換了個數據結構,一不小心把系統性能提升了10倍以上
?很多Java開發同學經常有一個疑惑,搞Java開發也需要懂算法嗎?本文咱們就來談談這個問題。
其實如果你開發一個非常復雜而且有挑戰的大型系統,那么必然會在系統中使用算法。同理,如果你可以將算法進行合理的優化,那么也可以將系統性能提升幾十倍!
空口無憑,下面用真實案例來進行說明。我們一起來看看Hadoop在部署了大規模的集群場景下,大量客戶端并發寫數據的時候,文件契約監控算法的性能優化。
Hadoop是世界上最復雜的基于Java開發的分布式系統,因此我們選用它來進行舉例。從它的算法優化對系統性能的提升,就可以看出算法對于Java程序員們開發系統的重要性。
先給大家來引入一個小的背景,假如多個客戶端同時要并發的寫Hadoop HDFS上的一個文件,大家覺得這個事兒能成嗎?
明顯不可以接受啊,兄弟們,HDFS上的文件是不允許并發的寫的,比如并發的追加一些數據什么的。
所以說,HDFS里有一個機制,叫做文件契約機制
也就是說,同一時間只能有一個客戶端獲取NameNode上面一個文件的契約,然后才可以寫入數據,此時其他客戶端嘗試獲取文件契約的時候,就獲取不到,只能干等著。通過這個機制就可以保證同一時間只有一個客戶端在寫一個文件。
在獲取到了文件契約之后,在寫文件的過程期間,那個客戶端需要開啟一個線程來不停的發送請求給NameNode進行文件續約,告訴NameNode:大哥,我這還在寫文件呢,你給我一直保留那個契約好嗎?
NameNode內部有一個專門的后臺線程負責監控各個契約的續約時間,如果某個契約很長時間沒續約了,此時就自動過期掉這個契約,讓別的客戶端來寫。
大家看下面的圖:
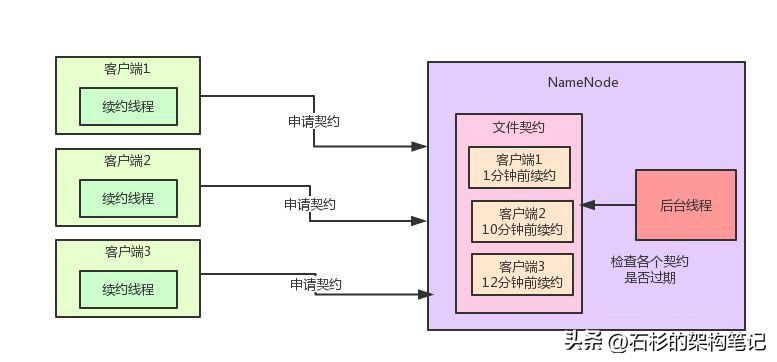
好,問題來了,假如我們有一個大規模部署到hadoop集群,同時存在的客戶端可能多達成千上萬個,此時NameNode內部維護的那個文件契約列表會非常非常的大。
而監控契約的后臺線程又需要每隔一段時間就檢查一下所有的契約是否過期,比如每隔幾秒鐘就遍歷大量的契約,那么勢必造成性能不佳,明顯這種契約監控機制是不適合大規模部署的hadoop集群的。
那Hadoop是如何對文件契約監控算法進行優化的呢?咱們一步一步看一下他的實現邏輯,先一起來看下圖:
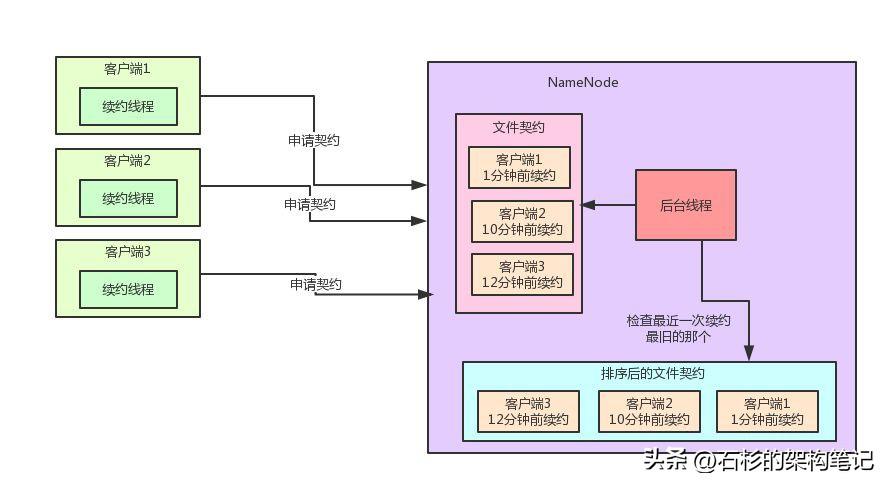
奧秘十分的簡單,每次一個客戶端發送續約請求之后,就設置這個契約的最近一次續約時間,然后基于一個TreeSet數據結構來根據最近一次續約時間對契約進行排序,每次都把續約時間最老的契約排在最前頭,這個排序后的契約數據結構十分的重要。
TreeSet是一種可排序的數據結構,他底層基于TreeMap來實現,而TreeMap底層基于紅黑樹來實現,可以保證元素沒有重復,同時還能按照我們自己定義的排序規則在你每次插入一個元素的時候來進行自定義的排序。
所以這里我們的排序規則,就是按照契約的最近一次續約時間來排序即可。
其實這個優化就是如此的簡單,就是維護這么一個排序數據結構而已。然后我們可以看一下Hadoop中的契約監控的源碼實現:
Lease leaseToCheck = null;
try {
leaseToCheck = sortedLeases.first();
} catch(NoSuchElementException e) {}
while(leaseToCheck != null) {
if (!leaseToCheck.expiredHardLimit()) {
break;
}
}
怎么樣?是不是不得不佩服那些寫出Hadoop、Spring Cloud等優秀開源項目的大牛的技術水平,大量的閱讀各種復雜而且優秀的開源項目的源碼,確實是可以快速的提升一個人的架構能力、技術能力和技術視野,這也是我平時花費大量時間做的事情。
每次檢查契約是否過期的時候,你不要遍歷成千上萬的契約,那樣遍歷效率很低下,完全可以就從TreeSet中獲取續約時間最老的那個契約
假如說連最近一次續約時間最老的那個契約都還沒過期,那么就不用繼續檢查了啊!因為說明續約時間更近的那些契約絕對不會過期!
舉個例子,續約時間最老的那個契約,最近一次續約的時間是10分鐘以前,但是我們判斷契約過期的限制是超過15分鐘不續約就過期那個契約。
這個時候連10分總以前續約的契約都沒有過期,那么那些8分鐘以前,5分鐘以前續約的契約,肯定也不會過期了,就是這個意思!
這個機制對性能的提升是相當有幫助的,因為正常來說,過期的契約肯定還是占少數,所以壓根兒不用每次都遍歷所有的契約來檢查是否過期,只要檢查續約時間最舊的那幾個契約就可以了。
如果一個契約過期了,那么就刪掉那個契約,然后再檢查第二舊的契約好了。以此類推。
通過這個TreeSet排序 + 優先檢查最舊契約的機制,有效的將大規模集群下的契約監控機制的性能提升至少10倍以上,這個思想,在我們自己進行系統設計時,是非常值得我們學習和借鑒的。
給大家引申一下,在Spring Cloud微服務架構中,Eureka作為注冊中心其實也有續約檢查的機制,跟Hadoop是類似的(不清楚的同學建議看一下:《SpringCloud精妙的設計,你還不知道?》)
但是在Eureka中就沒有實現類似的續約優化機制,而是暴力的每一輪都遍歷所有的服務實例的續約時間。
假如你是一個大規模部署的微服務系統呢?比如部署了幾十萬臺機器的大規模系統,有幾十萬個服務實例的續約信息駐留在Eureka的內存中,你難道要每隔幾秒鐘遍歷一下幾十萬個服務實例的續約信息嗎??