一次夜間接口超時的解決過程
背景
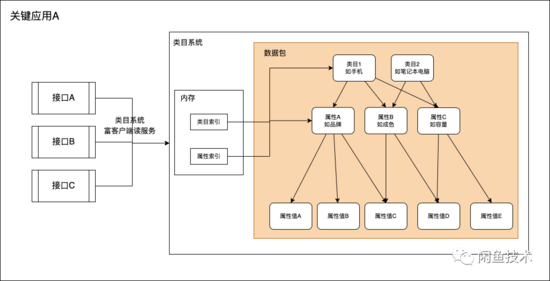
閑魚某關(guān)鍵應(yīng)用A依賴類目系統(tǒng)富客戶端(下文簡稱類目客戶端),旨在為閑魚商品域其他應(yīng)用提供各類商品類目及屬性數(shù)據(jù)(下文簡稱CPV數(shù)據(jù))查詢服務(wù)。
每天凌晨,該應(yīng)用所依賴的類目富客戶端執(zhí)行新老版本數(shù)據(jù)包切換時,應(yīng)用提供的服務(wù)抖動非常明顯,表現(xiàn)為大量接口超時(耗時100ms -> 3-5s),服務(wù)成功率明顯下降(100% -> ~92%),RPC線程池活躍線程數(shù)上漲(50 -> ~100),抖動最長可持續(xù)20s,影響到商品發(fā)布、商品詳情頁等依賴CPV數(shù)據(jù)的關(guān)鍵業(yè)務(wù)場景;且夜間發(fā)生抖動,時間點(diǎn)不固定,抖動發(fā)生時開發(fā)同學(xué)也難以關(guān)注到,影響面較為不可控,因此需要排查并徹底解決此問題。
排查過程
其實(shí)這是一個表象很簡單,但是根因藏得比較深的問題,筆者在排查過程中也走了一些彎路,也一并寫出來供讀者作為前車之鑒的參考。
堆空間不夠?
結(jié)構(gòu)化應(yīng)用線上原先使用的是4C8G的標(biāo)準(zhǔn)規(guī)格容器,分配4G內(nèi)存作為堆內(nèi)存,截取部分JVM啟動參數(shù)如下:
-Xms4g -Xmx4g -XX:MetaspaceSize=512m -XX:MaxMetaspaceSize=512m -XX:+UnlockExperimentalVMOptions -XX:G1MaxNewSizePercent=65 -XX:+UseG1GC -XX:InitiatingHeapOccupancyPercent=55 -XX:G1HeapRegionSize=16m -XX:G1NewSizePercent=25 -XX:MaxGCPauseMillis=120 -XX:+ParallelRefProcEnabled -XX:MaxDirectMemorySize=1g -XX:+TraceG1HObjAllocation -XX:ReservedCodeCacheSize=512m -XX:+UseCodeCacheFlushing
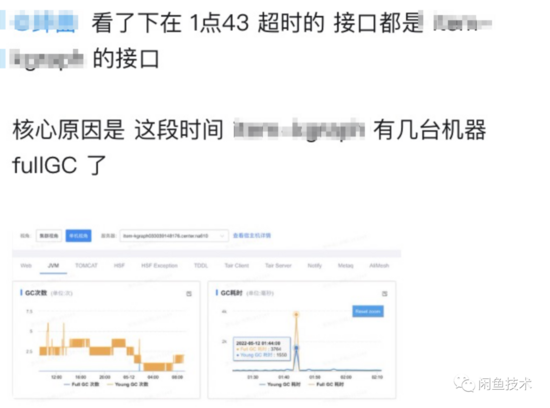
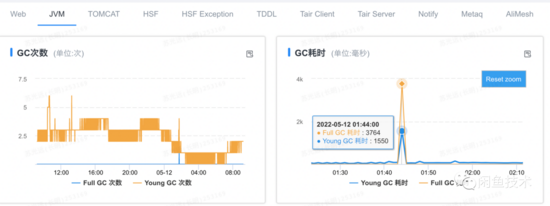
據(jù)反饋接口抖動的同學(xué)描述,在接口抖動的時間點(diǎn),請求失敗的機(jī)器發(fā)生了FGC。
undefined
由于本人先前在排查類似的FGC問題時,經(jīng)常能在Heap Dump的支配樹中看到類目客戶端相關(guān)對象長期占據(jù)高位,是內(nèi)存占用大戶。所以難免主觀印象先入為主,初步以為是切換版本的過程中,在老版本數(shù)據(jù)包卸載之前,可能會存在短暫的堆內(nèi)空間占用double的情況。
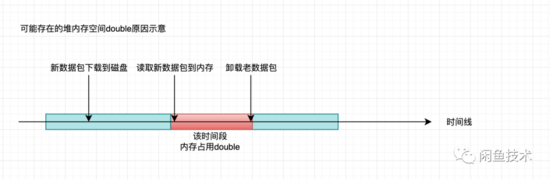
而啟動參數(shù)配置Eden區(qū)下限為25%。可能存在 老年代常駐占用 + 新數(shù)據(jù)包 > 4G 的情況引發(fā)FGC。
因此覺得 既然空間占用double不可避免,老年代常駐的堆空間短時間內(nèi)又不可能顯著下降,Eden區(qū)為了解決之前該應(yīng)用發(fā)生Mixed GC時Eden區(qū)反常縮小導(dǎo)致YGC異常,又必須固定一個下限值,那只能是把容器內(nèi)存規(guī)格擴(kuò)大看看能否緩解 。
于是將應(yīng)用容器基線升級到4C16G,設(shè)置在16G容器環(huán)境下,分配10G內(nèi)存給堆空間,并逐步升級線上服務(wù)的容器規(guī)格。
結(jié)果花了兩天時間,升級了線上大部分的容器后,查看監(jiān)控,發(fā)現(xiàn)大規(guī)格的容器確實(shí)沒有FGC了,且得益于超大的堆內(nèi)存(10G),從GC監(jiān)控上看甚至看不出有切包的動作。但是,RPC成功率還是會下跌(100% -> 97%),且RPC線程池線程數(shù)還是有少量上漲(50 -> ~71)。
由此可見,F(xiàn)GC并不是切包抖動的核心成因,背后還有更加深層次的原因需要挖掘。
容器CPU高觸發(fā)自適應(yīng)限流?
再次詢問受影響的業(yè)務(wù)方,通過下游應(yīng)用的日志發(fā)現(xiàn)推包抖動的時間點(diǎn),發(fā)生了不少sentinel限流日志。而結(jié)構(gòu)化應(yīng)用里面并沒有針對接口主動配置限流,只有集團(tuán)內(nèi)的sentinel中間件,可能因?yàn)闄z測到某一時間點(diǎn)CPU利用率過高(超過80%),自動執(zhí)行限流策略。
sentinel為集團(tuán)內(nèi)的流控中間件,能夠以流量為切入點(diǎn),從限流、流量整形、熔斷降級、系統(tǒng)自適應(yīng)保護(hù)、熱點(diǎn)防護(hù)等多個維度來幫助業(yè)務(wù)保障微服務(wù)的穩(wěn)定性。
登陸發(fā)生限流的服務(wù)Provider對應(yīng)機(jī)器,確實(shí)看到了限流日志。
$cat cpu-sampling.log.1 | grep "2022-05-19 03:57" | grep -v "0.0"
2022-05-19 03:57:12.435|||應(yīng)用名|CpuSampling|0||4.151785714285714|1.0|6
可以看到在當(dāng)前時刻,CPU利用率來到了 415%,可見確實(shí)在該時間點(diǎn)存在CPU四核全打滿的現(xiàn)象。
但是從應(yīng)用監(jiān)控來看,該時刻機(jī)器CPU利用率只有20%多(100%為單位)。且sentinel的cpu-sampling日志只grep出來一條CPU打滿的日志。按照限流中間件20ms采樣一次CPU的頻率,說明這只是一個CPU尖刺,不應(yīng)該有大面積的影響。筆者對限流導(dǎo)致RPC成功率下跌其實(shí)是抱有些許懷疑態(tài)度的,覺得應(yīng)該不是這樣的問題。
不管怎么說,最簡單的驗(yàn)證方法,就是線上找一臺 已經(jīng)換了16G內(nèi)存的機(jī)器 ,把sentinel中間件設(shè)置為:只記錄日志,不執(zhí)行實(shí)際限流動作的dry run模式。看接口成功率是否會跌。按照上面的推理,CPU尖刺最長不會超過40ms,就算CPU打滿40ms,也不至于導(dǎo)致接口有幾秒鐘的超時。
結(jié)果到了當(dāng)天晚上,接口成功率還是掉下來,存在接口幾秒鐘的超時。
源碼窺密,探究類目客戶端切包過程中具體動作
發(fā)現(xiàn)單純的提升容器規(guī)格并不能解決切包抖動的問題后,筆者復(fù)盤了一下手頭上已經(jīng)掌握的線索:
1. FGC不是引起切包抖動的核心原因,這是升級容器,花了錢之后得到的結(jié)論。那么,如果不花這個錢,我們能不能單純從監(jiān)控上得出結(jié)論?其實(shí)是可以的。如果目前線上容器規(guī)格完全不能滿足切包所需的內(nèi)存消耗,理論上集群每臺機(jī)器切包的時候都會FGC,但是實(shí)際上切包過程中全集群產(chǎn)生的FGC量并不算多,最多在20次左右,且只有1/6的機(jī)器發(fā)生FGC,剩下的機(jī)器也只是YGC略微上漲,然后很快恢復(fù)到正常水位。而即使是YGC量上漲,也只是分鐘YGC耗時從70ms漲到200ms,根本不至于把大量接口打到超時的。
2. sentinel檢測到CPU尖刺,自動執(zhí)行了限流,確實(shí)會拉低服務(wù)成功率。但即使把限流關(guān)閉,接口還會存在幾秒鐘超時,說明限流不是造成接口成功率下跌的主要原因。
3. 類目客戶端到底把類目數(shù)據(jù)存在磁盤,還是存在堆里面,亦或者是在堆外內(nèi)存,四處問了一圈,各有各的說法。 然而,不同的存儲方式可能最終會導(dǎo)向完全不同的結(jié)論。為了搞清楚這個問題,最精確的方法就是去把類目客戶端切包的源碼讀一遍。于是筆者花了點(diǎn)時間,
類目服務(wù)切包流程
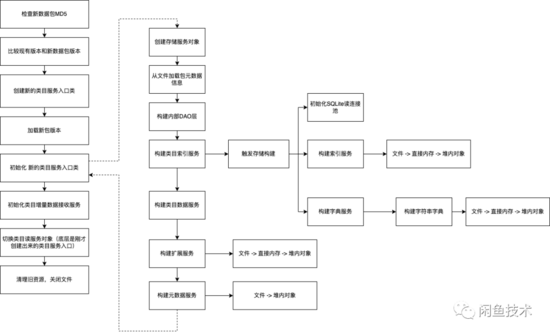
縱觀整個切包過程,都是在類目客戶端自帶的netty ChannelHandler回調(diào)線程中 單線程執(zhí)行 完成的,沒有任何多線程并行加載的動作。在初始化類目服務(wù)入口的時候,雖然有不少構(gòu)建索引之類的看起來重計算的動作,但是由于底層是單線程執(zhí)行,理論上CPU最多打到100%(一個核心),不會有打到400%的情況出現(xiàn)。凌晨結(jié)構(gòu)化應(yīng)用的業(yè)務(wù)CPU占用率很低,不到10%,理論上切包+業(yè)務(wù)不至于導(dǎo)致CPU打滿。更不太可能引起長達(dá)幾秒鐘的服務(wù)不響應(yīng)現(xiàn)象。
隨著進(jìn)一步梳理切包和錯誤發(fā)生的時間點(diǎn)、日志信息,一個更奇怪的現(xiàn)象浮出水面。
反常現(xiàn)象:切包完畢后接口開始超時
觀察以下全鏈路日志:
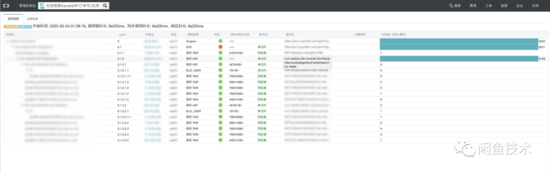
com.taobao.idle.modulet.ItemKgraphServiceApi@getSpuPublishSearchV3~SMM 接口有長達(dá)8s的超時。注意這個錯誤的發(fā)生時間 2022-05-24 01:38:19.523 。
平時這個接口RT在400m左右,底層是 使用線程池并行轉(zhuǎn)調(diào)各種搜索服務(wù) ,設(shè)置了1s的總體超時時間,大量try catch包裹,基本不會報錯。
再看這個時間點(diǎn)附近的類目樹日志:
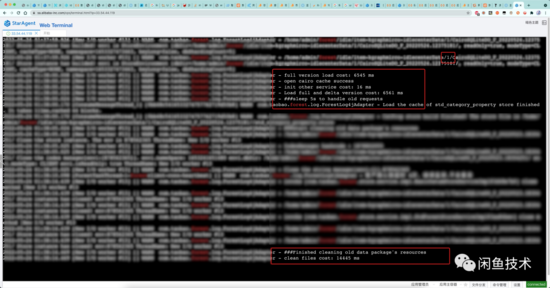
可以看到, 01:38:00 的時候,類目數(shù)據(jù)就已經(jīng)切換完了。01:38:14的時候,更是連舊文件都刪完了。切包已經(jīng)結(jié)束了。
然而,到了 01:38:27 的時候,類目服務(wù)的其中一個Logger, 從 kGraphCommonFixedThreadFactory-10-thread-95 線程打印出兩行日志:
2022-05-24 01:38:27.715 [kGraphCommonFixedThreadFactory-10-thread-95] [] WARN 類目服務(wù)Logger - Load the cache of std_category_property_value store finished. It takes 7820ms,cached 278 blocks.
2022-05-24 01:38:31.236 [kGraphCommonFixedThreadFactory-10-thread-95] [] WARN 類目服務(wù)Logger - Load the cache of std_category_property_value store finished. It takes 11341ms,cached 109 blocks.
而這個線程池,正是運(yùn)行 getSpuPublishSearchV3 接口底層轉(zhuǎn)調(diào)各種搜索的執(zhí)行線程,且代碼為異步執(zhí)行的Future設(shè)置了1s超時,如果執(zhí)行超過一秒,接口服務(wù)的代碼也不會繼續(xù)等待,而是直接往下執(zhí)行了。
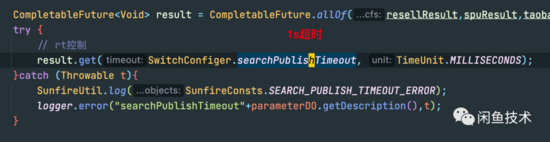
更巧的是:從01:38:19到01:38:27,整整8秒,恰好和上面監(jiān)控的超時對的上。看到這里,問題似乎變得更加復(fù)雜。
- 1. 剛剛我們才提到,切包是在類目客戶端的netty ChannelHandler線程里進(jìn)行,怎么現(xiàn)在又跑到了業(yè)務(wù)線程池上,甚至能Hang住了接口?
- 2. 為什么類目服務(wù)都都跑在別的線程池上面了,且線程池超時設(shè)置1s了,為什么接口還會有8s的超時?
撥云見霧,逐個擊破
其實(shí)回答問題1不難。因?yàn)槿罩疽呀?jīng)打出來了,只需要全局搜 Load the cache of ,就能找到唯一一個類目樹打日志的地方,再往上倒著找調(diào)用棧。會發(fā)現(xiàn) 類目屬性 和 類目屬性值 這兩個存儲是懶加載的。只有切完包之后,第一次請求讀取類目的屬性及屬性值,才會觸發(fā) 通過mmap的方式將store文件映射到Java進(jìn)程的一段連續(xù)虛擬地址,并把數(shù)據(jù)從磁盤讀上內(nèi)存的動作。
核心代碼:
MappedByteBuffer mappedBuffer = storeFile.getFileChannel().map(MapMode.READ_ONLY, segmentPosition, segmentSize); // 創(chuàng)建mmap映射
mappedBuffer.load(); // 把數(shù)據(jù)讀上內(nèi)存
Buffer buffer = FixedByteBuffer.wrap(mappedBuffer);
this.bufferCacheArray[t] = new BufferCache(buffer, ((t == 0) ? meta.getHeaderSize() : 0), blockCountThisSegment, meta.getBlockSize());
for (int i = ((t == 0) ? 0 : blockIdFlags[t - 1]); i < blockIdFlags[t]; i++) {
getReadBlock(i); // 提前創(chuàng)建 blockId -> block buffer的映射
}
因此,加載完成后的日志自然是在業(yè)務(wù)線程池打的。
Page Fault的“威力”
問題2就不好回答了。因?yàn)橛幸粋€十分明顯的矛盾點(diǎn): 本次Store加載是在業(yè)務(wù)線程池加載,對所有Future都只等待1s,1s加載不完立刻就返回了,不可能有8s的耗時。而且機(jī)器已經(jīng)是16G容器,又沒有FGC導(dǎo)致的STW。 那就只有進(jìn)程級別的hang會影響到多個線程了。
為了確認(rèn)是否存在進(jìn)程hang,筆者再次去看自適應(yīng)的cpu-sampling日志。不看不知道,一看嚇一跳:

20ms采樣一次CPU并打日志的線程也被hang住了!整整到了01:38:27才恢復(fù)日志打印。而這段時間正好是store在load的時間,也和接口超時時間吻合
那基本只有一種可能,那就是 第一次讀取mmap映射虛擬地址段的數(shù)據(jù)時,因?yàn)閿?shù)據(jù)在硬盤里,還沒在內(nèi)存上,會觸發(fā)page fault,使得JVM進(jìn)程陷入內(nèi)核態(tài),執(zhí)行從磁盤加載數(shù)據(jù)到內(nèi)存的page fault handler,導(dǎo)致進(jìn)程掛起直到回到用戶態(tài) 。
參考 《Understanding the Linux kernel》一書 9.4.2 節(jié) Handling a Faulty Address Inside the Address Space。其中有一段話是這么寫的:
The handle_mm_fault( ) function returns VM_FAULT_MINOR or VM_FAULT_MAJOR if it succeeded in allocating a new page frame for the process. The value VM_FAULT_MINOR indicates that the Page Fault has been handled without blocking the current process; this kind of Page Fault is called minor fault.
The value VM_FAULT_MAJOR indicates that the Page Fault forced the current process to sleep (most likely because time was spent while filling the page frame assigned to the process with data read from disk); a Page Fault of the current process is called a major fault.
The function can also return VM_FAULT_OOM (for not enough memory) or VM_FAULT_SIGBUS (for every other error).
關(guān)注加粗的部分,在處理內(nèi)存page fault事件時,如果出現(xiàn)了Major Page fault,那么這種Page fault會強(qiáng)制使得當(dāng)前進(jìn)程休眠(基本上發(fā)生在在需要把數(shù)據(jù)從磁盤讀到進(jìn)程地址空間內(nèi)的頁塊這種耗時場景下)。
再看 MappedByteBuffer#load() 方法Javadoc:
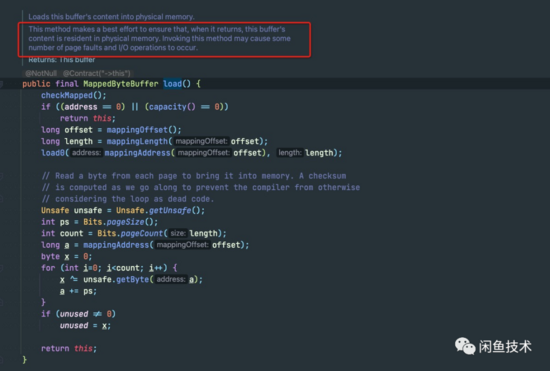
可以看到,Javadoc上寫明:Invoking this method may cause some number of page faults and I/O operations to occur.調(diào)用這個方法很可能會產(chǎn)生一些page fault。
那么,只要確認(rèn)在load store的過程中,JVM進(jìn)程產(chǎn)生了大量的Major Page Fault, 就能解釋清楚為什么會出現(xiàn)跨多線程Hang的的情況了。
這里筆者主要使用兩個命令: pmap? 和 sar 。
pmap能夠展示進(jìn)程的所有連續(xù)地址空間,通過查看地址空間的文件引用情況,以及RSS列的值,可以表明當(dāng)前連續(xù)內(nèi)存空間中有多少個頁面被進(jìn)程引用。
在日常機(jī)器上復(fù)現(xiàn)場景,可以看到,在執(zhí)行l(wèi)oad store方法之前,當(dāng)前進(jìn)程沒有引用到任何有關(guān)類目文件的虛擬地址空間。

調(diào)用查詢屬性及屬性值的方法后,可以看到
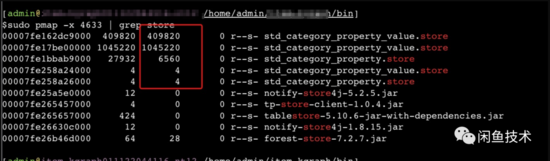
類目樹的屬性、屬性值store被加載上來,且RSS值 == KBytes,說明整個文件都被讀到了內(nèi)存里。
還有一個重要的抓手是 sar? 命令。 sar 命令可以以指定的采樣率去采樣當(dāng)前整個操作系統(tǒng)的Page Fault發(fā)生指標(biāo)。
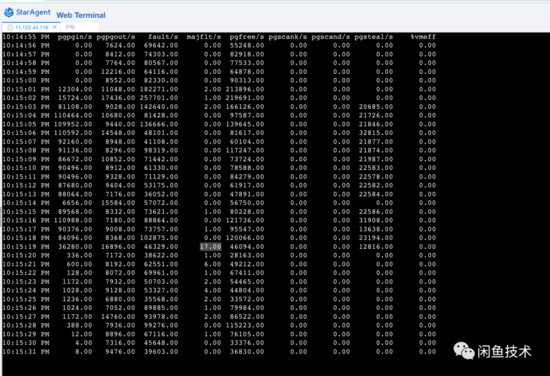
可以看到,initCache過程中,觸發(fā)了大量的major page fault,同時筆者連接到服務(wù)器上的Arthas命令行也hang死無任何反應(yīng)。進(jìn)一步驗(yàn)證了上述情況。
Arthas的命令行底層是termd庫,純Java實(shí)現(xiàn)。而Arthas又是以java agent的形式附加到目標(biāo)JVM上的,如果連Arthas的控制臺輸入命令都沒有回顯了,基本上只有JVM進(jìn)程整體Hang死一種可能,該現(xiàn)象也進(jìn)一步驗(yàn)證了上文提及的進(jìn)程陷入內(nèi)核態(tài)Hang死的假設(shè)。
那為什么會hang住好幾秒的時間?通過測量線上容器的IO速度,發(fā)現(xiàn)容器的磁盤讀寫速度在100MB左右,而類目屬性值的store文件非常大,達(dá)到1.7G。加載一遍這個文件非常耗時。
至此,我們終于可以給出結(jié)論。
結(jié)論
結(jié)構(gòu)化應(yīng)用夜間類目客戶端推包完成新老數(shù)據(jù)包版本切換后,存儲類目屬性及屬性值的數(shù)據(jù)不會立即加載到內(nèi)存。會等到第一個查詢類目屬性、屬性值的請求到來才會懶加載數(shù)據(jù)到內(nèi)存。由于類目屬性值store非常大,達(dá)到1.7個G。在把1.7G數(shù)據(jù)整體加載到內(nèi)存的過程中觸發(fā)大量Major Page Fault,導(dǎo)致進(jìn)程進(jìn)入內(nèi)核態(tài)處理缺頁異常。而由于業(yè)務(wù)容器IO性能較差,完整讀取文件十分耗時,最終導(dǎo)致Java進(jìn)程hang住十幾秒的現(xiàn)象。
最終解法
帶著問題去咨詢類目服務(wù)相關(guān)同學(xué),他們給出的建議是升級到最新版本的客戶端。筆者對比了新老版本客戶端的代碼,主要有兩處改進(jìn)。
1. 在切包之前,會去load一把store,而不是等到請求進(jìn)來再懶加載。
2. load store的時候,不是一口氣load整個文件,而是把文件切分為64M的小塊,每次load 64M,然后sleep一會。再繼續(xù)load下一塊,避免一次性load超大文件塊導(dǎo)致進(jìn)程長時間處于內(nèi)核態(tài)無法對外提供服務(wù)。
回過頭來思考一些前文提出的問題。既然接口超時是主要是加載大文件引起的,那升16G容器還有必要嗎?
筆者認(rèn)為還是有必要的。原因有兩點(diǎn)
1. 現(xiàn)在新版的類目客戶端會在切版本、釋放老包資源(包括虛擬地址空間)之前先load一把store,雖然store在堆外內(nèi)存,但是仍然需要占用進(jìn)程的地址空間,而且實(shí)際上還是需要把數(shù)據(jù)讀上內(nèi)存。因此在切包過程中,從整個Java進(jìn)程視角來看,確實(shí)是會產(chǎn)生double的store空間占用。而目前一個類目store就要1.7G了,兩份就是3.4G。還有4G的空間劃分給了JVM的堆。剩下不到1G的內(nèi)存空間,8G容器內(nèi)存非常吃緊,很容易在切包過程中,load新store的時候產(chǎn)生容器OOM導(dǎo)致容器被殺。
2. 雖然store數(shù)據(jù)都是存在堆外的,但是store的一些索引對象和元數(shù)據(jù)還是存在堆里面的,大約占用堆6-700M空間。而無論是新版還是舊版的類目客戶端,索引都是在切包之前build的。因此在構(gòu)建新包索引的時候,峰值也會產(chǎn)生2倍的 堆內(nèi)空間占用 ,很容易堆內(nèi)存不足產(chǎn)生YGC甚至FGC。
總結(jié)
一個看上去表象非常像GC引起的接口超時,底層卻隱藏著更深層次的原因。通過這個案例,也提醒我們,作為技術(shù)人,遇到問題,無論表象多么明顯,和之前遇到過的場景多么相似,都需要避免被所謂經(jīng)驗(yàn)蒙蔽雙眼、先入為主的壞習(xí)慣。大膽推斷,小心論證。多問一些為什么,才能一步一步的接近真相。