid
a表的id,是主鍵,而這時候,我們就需要把b表的對應a表的id建立一個索引,這樣在使用關聯查詢的時候,能夠命中索引。
2.經常出現在Where子句中的字段,特別是大表的字段,應該建立索引
3.索引應該建在小字段上,對于大的文本字段甚至超長字段,不要建索引
4.頻繁進行數據操作的表,不要建立太多的索引
5.在經常需要排序的列上創建索引
6.為經常出現在關鍵字order by、group by、distinct后面的字段,建立索引。
哪些字段不適合去建立索引
這些字段是索引應該建立的在什么字段上,那么什么樣的表字段,不適合去建索引呢?
1.對于那些在查詢中很少使用或者參考的列不應該創建索引
2.不要在有大量相同取值的字段上,建立索引
3.當修改性能遠遠大于檢索性能時,不應該創建索引。這是因為,修改性能和檢索性能是互相矛盾的。當增加索引時,會提高檢索性能,但是會降低修改性能。當減少索引時,會提高修改性能,降低檢索性能。因此,當修改性能遠遠大于檢索性能時,不應該創建索引。
所以在我們創建表的時候,適當的索引能夠加快我們的查詢速度,不適當的索引,反而對我們的表,有害而無益。你學會了么?